| #RF |
|
ㆍSession 19 / Power Amplifiers and BuildingBlocks
|
|
이번 ISSCC 2022의 Session 19는 RF power amplifier and building blocks 라는 주제로 총 7편의 논문이 발표되었다. 주파수 영역대로는 크게 100GHz 근처의 sub-THz 영역, 28GHz 또는 37GHz 근처의 5G mm-Wave 영역, 5GHz 근처의 Wi-Fi 영역대를 타켓으로 주로 설계되었다. 또한 대부분의 설계들은 높은 출력전력을 내보내면서도 최대 출력과 back-off 출력 영역에서 높은 효율 얻고자 하는 것에 중점을 두었다.
|
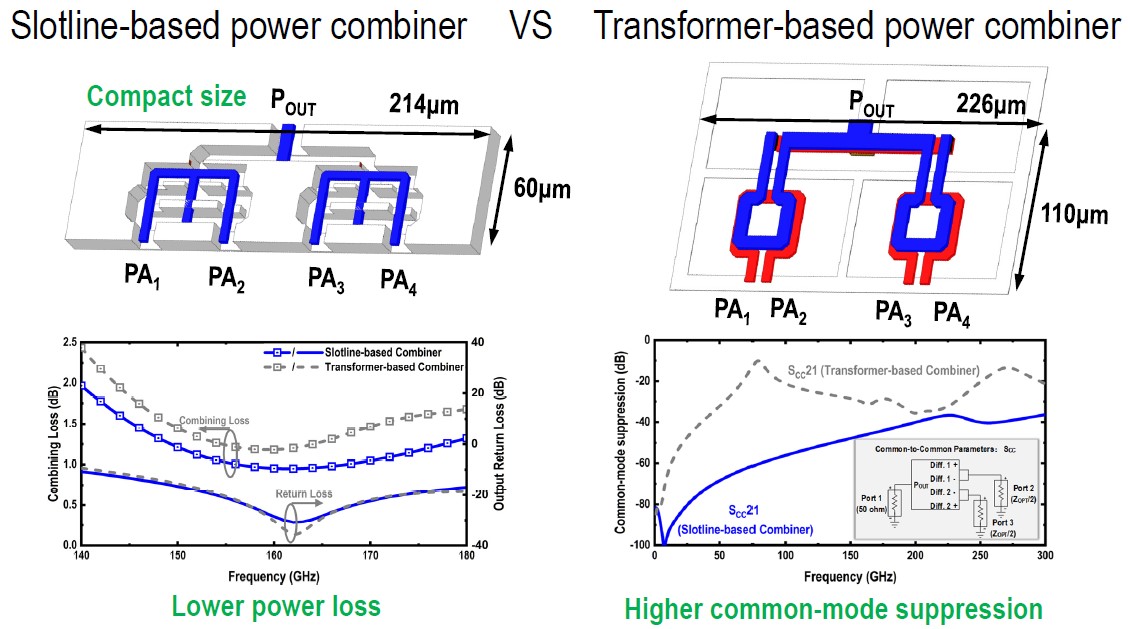 |
| [그림 1] #19.1에 소개된 slotline-based 및 transformer-based power combiner 비교 |
|
#19.1 은 칭화대에서 발표한 논문으로, sub-THz 의 D-band (110-170 GHz) 를 타겟팅하는 110-130 GHz SiGe BiCMOS Doherty power amplifier 를 설계한 것이다. 기존의 silicon 을 이용한 transformer 기반의 sub-THz power combiner의 경우 큰 손실로 인해, 출력 Pout이 제한되거나 peak 또는 back-off 효율이 크게 제한되고 있다. 본 논문에서는 slotline 기반의 8-way power combiner를 제안함으로써 손실을 크게 낮출 수 있었고, 이는 기존의 transformer를 대체할 수 있는 실용적인 방식임을 보여줄 수 있었다. 제안한 방식을 통해 D-band에서 saturation power 가 22dBm 이상을 높은 값을 보였으며, 6-dB power back-off 영역에서 10% 이상의 효율을 나타내었다.
#19.2 는 칭화대에서 발표한 논문으로, W-band (75-110 GHz) 를 타켓팅하는 CMOS 공정을 이용한 92-102 GHz power amplifier 를 설계한 것이다. 기존 silicon 기반의 설계는 낮은 breakdown 전압으로 큰 전력을 구동하는 데에 한계가 있다. 본 논문에서는 128-to-1 power combiner 를 제안함으로써, 16개의 8-way sub-PA 배열(총 128개)을 단일 출력으로 50옴을 구동하였고, saturation power가 32.1dBm으로 CMOS 기반의 방식 중 가장 큰 전력 구동능력을 보여주었다.
|
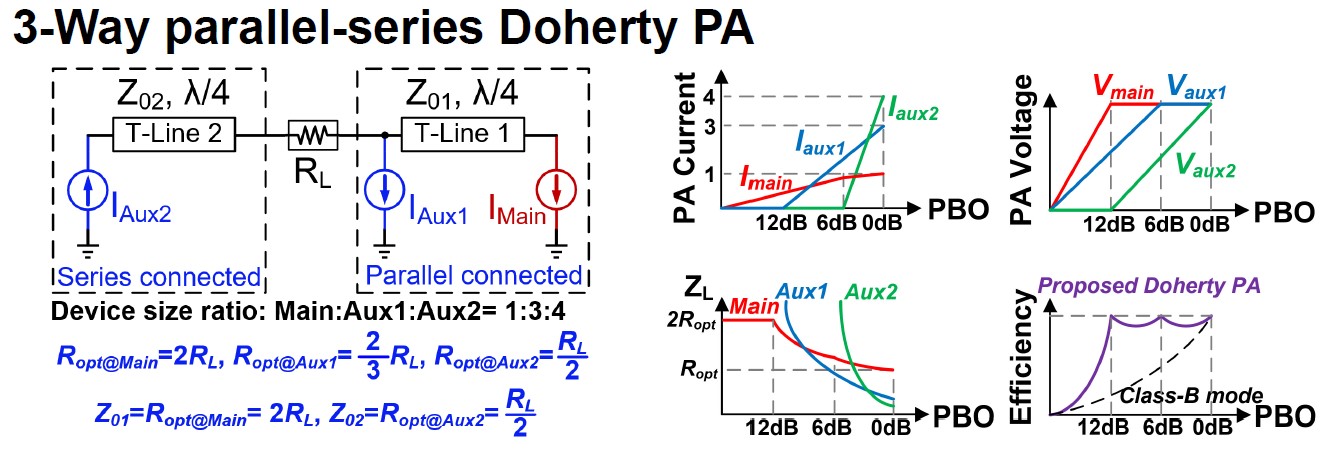 |
| [그림 2] #19.3에 소개된 3-Way parallel-series Doherty PA |
|
#19.3 는 Tianjin 대학에서 발표한 논문으로, 5G를 타겟팅하는 28 GHz Doherty power amplifier 를 설계한 것이다. 통신 규격이 더 큰 peak-to-average power ratio (PAPR)를 보임에 따라, power back-off 영역에서의 효율 개선이 필수적이다. 본 논문은 transformer 기반의 새로운 3-way parallel-series Doherty PA 방식을 제안함으로써, 높은 출력 전력과 back-off 영역에서의 효율 개선을 이루었다. 또한 PMOS varactor 를 이용하여, 추가적인 효율 개선을 보였다. 최고 출력전력은 25.5 dBm, PAE는 25.2%를 보였으며, -6dB PBO는 20.4%를 나타내었다.
#19.4 는 Georgia Tech에서 발표한 논문으로, 5G를 타겟팅하는 bi-directional PA/LNA를 설계한 것이다. 기존의 bi-directional amplifier의 경우 T/R switch의 사용으로 큰 면적을 요구하였으나, 본 논문은 T/R switch를 필요로 하지 않는 bi-directional core 구조를 설계하였다. 또한 기존의 NMOS 기반의 bi-directional 형태와 달리 hybrid N/PMOS bi-directional 형태를 제안함으로써, 기존의 구조 대비 높은 출력 전력과 효율을 나타내었다.
|
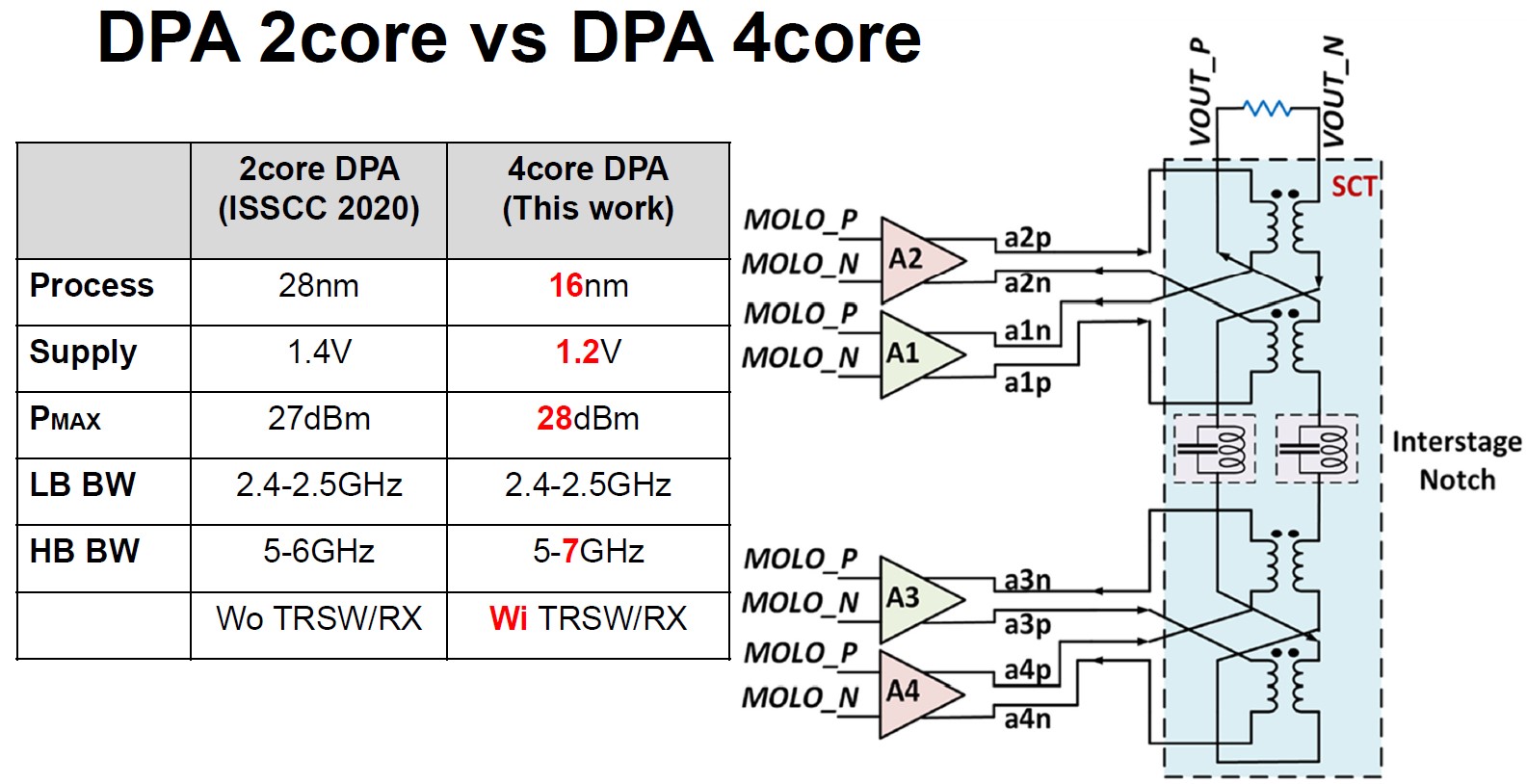 |
| [그림 3] #19.5에 소개된 4core DPA 구조
|
|
#19.5 는 인텔에서 발표한 논문으로, Wi-Fi6E를 타겟팅하는 all digital polar transmitter를 설계한 것이다. 본 논문은 16nm FinFET 공정을 이용한 설계로 낮은 전원전압에서 높은 출력전력과 reliability 문제를 해결하고자 하였다. 2020년 ISSCC에서 발표한 인텔 논문에서는 1.4V 전원의 2 core DPA를 사용하였으나, 올해는 1.2V 전원의 4 core DPA 구조를 제안함으로써, 더 낮은 전원전압에도 불구하고 더 높은 출력 전력으로 구동할 수 있게 해 주었다. 또한 각 DPA 셀에 floating VSS 구조를 도입함으로써 PMOS의 높은 bias 전압이 인가되는 것을 방지해 주었고, 이를 통해 16nm FinFET 공정에서도 reliability를 높여주었다.
|
| #RF |
|
ㆍSession 8 / Advanced RF Building Blocks
ㆍSession 27 / mm-Wave & Sub-6GHz and Receivers and Transceivers for 5G Radios
|
|
Session 8 은 Advanced RF 블록에 대한 세션으로 총 3편의 논문으로 구성되어 있다.
#8-1 논문은 positive-feedback 이용한 노이지 상쇄 LNA 블록에 대해 다룬다. 논문에서는 auxiliary path 에서 일정 전력 소모를 필요로 하는 기존 노이즈 상쇄 기법 대신 feedforward path 를 활용한 positive feedback 과 gm-boosting 기법을 적용하여 노이즈 상쇄와 전류 감소효과를 동시에 구현했다는 점에서 주목할 만하다. 0.25~3GHz 주파수 영역에서 3.4 mW (1V) 전력 소모와 함께 CG 구조에서 2.7 dB NF 보여준다.
#8-2 는 미국 인텔 사에서 발표한 논문으로 voltage-interpolator 기반 fractional-N type-I sampling PLL 설계를 소개한다. 제안된 PLL 구조에서 voltage interpolation (VI) 기술을 적용하여 기존 필요로 하는 digital-to-time converter 를 제거함으로써 노이즈와 fractional frequency-synthesis resolution 성능을 향상시켰다. 22-nm FinFET CMOS 로 구현된 PLL 에서 ΔΣ-VI 활성화 시, fractional spur 및 integrated rms jitter 특성이 각각 -48dBc 와 0.9ps 으로 개선됨을 보여준다.
#8-3 은 ADPLL 를 활용한 9-12 GHz 대역 FMCW modulator 에 대한 논문으로 아날로그 디바이스에서 발표한 논문이다. 기 발표된 RTWO 기반 ADPLL을 확장하여 64-phase 4-ring RTWO 기반 dividerless ADPLL 을 구현하여 setting time 성능 개선하였다. 실제 구현된 설계에서 80~200 MHz reference 주파수에서 낮은 phase noise (<-121 dBc/Hz) 유지한 채 sawtooth chirp retrace time 과 settling time 이 각각 12.5ns 와 2us 를 얻었다는 점에서 인상적이다.
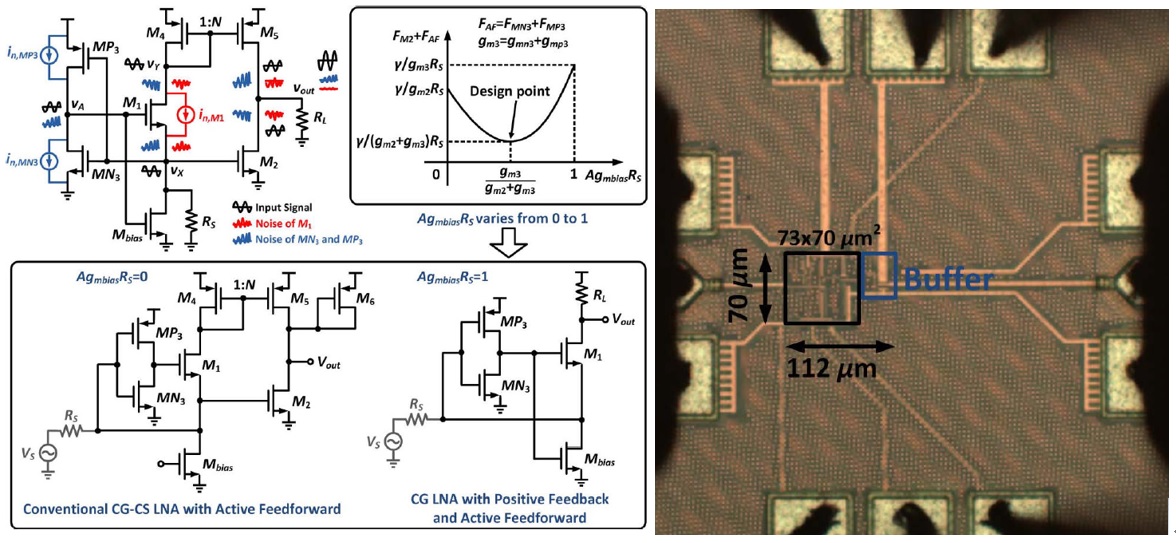 |
| [그림 1] #8-1 positive-feedback 구조를 적용한 Noise cancelling LNA
|
Session 27 은 총 industry 에서 3편, academia 에서 2편으로 총 5편의 논문으로 구성되어 있으며, 5G를 위한 mmWave 와 Sub-6GHz 를 지원하는 전체 transceiver 및 receiver 를 주로 다루고 있다.
#27.1 은 삼성전자 산호세에서 발표한 논문으로 mm-Wave 대역 dual-band (24.25~29.5 GHz, 37~40 GHz) 를 지원하는 beamforming IC (BFIC) 와 quad-stream 16 channel 을 지원하는 intermediate frequency IC (IFIC) 를 소개하고 있다. 주목할 사항은 BFIC 에서 하나의 RFPLL 과 1.5x frequency multiplier, wideband mixer 로 dual-band 구현이 가능하도록 구현했다는 점이다. 기존 mmWave transceiver IC 와 비교 시 동등 성능으로 30% area 로 개발하였다.
#27-2 은 IBM T.J. Watson 연구소에서 발표한 논문으로, 5G 24-60GHz 대역의 256-element dual-polarized 위상 배열 구조를 제안하였다. SiGe BiCMOS 공정으로 설계된 독립적인 8개 BFIC, 1개 frequency conversion IC, 2개의 BPF, 2 combiner/splitter 이루어진 64 element module 을 4개 이용하여 256-element dual-polarized 위상 배열을 구현하였다. 이 때, 문제시 되는 좁은 빔 패턴에 의한 커버리지 이슈를 on-chip digital beam calculator 를 통한 30,000 이상 빔 커버리지가 가능한 fast beam-switching switch 기술을 적용하였다.
#27-2 은 IBM T.J. Watson 연구소에서 발표한 논문으로, 5G 24-60GHz 대역의 256-element dual-polarized 위상 배열 구조를 제안하였다. SiGe BiCMOS 공정으로 설계된 독립적인 8개 BFIC, 1개 frequency conversion IC, 2개의 BPF, 2 combiner/splitter 이루어진 64 element module 을 4개 이용하여 256-element dual-polarized 위상 배열을 구현하였다. 이 때, 문제시 되는 좁은 빔 패턴에 의한 커버리지 이슈를 on-chip digital beam calculator 를 통한 30,000 이상 빔 커버리지가 가능한 fast beam-switching switch 기술을 적용하였다.
#27-3 논문은 싱가폴 난양공대에서 발표한 5GHz 수신기에 관한 논문으로 고선형 특성을 구현하기 위해 첫단에 하이브리드 커플러가 적용된 구조를 보여준다. 하지만, LNA 가 없는 수신기 노이즈 성능 저하의 구조적 한계를 제안된 RLC 기반 노이즈 상쇄 기법을 통해 해결하고자 하였다. Voltage mode 와 current mode 에서 NF/IIP3 성능이 각각 1.7dB/-8dBm 과 5.3dB/10.5dBm 으르 보여준다.
#27-4 는 Tokyo Tech 에 발표한 5G FR2 용 위상 배열 수신기 관련 논문으로 지금껏 발표된 위상 배열 중 가장 넓은 24-71 GHz 대역 동작 성능을 보여주는 것에 주목할만하다. 실질적으로 광대역 주파수를 구현하기 위해 LNA 는 2개 주파수 대역 (24-44 GHz, 44-71GHz)을 따로 설계한 반면, 믹서의 경우, fundamental, 2nd harmonic, 3rd harmonic 을 조합해서 24-71 GHz에서 down-conversion 을 하는 harmonic selection technique 이 적용되었다.
#27-5 는 삼성전자에 발표한 또 다른 논문으로 multiple inter/intra CA를 하나의 single-path 와 integer LO-PLL 로 처리 가능한 digital-IF receiver prototype 소개한다. 실제 FR1 대역 지원 주파수 밴드와 CA수도 지속적으로 증가하고 있기 때문에 single-path 로 multiple CC 신호 받아 digital domain 에서 channel selection 을 한다면 많은 수신단 개수를 줄일 수 있다. 논문에서는 이슈가 되는 multiple TX 누설 신호와 이미지 제거 해결을 위해 하이브리드 간섭신호 필터 와 poly-phase filter 기술을 새롭게 설계 제안하였다.
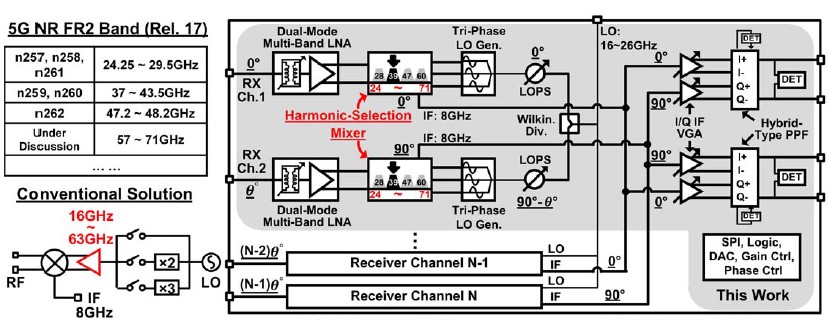 |
| [그림 2] #27-4 제안한 24-71 GHz 지원 5G 멀티밴드 위상 배열 수신기
|
| #Digital Circuits and Systems |
|
ㆍSession 11 / Compute-in-Memory and SRAM
|
|
최근 데이터 중심 응용인 딥러닝이 이미지 인식이나 자연어 처리 등에서 괄목할만한 성공을 거두고 있다. 하지만 실질적으로 데이터를 처리하는 데 필요한 시간과 에너지보다 데이터가 메모리와 프로세서 사이를 이동하는 데 걸리는 시간과 에너지가 더 많아지고 있으며, 이러한 메모리 병목 현상은 딥러닝 가속기 구현의 가장 큰 챌린지가 되고 있다.
이를 해소하기 위하여 폰 노이만 구조와는 근본적으로 다른 접근방식인 메모리 내에서 직접 프로세싱을 하는 Compute-in-Memory (CIM)에 대한 연구가 활발히 진행되고 있다. CIM은 다양한 신호 도메인에서 에너지 효율적 연산을 수행하기 위해 다양한 메모리 기술들의 특징을 활용하는 방향으로 발전하고 있다. 본 세션에서는 고성능 컴퓨팅 장치부터 저전력 엣지-AI 장치까지의 다양한 어플리케이션을 지원하기 위해 다양한 메모리 기술 (DRAM, ReRAM, MRAM, PCM, SRAM)을 활용한 CIM이 소개되었다.
작년 ISSCC (2021)에서 삼성전자가 세계 최초로 High Bandwidth Memory (HBM2)를 이용한 Processing-in-Memory (HBM-PIM)을 공개했었는데 (20nm 공정, 6GB 용량, 1.2TFLOPs (= 300MHz*128*32byte)), SK하이닉스에서 올해 발표한 #11.1 논문에서는 HBM의 비싼 가격적 단점을 해소하기 위해 GDDR6를 이용하는 CIM 솔루션이 제안되었으며, 1ynm 공정, 8Gb (= 1GB) 용량으로 1TFLOPS (= 1GHz*32*32byte)의 성능을 달성하였다. 또한 bank-wide mantissa shift (BWMS) scheme을 통해 파워와 시간뿐만 아니라 adder tree의 면적을 감소시켰으며, 이 면적을 reservoir capacitor로 활용하여 Vdd가 stable하게 동작되도록 하여 Vdd를 일반 GDDR6에서의 1.35V에서 1.25V로 줄였다.
|
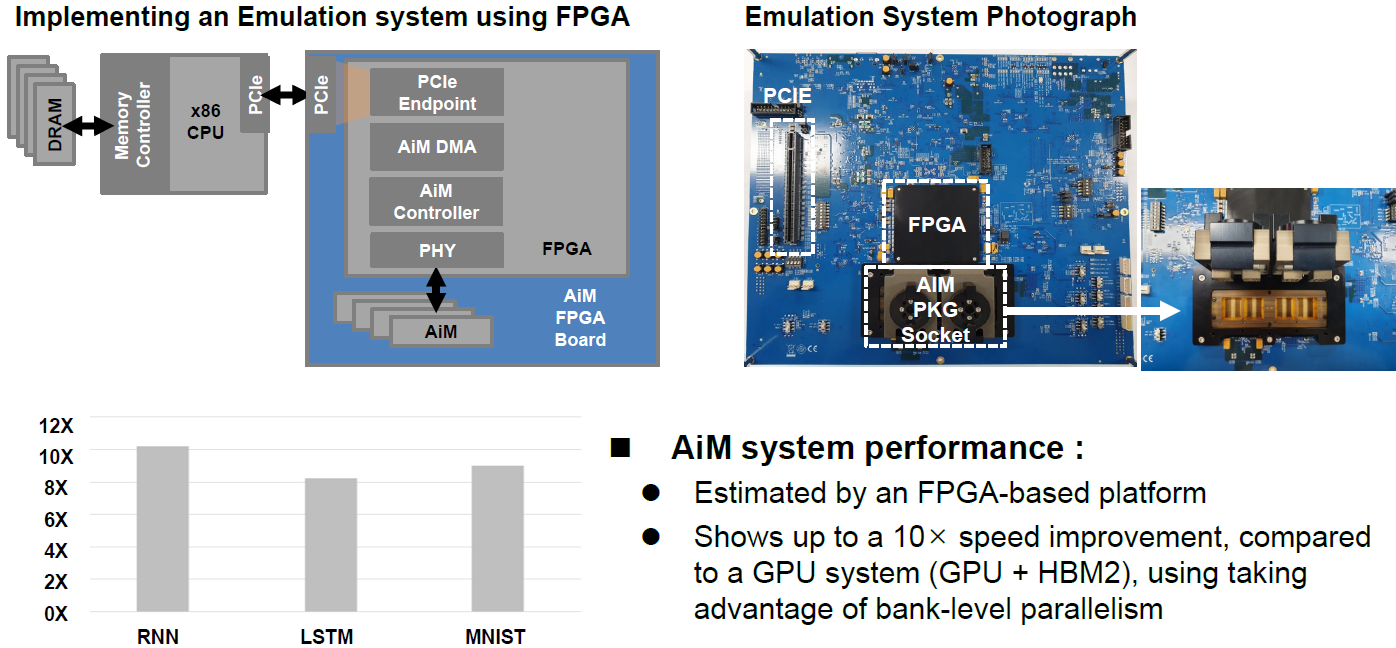 |
| [그림 1] #11.1 논문에서 제안한 GDDR 기반 CIM 솔루션의 System Evaluation |
|
배터리에 의해 동작되는 엣지-AI 장치는 대기모드에서의 동작이 지배적이므로 배터리 수명을 늘리기 위해서는 비휘발성 메모리 기반 CIM이 필요하다.
#11.2 논문에서는 비휘발성뿐만 아니라 신경망 모델 정보를 보호하기 위한 data-encrypted MAC operation을 지원하는 22nm 4Mb STT-MRAM CIM macro가 소개되었다. 2304 bus-width를 사용하는 CIM macro는 0.8V 동작전압, 8b-input, 8b-weight, 26b-output 계산에서 192GB/s read BW와 25.1TOPS/W 에너지 효율을 달성하였다. 일반적으로 singe-level cell (SLC)은 signal margin이 커서 고성능에 유리하고, multi-level cell (MLC)는 memory density가 높아서 고집적에 유리하다.
#11.3 논문에서는 8bit weight 중 upper 2bit은 signal margin을 향상시키기 위해 2개의 SLC에 저장하고 lower 6bit은 면적 효율을 위해 3개의 MLC에 저장하는 hybrid 40nm PCM CIM macro를 선보였다. Sparsity를 향상시키는 input-reordering scheme을 함께 적용하여 8b-input, 8b-weight, 19bit-output 계산에서 20.5TOPS/W 에너지 효율을 달성하였다.
#11.4 논문에서는 에너지 효율을 높이기 위해 DC-current-free time domain MAC 연산을 지원하는 22nm 8Mb SLC ReRAM CIM macro가 제안되었으며, 8b-input, 8b-weight, 19b-output 계산에서 61.8TOPS/W 에너지 효율을 달성하였다.
#11.6 논문에서는 analog 기반 CIM에서의 accuracy loss 문제를 해결하고 더 진보된 공정을 사용하기 위해 5nm 12T SRAM (0.075um2 = 3000F2) fully digital CIM macro를 제안하였으며, 4b-input, 4b-weight, 14b-output 계산에서 254TOPS/W 에너지 효율을 달성하였다.
#11.7 논문에서는 기존 analog/digital CIM 설계의 density와 flexibility 문제를 해결하기 위해 28nm 32kb full-precision ADC-less SRAM CIM macro를 선보였으며, 8b-input, 8b-weight, 8-21b-output 계산에서 27.4TOPS/W 에너지 효율을 달성하였다.
#11.8 논문에서는 high IN-W-OUT precision 및 많은 accumulation 수에서도 accuracy loss 없이 동작이 가능한 28nm time-domain 1Mb SRAM-CIM macro를 제안하였으며, 8b-input, 8b-weight, 22b-output 계산에서 37TOPS/W 에너지 효율을 달성하였다.
|
 |
|
| #Bio |
|
ㆍSession 12 / Monolithic System for Robot and Bio Applications
|
|
칩 자체의 성능뿐만 아니라, 시스템을 위해 필요한 부분을 온-칩 구현 혹은 칩과 같이 긴밀하게 연결하여 시스템을 구현한 디자인들이 해당 세션에서 다루어졌다. 총 7편의 논문이 발표되었는데 그중 바이오메디컬에 긴밀하게 연관된 논문들은 #12.4 – #12.6이다.
|
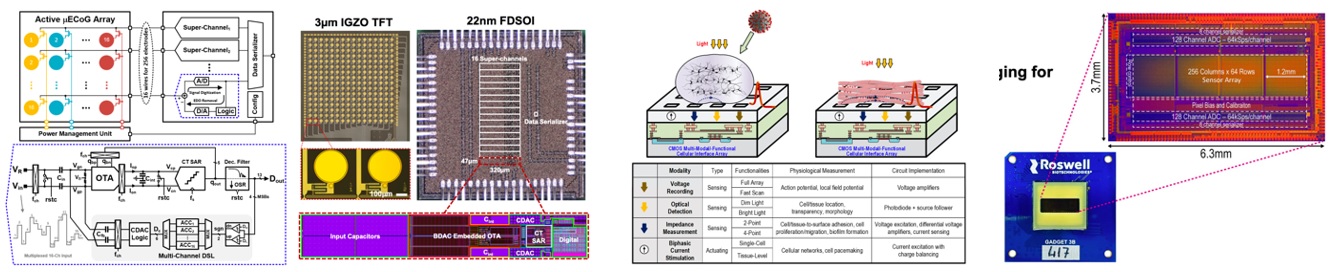 |
| [그림 1] 12.4, 12.5, 12.6의 대표 그림 |
|
#12.4 해당 논문은 기존의 ADC-Direct Front-End가 하나의 전극에만 적용되어 다수 채널 구현의 어려움을 가지는 것을 해결하고자, 다수 전극에 연결 가능한 ADC-Direct Front-End를 제안하였다. 16개의 전극이 하나의 ADC에 연결되며, multiplexing을 위해 switch matrix를 설계하였다. 전극과 해당 스위치는 flexibility를 위해 indium gallium zinc oxide thin-film transistor technolgy를 사용하여 총 256개의 전극을 구현하였다. 단일 전극의 노이즈는 3.98uVrms였다. 멀티채널을 극대화하기 위해 ADC의 면적을 극소화해야만 하며, 이를 위해 기존의 capacitive DAC이 아닌 OTA의 input pair 디바이스의 bulk의 전압 컨트롤하여 DAC을 구현하였다. FDSOI소자를 사용하였기에 latch-up등의 문제에 대한 고려 없이 bulk조절 기술 구현 가능하였으며, 해당 기술을 통해 ADC의 면적은 0.001mm2로 기존 기술에 비해 극소화 되었다.
#12.5 본 논문은 셀을 칩 위에서 배양(culture)한 뒤에 해당 셀의 특성을 파악 (전기신호 측정, 전기 자극, 옵티컬 측정, 임피던스 측정)할 수 있는 멀티모달(multi-modality) 칩을 구현하였다. 시스템 레벨의 완성도가 돋보이는 해당 논문은 COVID-19 Pseudo Particles transfected hydrogel을 포함한 다양한 in-vitro 테스트가 본 논문의 중요성을 한번 더 강조한다.
#12.6 Molecular electronics에 관한 논문으로 single molecules 들을 회로 소자로 활용한 첫 제안이다. 반도체 설계 후 후공정을 통해 수십 nm의 갭을 만든 후 해당 갭에 molecular wire를 접착 시킨다. 해당 wire는 후에 probe molecules들이 부착되어 센싱을 하게 된다. 기존 바이오센서와는 다르게 직접적인 single molecule kinetics를 관측할 수 있다. 주로 전류 적분 후 적분 된 전압 정보를 ADC를 통해 측정하는 원리이다. Single-slope ADC의 사용으로 면적 효율성을 높였으며 디지털화 된 정보를 FPGA를 활용하여 처리하였다.
|
 |
|
| #Bio |
|
ㆍSession 20 / Body and Brain Interfaces
|
|
세션 20에서는 신체 또는 뇌와 연결되어 측정, 자극, 신호처리가 가능한 다양한 형태의 웨어러블, 이식형, in vitro 용 시스템들이 소개되었다. 총 8편의 논문이 발표되었으며, 그 중에서 웨어러블 바이오신호 인터페이스 시스템이 5편 (#20.1, #20.2, #20.3, #20.7, #20.8)이 소개되었고, 이식형/in vitro 신경 인터페이스 시스템이 3편 (#20.4, #20.5, #20.6)이 소개되었다.
|
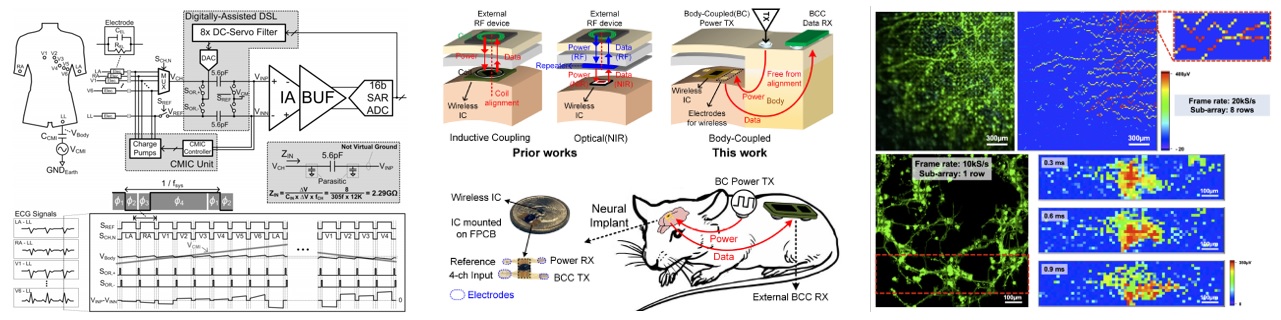 |
| [그림 1] 20.2, 20.5, 20.6의 대표 그림 |
|
#20.2 3D 구조(장기 등)를 통한 진단을 위해서는 다채널 측정이 필요하며, 정확하고 신뢰성 높은 진단을 위해 높은 common-mode interference (CMI)의 제거와 입력 임피던스가 필요하다. 기존에는 2개의 전극을 사용한 차동 구조를 사용하였으나, 채널 수를 늘리기 위해서는 직접적인 응용이 어렵고 많은 에너지 및 면적이 필요하다는 단점을 있다. 이를 해결하기 위해 본 논문은 아날로그 core를 공유하는 digitally assisted time-domain multiplexing (TDM)과 다채널에도 적용 가능한 CMI cancellation (CMIC) 구조를 제안하였다. CMI에 대한 CMRR은 20Vpp일 때 100dB 이상의 값을 가졌으며, chopping-free 구조를 통해 2.29GΩ의 높은 입력 임피던스를 가지면서 비접촉 측정이 가능한 8채널 ECG 측정 IC를 구현하였다.
#20.5 본 논문에서는 기존 웨어러블 기기에서만 쓰이던 body-coupled communication (BCC)와 body-coupled power delivery 방식을 적용한 neural implant를 발표하였다. 기존의 인덕티브 링크, 광학, 초음파 방식에 비해 body-coupled 방식은 device간의 정확한 정렬 없이도 파워와 데이터 공급을 보장할 수 있다. 더불어 본 연구는 개선된 Gm-C input architecture를 기반으로 한 CT-ΔΣM 방식을 제안하였다. 해당 방식은 7개의 IDAC element만으로 15개의 quantization 레벨을 구현하는 tri-level feedback scheme으로 면적을 2배 감소시킨다. 또한 Gm-C 적분기에 인버터 기반 Gm-부스팅 증폭기를 사용하여 에너지 효율을 개선하였다. 제안된 시스템은 in vivo로 검증되었다.
#20.6 본 논문에서는 전극 수율(총 전극 수에 대한 프레임당 기록된 전극 수의 비율)을 최대화하기 위해 sub-array multiplexing (SAM) 아키텍처를 가진 MEA 시스템을 발표하였다. 제안된 MEA 시스템은 24,320개의 전극과 각 17.7μm 피치의 픽셀을 가진다. SAM 방식을 사용하면 column의 각 AFE 채널이 주어진 샘플링 시간에 여러 전극을 하나씩 기록할 수 있으므로 라우팅 복잡성과 AFE 채널 개수를 줄일 수 있다. 재구성 가능한 SAM은 전극의 pseudo-random 연결을 제공하여 단일 뉴런과 신경 시냅스 세포의 신호를 효과적으로 기록할 수 있다. Sub-array의 Frame Rate를 변경하여 낮게 조정하여 전체 어레이를 스캔하거나 Frame Rate를 높게 조정하여 표적 영역에서 단일 뉴런의 활동을 조사할 수도 있다. MEA 시스템은 in vitro 실험으로 검증되었다.
|
 |
|
| #Analog |
|
ㆍSession 31 / Audio Amplifiers
|
|
Analog subcommittee (아날로그 분과) 주관으로 조직된 이번 “31. Audio Amplifiers” 세션에서는 총 4편의 논문이 발표되었다. 일반적으로 오디오 증폭기 주제로 단독 세션이 개최된 사례는 ISSCC에서 매우 드문 경우이며, 이는 고품질, 고출력, 저전력 오디오 IC에 대한 학계와 산업계의 최근 증가된 관심도를 보여주고 있다고 평가된다. 본 세션에서는 선형성 및 동적영역 개선 등의 전통적인 우수한 음질을 위한 오디오 증폭기 관련 연구가 발표되었고, 더불어 3D 오디오 및 piezoelectric speaker용 드라이버 등의 새로운(emerging) 분야의 논문도 함께 발표되었다.
#31.1 – 대만 MediaTek : 본 논문에서는 매우 낮은 THD와 넓은 DR 성능을 갖는 스테레오 오디오 디코더 칩을 발표하였다. 참고로 우수한 성능의 high-fidelity sound 구현을 위해서는 매우 작은 신호의 재생을 위해 넓은 DR이 필요하고, 큰 신호에서는 낮은 THD가 필요하다. 본 논문에서는 주요 신호왜곡의 원인으로 1) ISI (inter-symbol interference), 2) 3차 하모닉 (HD3), 그리고 3) Class-AB 증폭기의 crossover (COD)를 지적하였다. 전류 DAC (I-DAC)에서 dynamic element matching (DEM)은 필수적인데 이때 주로 ISI가 발생하며 noise floor도 증가하는 경향이 있다. 종래의 real-time DEM (RT-DEM) 기법은 1-LSB 변환에 대해서만 ISI를 방지하였지만 이는 델타-시그마 모듈레이터의 DR을 제한하는 문제가 있어왔다. 본 논문은 DAC cell의 스위칭 상태를 누적하여 모니터링하는 신호를 추가한 새로운 알고리즘으로 7-LSB 코드 변화까지도 bubble이 발생하지 않는 “code-change-insensitive RT-DEM (CCI-RT-DEM)” 기법을 제안하였으며, 종래 RT-DEM 대비 13dB의 THD+N 개선효과가 있었다. 또한, 전류-전압 변환에서 poly-resistor의 velocity saturation effect (VSE)에 의한 HD3 문제를 해결하기 위해 차동출력으로부터 cross-coupled 저항을 입력으로 추가 피드백하는 회로설계 구조를 제시하였다. 마지막으로 audio-band에서 높은 inner-loop gain을 유지하여 COD를 줄이는 방법으로 “2차 damping-factor control (DFC)” 회로를 제안하였으며, 이를 통해 COD를 10dBc 이상 개선하였다. 본 논문은 연구 완성도가 매우 높은점이 인상적이였고, 세계최고 성능인 -117dBc THD와 126dB DR을 경쟁력있는 낮은 전력소모(4.8W)로 달성했다는 점에서 큰 의미가 있다고 할 수 있다.
#31.2 – 네덜란드 Delft공대 & Goodix Tech. : 본 논문은 세계 첫 capacitively-coupled Class-D 오디오 증폭기 구조를 발표하였다. 종래의 Class-D 증폭기는 resistive feedback network로 closed-loop gain을 구현하였는데 일반적으로 대부분의 잡음이 입력단의 저항에 의해 발생한다. 잡음을 줄이기 위해 입력저항을 낮추면 front-end integrator의 충분한 signal swing을 얻기가 어려워 일반적으로 20kΩ 정도로 설계한다. 본 논문은 입력저항에 의한 잡음을 제거하기 위해 capacitive feedback 구조를 시도하였으며, 여기에 200kHz의 chopping 기법을 추가하여 높은 PSRR과 낮은 1/f 잡음을 목표로 하였다. Capacitive feedback은 펄스형태의 Class-D 출력 잡음을 virtual ground의 입력단에 심각하게 전달하므로 LC (EMI) 필터를 추가하고 그 이후에 출력 피드백 신호를 취득하는 구조(feedback-after-LC)를 채택하였다. 본 논문은 고전압 chopping 회로 구현과 level-shifter의 timing skew에 의해 발생하는 glitch 문제를 해결하기 위해 다양한 시도를 선보였다. 칩 구현결과 20kΩ 입력저항의 noise floor 대비 10dB 개선된 THD+N을 달성하였으며, DR과 PSRR에서도 우수한 성능을 보였다. 입력저항으로 발생하는 잡음제거를 위한 세계 첫 capacitive feedback Class-D 구조라는 점에 의미가 있고, biomedical sensor-interface에 주로 활용되는 capacitively-coupled chopper 구조를 Class-D 오디오 증폭기에 적용한 것이 흥미로웠다. 하지만 LC 필터의 비선형 문제가 어떻게 해결되었는지 자세히 다뤄지지 않았고, glitch 제거를 위해 삽입된 dead-band (DB)에 의한 DR 성능저하가 조금 우려되었다.
#31.3 – 대만 NCKU : 본 논문은 디지털 입력의 고성능 Class-D 오디오 증폭기를 발표하였다. 낮은 출력 파워에서 주요 THD+N 저하요소는 매우 좁은 PWM 펄스에서의 clock jitter 잡음이며, 오디오 볼륨이 낮을수록 clock jitter에 의한 성능저하가 두드러진다. 본 연구에서는 오디오 볼륨 레벨을 여러 단계로 나누고 이에 따라 PWM 펄스의 전원 전압을 가변하는 “supply-voltage-scaling volume control” 기법을 제안하였다. 매우 낮은 오디오 볼륨에서 PWM 펄스 폭을 줄이는 것 대신에 펄스의 전원을 낮춰 PWM 펄스의 폭을 적절히 유지하는 방식이다. 이 기법을 통해 본 연구에서는 약 8배의 jitter-effect 감소효과가 있었다고 한다. 추가로 파워 스테이지의 비선형성을 개선하기 위한 “pulse-width adjustment” 구조를 제안하였으며 이를 통해 중간대역의 출력파워에서 최소 THD+N이 더욱 감소하는 효과가 있었다. 또한, 높은 볼륨의 오디오 출력시 DSM단에서 발생하는 clipping error를 제거하기 위해 고차 DSM과 clipping-suppressed DSM를 연속하여 구성한 “series-connected DSM (SCDSM)” 구조를 제시하여 pop & click 잡음을 줄였다. 0.5μm 공정에서 구현된 칩은 121dB의 높은 DR와 0.0017%의 우수한 THD+N을 달성하였다. 하지만 전원 가변(0.6V ~ 5V)을 위해 포함(내장)된 buck-boost converter로 인해 전체 전력효율이 80% 수준으로 제한되는 점은 다소 아쉬운 부분이다.
#31.4 – 네덜란드 Delft공대 & Goodix Tech. : 본 논문은 piezoelectric speaker를 위한 Class-D audio driver 칩을 발표하였다. Piezoelectric speaker는 form-factor를 비교적 자유롭게 설계할 수 있고, 얇고 투명하게 만들 수 있어서 대면적 평판 TV부터 모바일 기기까지 상용화에 대한 연구가 활발히 진행되고 있다. Piezoelectric speaker의 가장 큰 특징은 종래 스피커의 저항형태의 부하가 아닌 큰 capacitive load (~8μF)로 모델링화 된다는 점이다. 따라서 piezoelectric speaker용 driver는 주로 Class-AB 타입으로 개발되다가 낮은 효율문제로 현재는 Class-D 형태로 연구되는 추세이다. Class-D 증폭기에서는 펄스형태의 신호를 필터링하기 위해 piezoelectric speaker와 Class-D 사이에 인덕터(L)가 삽입된다. 이때 LC damping을 위해 일반적으로 외부 추가 저항 삽입이 필요한데 이로 인해 Class-D의 전류 drivability가 제한되고 전력효율이 저하되는 문제가 있다. 본 논문은 외부 추가저항 없이 LC damping을 구현하는 것이 주요 연구 목표이며, LC로 흐르는 부하 전류를 센싱하여 Class-D 내부에서 피드백하면 LC 공진과 정확히 매칭되는 notch filter가 구현되는 원리의 아이디어를 제안하였다. 정확한 LC damping의 매칭을 위해서는 전류 센싱과 피드백 회로에서 높은 정밀도가 요구되는데 반해 본 연구에서는 단순히 20mΩ 수준의 내장 직렬 저항을 사용하였으며, 전류 패드백의 gain (k-factor)에 따라 성능 편차가 다소 심하여 향후 이 부분에 대한 추가 개선이 필요해 보인다.
|
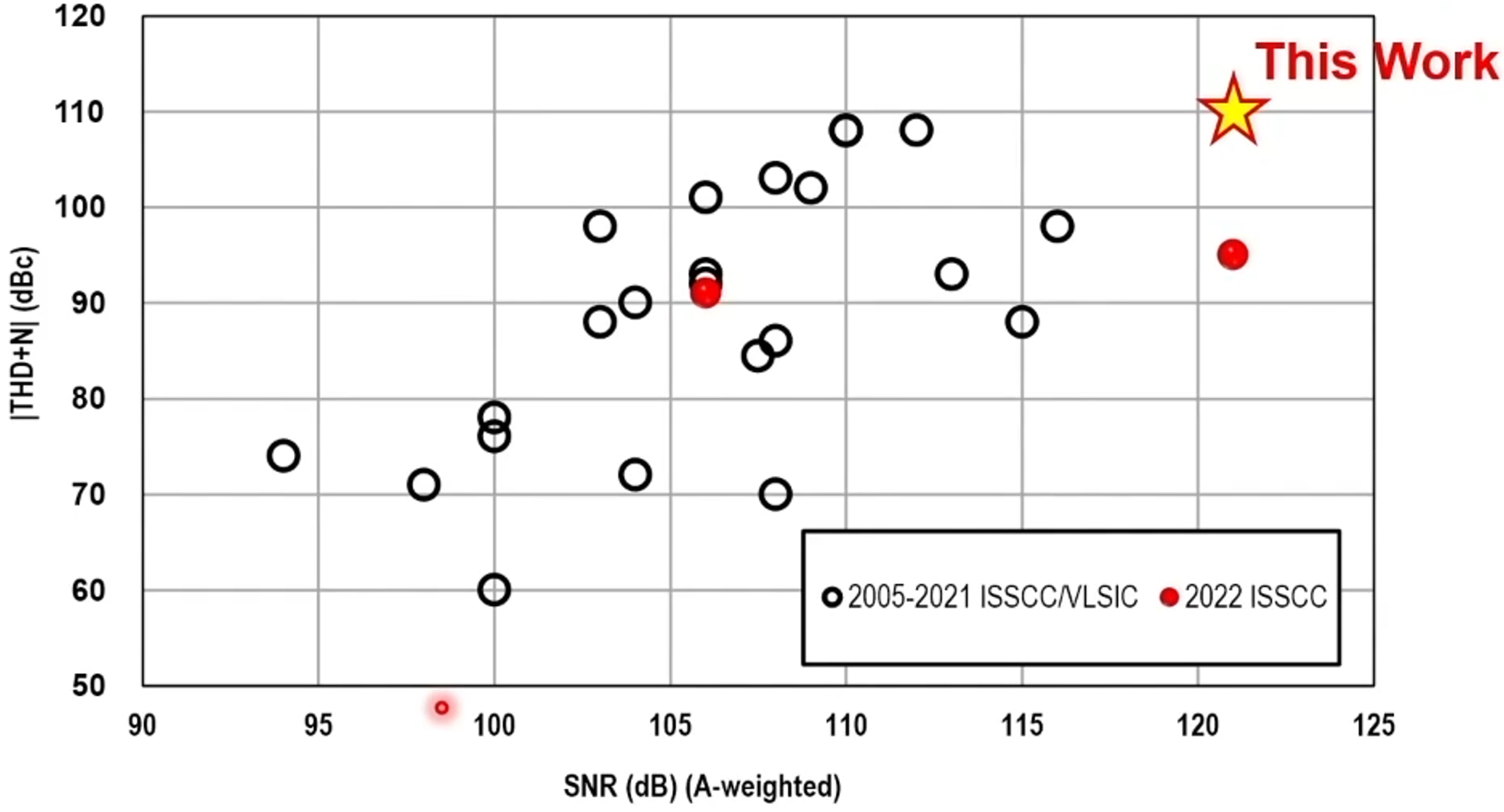 |
| [그림 1] Class-D 오디오 증폭기의 THD+N vs. SNR 성능 추세 그래프 (출처: #31.2) |
| #Power Management |
|
ㆍSession 14 / GaN, High-Voltage and Wireless Power
ㆍSession 18 / DC-DC Converters
ㆍSession 30 / Power Management Techniques
|
|
이번 ISSCC2022에는 약 20편의 power management 논문이 발표되었으며, 각각 session 14(session title: GaN, High-Voltage and Wireless Power) 에 8편, session 18(session title: DC-DC Converters) 에 8편, 그리고 session 30(session title: Power Management Techniques)에 4편이 선정되었다. 이 논문들의 주요 트렌드를 살펴보면, 예년과 마찬가지로 높은 전력변환비를 달성하기 위한 하이브리드 타입의 DC-DC converter가 주를 이루었으며, 이와 더불어 빠른 DVS 혹은 과도신호응답을 위한 방법들도 발표되었음을 알 수 있다. 본 리뷰에서는 일부 논문들을 선정하여 간략히 설명하도록 하겠다.
#14.4 본 논문은 non-isolated type의 48 V-to-1 V 벅컨버터를 제안하고 있다. 기존의 높은 전압변환비를 가지는 벅컨버터와 유사하게, 커패시터와 인덕터를 혼용하여 사용하는 하이브리드 구조를 이용하고 있다. 본 컨버터는 두 가지 구조의 결합으로 구현되는데, 앞 단에는 ladder 구조의 switched-capacitor가 사용되었으며, 뒷 단에는 double step-down (DSD) 구조가 사용되었다. 본 컨버터는 ladder 구조로 인해 각 소자에 낮은 전압 내압을 인가하며, DSD 구조로 인해 dual phase로 인덕터 전류를 출력으로 공급한다. 이러한 특징으로 인해 48 V 입력을 1 V의 출력으로 변환할 때, 87%라는 높은 전력변환 효율을 달성하였다.
|
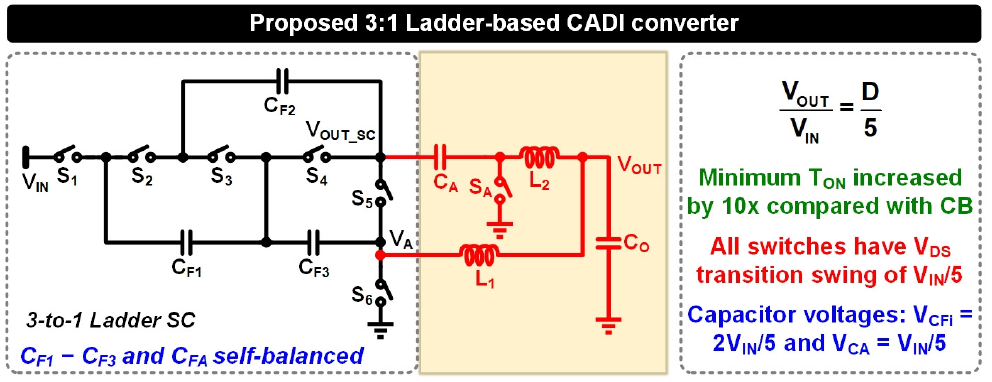 |
| [그림 1] #14.4에서 제안된 컨버터 토폴로지 |
|
#18.2 본 논문은 높은 전압변환비를 얻기 위해 기존에 사용되는 double step-down (DSD) 컨버터의 과도 응답속도를 증가하기 위한 제어 방법을 제안하고 있다. 본 논문에서 제안된 제어 방법은 과도 응답 시 두 개의 인덕터에 저장되는 에너지를 효과적으로 제어하여 응답속도를 높일 수 있다. 이를 위해, 하나의 삼각파를 이용하여 두 인덕터 전류를 동시에 제어하는 방법을 사용하며, 이와 더불어 두 인덕터에 동시에 에너지를 전달하는 dual-phase charging technique을 이용하고 있다. 제안된 기술로 인해, 24 V의 입력에서 1 V의 출력을 생성하며 부하 전류가 0.1 A에서 3.1 A로 변할 때, 56 mV의 voltage drop을 달성하였다.
|
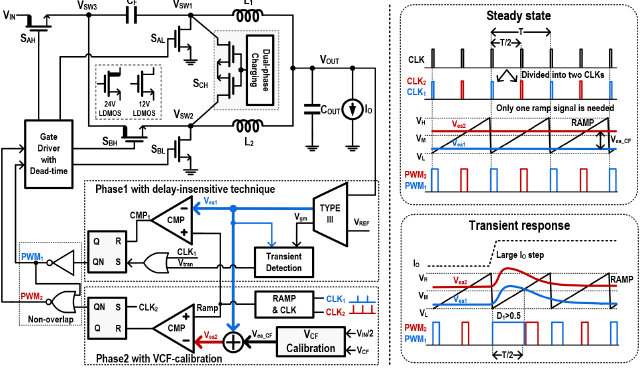 |
| [그림 2] #18.2에서 제안된 DSD 제어 회로 및 방법 |
|
#18.8 본 논문은 인덕터에 흐르는 전류를 감소하여 효율을 증가시키는 하이브리드 구조의 컨버터를 제안하고 있다. 본 논문에 제안된 컨버터는 1/2 이하의 Duty (D)에서 동작을 하며, (1) 1/3 < D < 1/2와 (2) 0 < D < 1/3의 조건에 따라 아래 그림 3과 같이 상이한 동작을 수행한다. 두 가지 조건 모두 인덕터와 커패시터를 직/병렬로 연결을 하여 출력으로 에너지를 전달하며, 이와 같은 동작으로 인해 인덕터 전류를 감소하여 높은 전력 변환 효율을 얻을 수 있다. 구조적인 특징으로 인해 제안된 컨버터는 3 V의 입력을 0.8 V의 출력으로 변환할 때, 92.9%의 높은 전력변환 효율을 달성하였다.
|
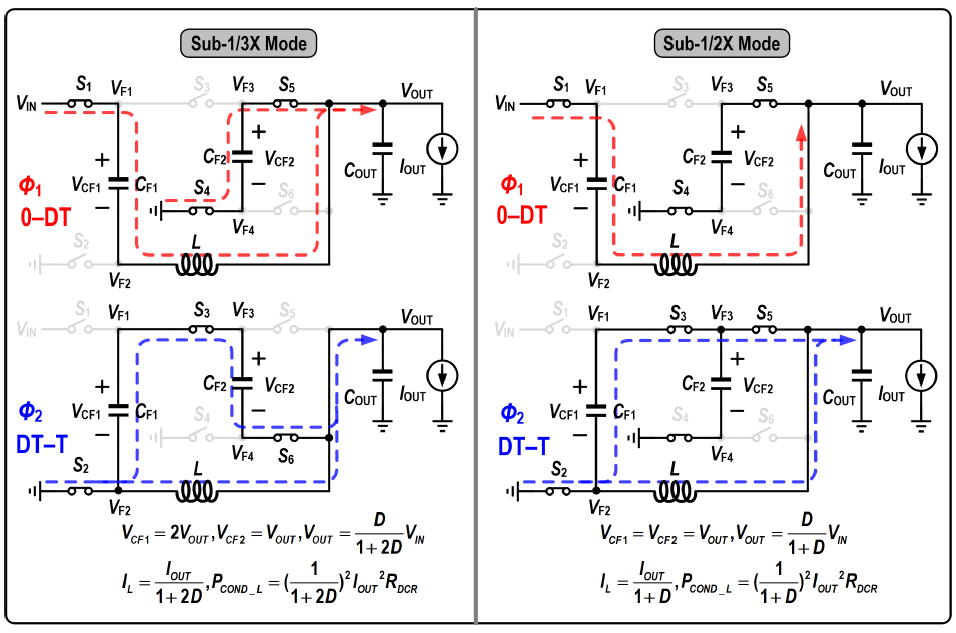 |
| [그림 3] #18.8에서 제안된 구조의 동작 |
| #Image Sensor |
|
ㆍSession 5 / Imagers, Range Sensors and Displays
|
|
Session 5에서는 5편의 CMOS image sensor(CIS), 1편의 indirect time-of-flight(iTOF) 이미지센서와 2편의 direct TOF(dTOF) LiDAR 센서를 포함한 range sensor, 그리고 1편의 display driver IC 논문이 발표되었다. 작년 SONY의 single-photon avalanche diode(SPAD)기반 CIS에 이어, 올해 Canon에서도 1Mpixel급 SPAD CIS를 발표하였고, 차세대 high dynamic range (HDR) SPAD이미지센서가 발전되고 있음을 확인하였다. 삼성전자에서는 2편의 CIS 논문을 발표하였고 각각 발전된 PDAF 및 0.56 um 픽셀을 발표하여 꾸준한 pixel scaling 및 성능 향상을 지속하고 있고, SONY와 연세대학교에서 각각 1편의 저전력 CIS 논문을 발표하여 computer vision/AR/VR 적용을 위한 저전력 CIS에 대한 연구개발이 지속적으로 수행되고 있음을 알 수 있다. Shizuoka 대학교에서는 3D scanner용 고정밀 iTOF 이미지센서를 발표하여 iTOF 센서의 거리 정밀도 한계를 갱신하고 있으며, FBK와 UNIST에서는 각각 1편의 Flash LiDAR 논문을 발표, outdoor 환경에서의 거리 측정시 태양광에 대한 내성 저하 문제를 극복하는 기술을 제시하여 향후 flash LiDAR 센서가 모바일/웨어러블 기기에 탑재 될 수 있는 가능성을 열었다. 마지막으로 KAIST에서는 기존 OLED display용 driver IC의 면적 효율성을 증대시키는 기술을 발표하였다. 각 논문들의 간략한 내용은 다음과 같다.
#5.1 Canon 높은 dynamic range(DR)과 저전력을 동시에 구현한 고해상도(960x960) SPAD 이미지 센서를 제시한다. Counter의 bit depth에 의해 DR이 제한되지 않도록 exposure time을 m,〖 m〗^2 〖,m〗^3 의 3가지 factor로 나눈 각 시점에서의 photon count 값을 비교해threshold 상회시 exposure를 중지, count와 해당 factor의 product을 pixel의 출력으로 계산하는 pixel-wise exposure control (PWEC) 기법을 제시하였다. SPAD의 recharging을 CLK에 동기화한 clocked recharging 기법으로, 고조도시 photon count가 실제보다 감소하는 passive recharging의 문제를 해결하는 동시에 전력을 절감하는 효과를 얻었다. 또한 조도에 따라 counter의 upper limit을 조절해서 고조도 환경에 적합한 full saturation mode와 저조도 환경에 적합한 low noise mode로 adaptive한 운용도 가능하다. 143dB의 HDR을 구현함과 동시에 기존 대비 87.7% 만큼 절감한 370mW 의 power consumption을 갖는 1Mpixel SPAD 이미지 센서를 구현하였다.
#5.2 FBK 픽셀당 single SPAD 및 TDC를 집적한 64x64 해상도의 direct TOF Flash LiDAR 센서를 제시한다. 통상 배경잡음 억제를 위해 한 픽셀에 여러 SPAD를 배치하고, 복수 개의 SPAD 동시 출력을 감지하는 coincidence detection을 적용한다. 본 논문에서는 픽셀 해상도 향상을 위해 픽셀당 single SPAD만을 배치하는 대신 인접 픽셀들을 이용, inter-pixel coincidence detection을 통해 배경잡음의 영향을 억제하는 distributed-digital(d2) silicon photomultiplier 구조를 사용하였다. 또한 first & last hit acquisition mode, SPAD sensitivity를 조절하기 위해 excess bias voltage를 programmable하게 조정하는 pixel automatic sensitivity adjustment mode와 같은 BG의 영향을 낮추는 기법을 사용하였다. 해당 기법들을 적용, 30 klx하의 외광 아래 25 fps의 depth image를 획득하였다.
#5.3 UNIST 본 논문 또한 2D SPAD 픽셀 어레이를 집적한 80x60 flash LiDAR 센서이다. 2021년 ISSCC에서 binary search를 통해 소형 회로로 histogramming을 수행할 수 있는 zoom histogramming TDC가 제안되었으며, 본 논문에서는 이를 발전시킨 quaternary search 방식을 제안한다. 기존 zoom histogramming TDC에서 발생하는 (1) 낮은 frame rate에 의한 motion artifact, (2) 낮은 signal-to- background ratio (SBR)에 의해서 발생 되는 정밀도 저하 문제를 해결하였다. 전체 노출 시간을 4개의 time bin으로 나누고, 그 중 SPAD event가 많이 발생하는 한 개의 time bin으로 ToF로 결정하는 quaternary search 알고리즘을 제안하여 속도 및 SBR을 개선하였고, 위상연산을 통한 fine depth 감지시 두 위상신호의 delta 값을 이용하는 4-위상 연산 방식을 통해 공통 배경잡음에 대한 면역성을 키웠다. 제안 기법들을 적용하여 30 klux 외광 하에서도 30 fps의 depth image를 획득하였으며, 1.5 cm의 거리 정밀도, 2.5 cm의 거리 정확도를 나타내었다.
|
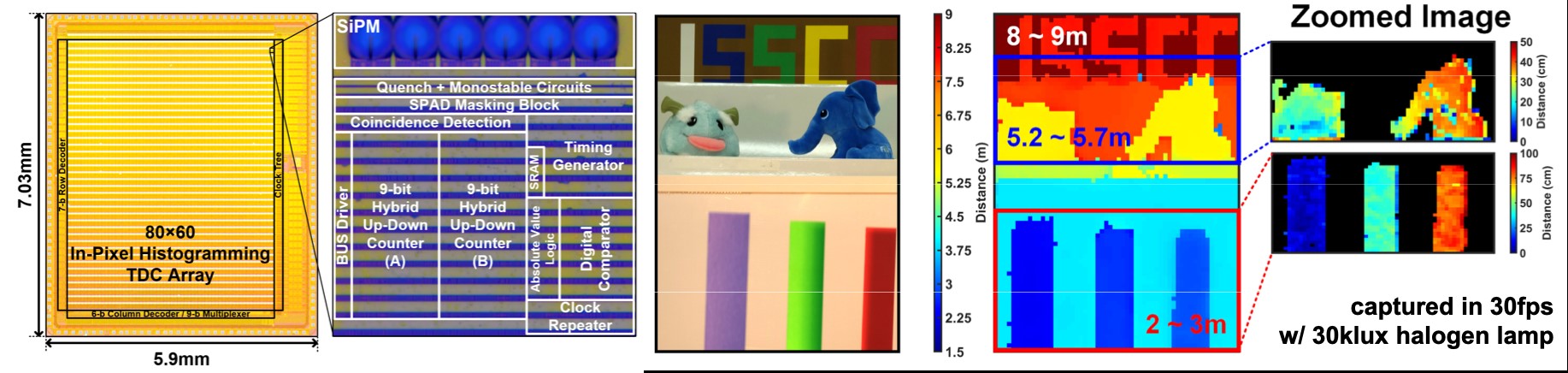 |
| [그림 1] Quaternary search 기반 histogramming TDC를 집적한 80x60 flash LiDAR sensor |
|
#5.4 Shizuoka Univ. 본 논문은 3D scanning 어플리케이션의 고정밀 indirect TOF 이미지 센서를제시한다. 고정밀 측정을 위해 픽셀 모듈레이션 pulse-width를 최소화하고, 해당 pulse-width 내 광전변환된 전자를 고속 capture하기 위해 기 개발된 Lateral Electric Field Modulation(LEFM) Pixel 및 IPR(Impulse Photocurrent Response)-ToF 방식을 사용하였다. 본 논문에서는 jitter를 줄이기 위한 CI(Charge-Injection)-RPS(Reference Plane Sampling) 구조를 제안하였다. 광원 jitter의 영향을 최소화하기 위해 reference plane을 sampling 한 reference pixel 값을 빼주는 calibration을 사용한다. 또한 픽셀 gate driver의 jitter에 의한 영향을 줄이기 위해 column reference pixel의 값을 빼주는 Dual-RPS 방식을 사용한다. 이를 위한 추가적인 광원이 필요하다는 단점을 보완하기 위하여 CI pixel을 새롭게 제시하였다. CI pulse를 인가하여 main pixel과 동일한 jitter 성분을 가지는 pseudo photocurrent를 생성, 모든 column의 CI pixel 평균값을 빼주어 jitter 성분만을 남기고, 이를 main pixel 출력에서 빼는 방식이다. 측정 결과 23mm range에서 55um의 정밀도를 나타내었고, 10-frame averaging시 38um의 높은 range precision을 획득하였다.
#5.5 Samsung 본 논문에서는 Phase-detection autofocus (PDAF)용 dual pixel의 size를 1 um pitch로 줄인 CIS를 제시하였다. Frontside deep trench isolation (FDTI) 공정을 통해 기존 backside deep trench isolation (BDTI)를 사용한 1.2 um pixel 보다 pixel size가 작아졌음에도 crosstalk을 줄였고, silicon의 두께가 증가된 deep photodiode를 만들어 full-well capacity 및 sensitivity를 동시에 향상시켰다. 또한 FDTI 공정을 통한 PD간 완벽 분리로 인해dual photodiode의 좌우 배치 뿐만 아닌 상하 배치를 가능케 하여 각각 horizontal 및 vertical 방향 배치를 통한 all-directional AF를 이뤄낼 수 있었다. 본 논문에서 제시된 1.0 um pitch의 FDTI dual pixel은 기존 1.4 um BDTI dual pixel과 유사한 수준의 10000 e-의 full well capacity, 15.5%의 crosstalk을 나타내었고, 3450 (e-/lux sec)의 sensitivity를 나타내었다.
#5.6 SONY 고화질 촬영을 위한 고해상도 (2560x1920) 및 저전력 컴퓨터 비전/인식을 위한 저해상도 (320x240) 영상을 programmable하게 출력 가능한 이미지 센서를 제시한다. 고화소 픽셀에서 저해상 영상을 출력하기 위해 인접 16개의 픽셀들을 하나의 floating diffusion(FD) node에 스위치를 통해 연결, 여러 픽셀에서 발생한 charge를 공유된 FD node에 동시 전달하여 charge를 더하고, 인접 FD node들을 스위치로 연결하여 averaging함으로써 최대 192 픽셀의 출력값을 한 픽셀값으로 merging하는 FD binning 기법을 사용하였다. 또한 전력 절감을 위한 in-frame dynamic voltage & frequency scaling 기법을 적용하였고, 저해상 1 fps 동작 기준 590 uW의 저전력을 소모하였다. FD binning 기법, DVS/DFS 기법은 이미 널리 알려진 기법이나 본 논문에서는 이를 2560x1920 화소 센서에 확장 적용하여 완성도 있는 구현을 하였다는 점은 의의가 있다.
#5.7 연세대 Time-mode imaging 방식을 사용하여, Frame ∙ Pixel당 22.9pJ 저전력 및 92dB 의 높은 DR을 가지는 fully digital CMOS Image Sensor를 제안하였다. pixel array와 frame memory가 각 column별로 연결되어 있는 구조를 사용하였고, pixel 전압이 기준 전압에 도달하는 시점의 counter값(timer 값)을 frame memory에 저장하는 동작 방식을 사용한다. 비록 본 논문에서는 pixel array와 frame memory를 평면상으로 연결하는 non-stack 방식으로 구현되었으나, stack 공정 사용 시 최적의 면적 효율을 가질 수 있다. 픽셀 기준 전압을 ramping시키는 기법을 제안하여 DR을 extension, 96dB의 높은 DR을 구현하였다.
#5.8 Samsung ISSCC’21에 발표된 0.64 um pitch pixel보다 소형화된 0.56 um pitch의 unit pixel을 가지는 64Mpixel CIS를 소개한다. 픽셀 scaling에 따르는 1. full-well capacity(FWC)의 저하, 2. dark current 증가, 3. temporal noise 증가, 4. sensitivity 감소 및 crosstalk 증가의 문제점들을 해결하였다. 본 논문에서는 각각 1. DTI width 및 doping 조절, 2. DTI interface에 negative voltage 인가를 통한 hole accumulation, 3. Binning & pixel source follower sharing, 4. fence 구조의 dielectric에 air gap 추가를 통한 개선을 제시하였으며, 6000 e-의 FWC, 0.75 e-/s의 dark current, 1.5 e-의 temporal noise, 1.2%/5.5%의 sensitivity/crosstalk 향상을 이루었고, pixel scaling에도 불구하고 기존 0.64 um pixel 대비 우월한 성능 지표를 나타내었다.
|
 |
| [그림 2] FDTI를 적용한 0.56 um pixel을 가지는 64Mpixel CMOS image sensor
|
|
#5.9 KAIST 모바일 디스플레이의 해상도 증가에 따라 컬럼 채널수가 증가하고, 채널당 배치되는 고해상 DAC의 면적 부담이 커지게 되었다. 또한 높은 dynamic range를 위한 넓은 full-scale range 구현을 위한 고전압(HV) 트랜지스터의 사용이 요구됨에 따라 scaling이 어려운 문제가 있다. 본 논문에서는 채널당 2688 um2의 작은 면적을 가지는 OLED Display향 10b source driver IC를 제시하였다. 8b RDAC을 1.5V thin-oxide 트랜지스터를 사용한 저전압(LV) 스위치드-캐패시터 기반 LV-to-HV 증폭 DAC로 구현하여 면적 절감을 이루는 동시에, 채널간 미스매치의 영향을 최소화하였다. 제안된 2b LSB stack-up(LSU) 기법을 통해 큰 면적 오버헤드 없이 10b 해상도를 구현, 기존 구조 대비 65% 이상의 면적 절감을 이루었다.
|
| #Data Converter |
|
ㆍSession 10 / Continuous-Time ADCs and DACs
ㆍSession 25 / Noise-Shaping ADCs
|
|
Data Converters 분과에서는 두 세션 (세션 10, 세션 25)에 걸쳐 총 13편의 논문이 발표되었다. 고속으로 동작하면서도 에너지 효율을 극대화하기 위한 다양한 설계 기법을 적용한 Data Converter 논문들이 발표되었는데, 전체적으로는 저전력 증폭기와 적분기를 Dynamic Amplifier나 Ring Amplifier를 활용하여 구현한 논문들이 많았고, 미세공정에서 유리한 Time-Domain 신호 처리를 적극적으로 활용한 논문들도 눈에 띄었다. 세션 10에서는 고속과 저전력을 동시 달성하기 위하여 가장 적합한 구조인 Pipeline 구조의 ADC에 관한 네편의 논문 (10.1, 10.2, 10.3, 10.4)이 발표되었고, 24bit의 초고해상도 SAR ADC 논문(10.5)과 IoT나 센서용으로 사용가능한 저전력 Incremental ADC에 관한 논문 두편(10.6, 10.7)이 발표되었다. Session 25에서는 오디오나 센서에 필요한 높은 Dynamic Range를 달성하기에 용이한 Noise-Shaping ADC가 발표되었다. 세편의 논문 (25.1, 25.2, 25.3)은 수kHz대역에서 SFDR과 DR를 향상시키기 위한 ΔΣ 변환기에 대한 연구 결과였고, 나머지 세편 (25.4, 25.5, 25.6) 보다 광대역 신호를 변환할수 있는 CTDSM과 Noise-Shaping SAR ADC에 대한 연구 결과였다. 발표된 논문의 핵심적인 내용을 아래와 같이 간추려 보았다.
|
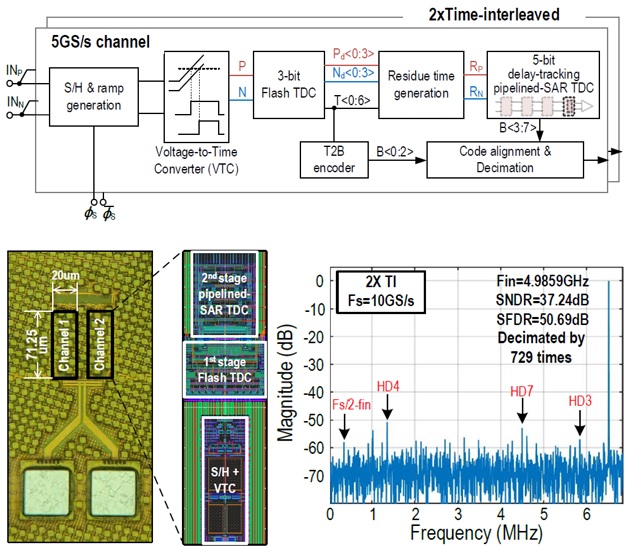 |
| [그림 1] 논문 10.1에서 발표한 Time-Domain Pipelined SAR TDC의 구성도(위)와 칩 사진(아래) |
|
Session 10. Nyquist and Incremental ADCs
#10.1 Two-Step Time-Domain ADC에 대한 연구로 Delay-Tracking Pipelined SAR TDC라는 새로운 구조를 제안하였다. 14nm 공정으로 설계된 테스트칩은 10GS/s에서 40dB의 SNDR을 달성하였고 전력 효율도 25fJ/c-s로 10GS/s급의 ADC로는 최고 수준이다. Selective Delay Tuning이라는 Cell을 이용한 Time-Domain SAR와 Delay Pipeline을 이용하여 Conversion Throughput을 극대화 하였다. 다만 delay 기반의 ADC의 문제점인 온도나 전압에 성능이 민감한 부분을 foreground calibration으로 해결하였는데, 온도나 전압에 따라 bit weight를 모두 조정해주어야 하는 점이 제안하는 ADC의 단점이라고 볼수 있다.
#10.2 Correlated Level Shifting기법을 Ring Amplifier에 적용하여 Residue Amplifier를 고속/저전력/고정밀로 설계한 14b 130MS/s Pipelined SAR ADC논문이다. CLS기법의 경우 직렬로 삽입할 Capacitor를 샘플링시 Load에 병렬로 붙여 놓아야 해서 속도면에서 손해가 있는데, Ring Amplifier의경우 3개의 inverter가 cascade로 연결되다는점에 착안하여 level shifting capacitor를 두개로 분산시켜 속도의 열화를 방지한다는 아이디어를 착안하였다. 28nm에서 설계된 테스트칩은 측정 결과 calibration없이 65MHz Bandwidth의 대역폭에서 72dB의 SNDR을 달성하였다.
#10.3 kT/C 샘플링 노이즈를 Cancel할 수 있는 설계 기법을 Pipelined SAR ADC에 적용한 논문이다. 기존에 제시되었던 kT/C 샘플링 잡음을 제거하기 위한 방법에서는 wideband preamp가 필요하였는데, 이를 ring amplifier를 이용하여 저전력으로 구현하였다. 또한 ring amp의 stability를 개선하기 위해 출력에 LHP zero를 삽입하여 ringing을 줄여 ADC 변환속도 향상을 꾀하는 설계 기법을 선보였다. 28nm에서 설계된 프로토타입 chip은 200MS/s에서 동작하고 66.5dB의 SNDR을 달성하였다. 단점이라면 kT/C 노이즈 제거의 효과가 20%정도밖에 되지 않아 드라마틱한 효과를 보기는 어렵다는 한계가 있어 보인다.
#10.4 Two-Stage Pipelined SAR의 두번째 Fine Stage의 설계를 Ring TDC를 Fine Quantizer로 사용한 논문이다. 전력 소모를 극단적으로 줄이기 위해 residue amplifier를 사용하지 않고 coarse SAR ADC의 residue를 Ring TDC의 입력으로 그대로 받아서 사용하는 방법으로 저전력화를 꾀하였다. Foreground calibration을 이용하여 ADC출력을 combine하였고, 22nm공정으로 설계된 ADC는 260MS/s로 동작하며 60dB의 SNDR을 달성하였다.
#10.5 Session 10의 유일한 Industry 논문으로 Analog Device사의 24b 2MS/s SAR ADC에 대한 논문이다. 특이하게 입력신호가 2개의 별도의 16-bit single-ended SAR ADC로 변환되고 digital에서 differential 동작을 구현하였다. 두 single-ended ADC의 analog residue를 dynamic amplifier로 증폭하여 differential SAR ADC로 변환하여 최종적으로 code를 합친다는 점에서는 Pipelined SAR의 구조와 사실상 같다고 볼 수 있다. Single-ended ADC 두개를 사용함으로써 이 ADC를 drive하는 signal chain입장에서 common-mode에 대한 range를 넓게 사용할 수 있다는 장점이 있다. 24b의 선형성을 확보하기 위해 DEM과 Dithering을 CDAC에 사용하여 mismatch를 randomize하였고 180nm로 제작된 칩은 INL<0.03ppm이라는 최고수준의 선형성 측정 결과를 보였다.
#10.6 Dynamic Amplifier를 Incremental Zoom ADC에 사용한 논문이다. 기존의 Zoom ADC의 loop filter에 사용되는 적분기를 flipped inverting amplifier와 dynamic amplifier에 common-mode detector를 조합한 50dB 증폭기를 이용하여 저전력 설계하였다. 이를 통해 zoom ADC의 전력소모의 대부분을 차지하던 적분기 전력 소모를 대폭 절감할 수 있었다.
#10.7 Zoom ADC기반의 센서 ADC에 관한 논문으로 DWA(Data-Weighted Averaging)보다 하드웨어 구현이 더 간단한 Real-Time DEM (RT-DEM)이라는 Dynamic Element Matching 기법을 차용하였고 적분기에 기반한 Loop Filter대신 디지털 카운터를 이용하여 Fine Stage를 구현하여 미세공정에 더욱 적합한 아키텍쳐를 제안하였다. 28nm공정에서 설계된 ADC는 비록 50kS/s로 동작하지만 SNDR 100dB이상의 높은 선형성을 달성하였다.
Session 25. Noise-Shaping ADCs
#25.1 VCO Quantizer기반의 Open-loop ΔΣ ADC를 구현하였다. VCO기반 ADC는 기본적으로 입력이 아주 작은 범위내에서만 선형성을 가지기 때문에 Feedback을 사용한다고 해도 높은 선형성을 갖기가 어렵다. 본 논문에서는 Pseudo Virtual Ground (PVG) Feedforward Path를 채용한 새로운 3차 DSM구조를 발표하였고, 2.5kHz의 대역폭을 갖고 92dB의 SNDR을 달성하면서도 온도나 전압변화에 강인한DSM을 구현할 수 있었다.
#25.2 2차 MASH ADC에서 Digital Feedforward와 두번째 적분기의 출력을 다시 Quantize하는 Extended Counting기법을 동시에 사용하여 해상도의 확장을 시도한 연구 내용이다. 제안하는 구조 구현에 필요한 두 추가적인 경로의 Quantizer를 실제로는 동일한 SAR ADC를 재활용함으로써 하드웨어를 단순화하였다. 적분기는 Flipped Inverting Amplifier기반의 적분기로 설계하여 저전력 달성을 목표로 하였댜. 제안하는 설계 테크닉을 활용해 1kHz의 Bandwidth와 높은 전력 효율을 가지면서도 94dB의 SNDR을 달성하는 데이터 변환기를 설계할수 있었다.
#25.3 Pseudo-Pseudo Differential(PPD)라는 설계 기법을 Audio-band DSM 설계에 적용한 논문이다. 이 설계 기법은 Single-ended 적분기로 Differential 신호를 two-phase에서 다루는 기법으로 적분기 전력소모를 이론적으로 반으로 줄일수 있다. 실제 Amplifier의 설계는 Ring Amplifier를 사용하였고, 전체적으로는 3차 구조의 DSM에 multi-bit SAR quantizer를 이용하여 설계하였다. 측정결과 20kHz bandwidth에서 188dB의 FoM을 달성하여 높은 에너지 효율을 보였다.
#25.4 360MHz의 광대역을 갖는 MASH 1-1-1-구조의 CTDSM 논문으로 Passive Compensating Filter라는 설계 기법을 도입하여 적분기 내부 노드에 입력 성분이 유입되는 것을 제한하여 Interstage DAC을 제거하였고 동시에 backend stage의 선형성 requirement를 낮추어 간단한 Gm-C구조로 2번째와 3번째 backend stage를 저전력 설계할 수 있게 하였다. 40nm공정에서 설계된 프로토타입 칩은 5GHz로 동작하면서 360MHz의 대역폭에서 65dB의 SNDR을 달성하는 좋은 성능을 보였다.
#25.5 100MHz이상의 대역과 -100dBc이상의 THD를 목표로 하는 CTDSM 설계에 대한 논문으로 4차 DSM에 2-bit quantizer를 사용한 구조로 설계되었다. 높은 THD달성을 위해서는 DAC의 에러 교정이 필수적인데, 전통적으로 사용하는 DWA기반의 DEM을 쓰지 않고 DAC 오차를 디지털에서 Low-Pass Filter한후 교정하여 mismatch가 noise로 분산되는 문제를 해결하였다. Quantizer의 offset역시 background에서 교정하여 120MHz라는 광대역신호를 변환하면서도 -101dBc의 THD를 달성하였다.
#25.6 저전력 Noise-Shaping SAR를 구현하기 위해 Error-Feedback과 CRFF (Cascaded resonator feedforward)구조를 Hybrid로 사용하여 저전력 dynamic amp를 Loop Filter에 사용할 수 있게 하였다. 또한 input capacitor를 줄이기 위한 buffer를 SAR loop내에 내재하였는데, 이 버퍼를 kT/C 잡음을 줄이기 위한 preamplifier로 사용하여 전체적인 노이즈 성능을 개선하였다. 버퍼 증폭기로는 Push-Pull Source Follower (PPSF)를 사용하여 동작 속도를 개선하였고, 65nm로 제작된 칩의 측정 결과 500kHz의 대역폭에서 84.1dB의 SNDR이라는 높은 선형성을 확보하였고, 전력효율도 180dB를 상회하는 FoM을 달성하였다.
|
 |
|
| #Digital Architecture(System) |
|
ㆍSession 2 / Processors
|
|
디지털 VLSI 엔지니어의 관점에서 본 이번 ISSCC 학회는, 의도치 않게(?) 현재 디지털 시스템의 설계 경향이 어떤 방향으로 나아가고 있는지를 알려주었다고 생각한다. Synopsys Inc. 의 Aart de Geus CEO께서 첫 Plenary talk인 “Silicon, Software, and Smarts for the SysMoore Era”의 발표를 한 것에 주목한다. 한계로 가고 있는 무어의 법칙을 이어나갈 동력은 바로 ‘시스템 성장’이라는 것이다. 2022년도 디지털 시스템의 트렌드를 Session 2의 각 회사별로 분석해보았다.
Intel : Session 2에서 처음 발표된 논문은 Intel의 Ponte Vecchio다.[#2.1] 잘 생각해보면, 학회를 여는 첫 발표에서 Aart CEO 께서 SysMoore를 강조하고, 그에 대해 System(슈퍼컴퓨터급)을 이루는 첫 논문이 등장한다는 것은 너무 의도적이지 않은가. Ponte Vecchio는 Intel에서 설계한 슈퍼컴퓨터용 프로세서다. 여기서 주목할 점들부터 이야기하자면, 1) Xe core(GPU기반) 제작을 TSMC N5, 그리고 Xe Link Tile를 TSMC N7을 이용하였다. Intel의 최신공정이 더딘 것은 그리 놀라운 일이 아니지만 자신들의 flagship 슈퍼컴퓨터 칩에 대해 타사의 공정을 이용한 것이 얼마나 자존심이 상했을 지에 대해 짐작해본다. 2) 어마어마한 성능의 시스템이다. 이미 어마어마한 시스템에 대해 세부적인 스펙을 강조하는 것은 큰 의미가 없으니 넘어간다. 3) Aurora라는 서버 팜을 이용하여 > 2 Exaflops 라는 놀라운 연산을 이룰 수 있다는 것을 강조한다. 이 자체에도 몇 가지 의미부여를 할 수 있겠지만, 본인은 이러한 Ponte Vecchio 시스템을 통해 그동안 AI/ML등의 많은 연산을 필요로 하는 솔루션으로 그동안 Intel이 별로 두각을 드러내지 못한 것에 대해 GPU 아키텍처의 시스템을 출시하면서 당당하게 Nvidia 등과 제대로 한판 붙어보겠다는 의지를 드러낸 것으로 판단한다. 종합하자면, Intel은 전체적인 다목적 chip으로 구성한 system을 통해서 슈퍼컴퓨터 급의 시스템에 대한 전망을 잘 제시했다고 생각한다. Xeon 프로세서의 방향도 잘 제시했다.[#2.2] TSMC 공정이 아닌 자사의 Intel 7 공정을 사용하였으며, 4개의 칩을 하나의 package로 묶어서 시스템을 구성하였다. 충분한 병렬 연산이 이루어진다면, 굳이 하나의 chip을 크게 만들어서 yield 문제를 야기할 필요가 없으니, 좋은 선택이라 생각한다. 본 논문에서 주목할 점은 chip 자체가 아니라 오히려 package에 설계된 인덕터였다. Coaxial Magnetic Integrated Inductor이라는 이름의 인덕터는 패키지를 인덕터를 만드는데 최적화하여 좀 더 높은 Quality factor을 보유할 수 있도록 하였고, 측정을 통해 그 유효성을 입증하였다. 종합적인 Intel의 서버시장 공략에 대한 자신감을 나타낸 작품이었다.
|
 |
| [그림 1] Intel의 Ponte Vecchio 시스템 구성 |
|
IBM : Telum [#2.3]과 Power10 [#2.4]를 통해 IBM의 설계능력을 과시한 논문들이었다. Telum 프로세서는 IBM에서 새로나온 프로세서라기 보다는 기존의 Z15 (ISSCC20) 프로세서를 개선시킨 후속작이었고, 그 과정에서 극복해야 하는 기술적인 문제점들을 다룬 논문이었다. 우선, 14나노에서 7나노 공정으로 넘어가면서 물리적으로 감소하게 된 동작전압과 증가한 BEOL RC 딜레이가 주목할 점이었고, 작은 공정으로 넘어가면서 더더욱 전달하기 어려운 전력에 대해 언급하였다. Telum 설계시, 아키텍처 엔지니어들이 요구한 더욱 큰 캐시 용량 대비 그것을 어떻게 Physical design 엔지니어 들이 유의미한 범위 내에서 구현을 하였는지가 관건이 되었다고 생각한다. Telum에 설계된 cache 구조는 ring-type로 올해 ISSCC에 발표된 많은 chip들이 비슷한 cache 아키텍처를 사용하였으며, 자사의 cache 구조가 다른 chip들 대비 얼마나 더 효과적인 latency와 용량을 구현하였는지가 논문의 핵심이었다고 생각한다. 자체적으로 들어간 인공지능 가속기의 크기가 상대적으로 그리 크지 않은 것을 통해, 본 프로세서의 핵심은 AI 연산이 아니라는 것을 알 수 있었다. IBM의 Power10 프로세서는 16개의 코어를 통해 96개의 Thread를 연산할 수 있고 총 180억개의 transistor로 구성되어 있다. 놀라운 기술이 집적 되어있는 전통적인 서버 프로세서이다. 삼성의 7나노 공정으로 제작되어 있으며, 10개의 Voltage domain 등 Physical design에서 반드시 필요로 하는 기술들이 칩으로 구현되어 있다. 이 논문에서는 두가지에 주목하였다. 1) 칩 내에 사용된 메모리의 비중을 보면 상당히 높은 비중이 custom memory다. 2) 그리고 core의 leakage가 꽤 높다(약 20%). 전반적으로 높은 성능을 위해 설계된 Power10 프로세서에서 생각보다 낭비되는 전력이 높다는 것에 주목해볼만 했고, 나머지는 전통적인 chip 설계의 목표를 만족하는 논문이었다.
|
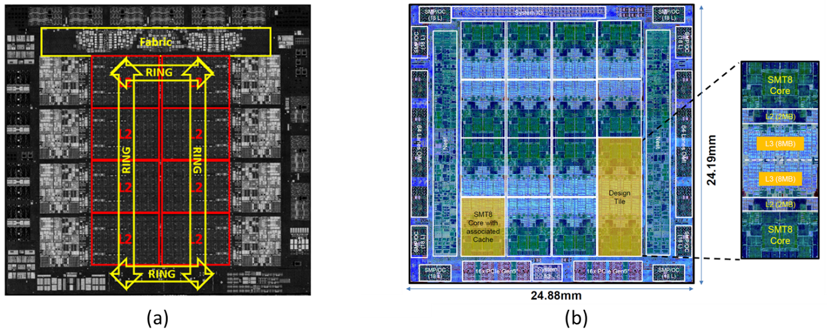 |
| [그림 2] IBM의 (a) Telum 프로세서, (b) Power 10 프로세서 |
|
Mediatek/AMD : 일반 소비자가 사용할 chip의 최신 설계 경향을 나타낸 논문들이 Mediatek과[#2.5] AMD를 통해 발표되었다.[#2.7] Mediatek은 3개의 다른 core architecture (Cortex-X2, Cortex-710, Cortex-510)을 통해 고성능과 저전력의 균형점을 찾았으며, Cortex-X2를 설계하기 위해 사용한 210nm 높이의 standard cell를 통해 철저하게 고성능 설계를 지향했다는 것을 알 수 있다. 그밖에 다양한 설계 기법을 동원하여 5G SoC 설계에 있어서 자사의 우위를 과시했다. AMD는 이번에 Zen3을 발표했는데, 주목할 점은 지난 Zen2와 동일한 7nm 공정을 사용하였다는 점이다. 따라서, Zen2 대비 공정의 장점을 갖지 못하는 Zen3의 아키텍처/회로적인 설계가 얼마나 더 나은 성능으로 이어지는지를 파악하는 것이 흥미로운 관전포인트가 되겠다. 우선, 전체적인 아키텍처의 관점에서 연산량을 늘리기 위한 시도들이 눈에 보인다. Chip 내의 버스 Bandwidth를 늘린다던지, 전체적으로 더 많은 연산을 수행할 수 있게 설계하였다. L3 캐시 설계에 ring bus를 도입한 점을 통해 (다른 회사의 cache들도 그렇게 설계하므로) 이제 이러한 ring bus가 L3 캐시 설계의 경향이라 이해하면 될 것 같고, 이번 설계에서 AMD 사의 3D V-Cache 기술을 도입하여 Cache 용량을 늘리기 위해 AMD가 얼마나 준비하였는지를 살펴보는 것이 또 하나의 관전포인트가 되겠다. Zen 3 의 키워드는 개인적으로 ‘최적화’라고 생각하며, 아키텍처적인 최적화 뿐만 아니라 Physical design의 최적화(floorplanning의 최적화, 사용한 standard cell들의 최적화 등)를 통해 전체적으로 향상된 성능(freq)과 전력효율 개선을 이루었다고 판단한다.
|
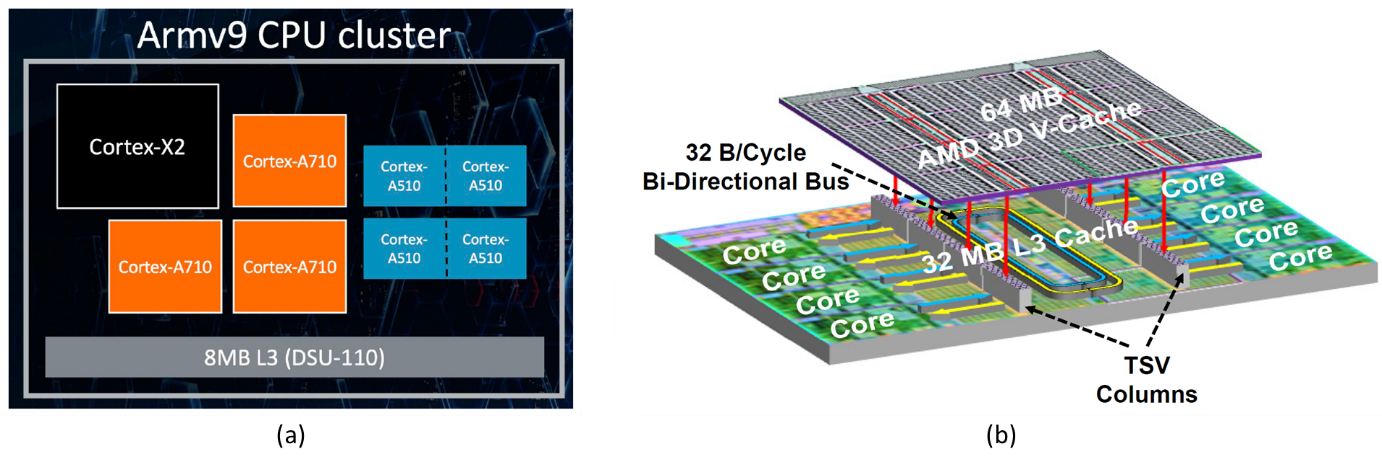 |
| [그림 3] (a) Mediatek chip의 ARM 프로세서 클러스터, (b) AMD Zen3의 아키텍처와 3D V-cache 구조 |
| #ML |
|
ㆍSession 15 / ML Processors
ㆍSession 29 / ML Chips for Emerging Applications
|
|
Machine Learning Processor는 ML Processors(#Session 15)와 ML Chips for Emerging Application(#Session 29) 총 두 개의 세션으로 구성되었다. ML Processor에서는 image classification, object detection, pose estimation 등 널리 사용되는 응용을 목표로 9개의 연구가 소개되었으며, ML Chips for Emerging Application에서는 recommendation system, transformer, spiking recurrent neural network 등을 위한 4개의 연구가 소개되었다. 총 13개의 논문 중 7개의 논문이 compute-in-memory (CIM) 기반이라는 점이 주목된다. 이 중 5개의 논문을 이번 후기를 통해 간략하게 살펴보고자 한다.
#15.3은 Fudan University에서 제안한 Computing-on-Memory-Boundary Neural Network processor이다. Weight memory 부근에 bit-wise multiplication을 위한 회로를 배치하여, 별도의 weight data movement 없이 CONV를 위한 MAC operation을 수행한다. Multiplication-Embedded Dynamic Latch on Memory Bound는 bit-wise로 동작하는 read-out, multiplier와 latch operation을 하나의 게이트로 구현하였으며, activation과 weight sparsity에 따라 동작함으로써 power efficiency를 증가시켰다. 논문에서는 제안하는 회로를 multi-chiplet-module로 구성하여 기존의 state-of-the-art CIM processor 대비 3.5x 낮은 system energy efficiency를 달성하였다.
|
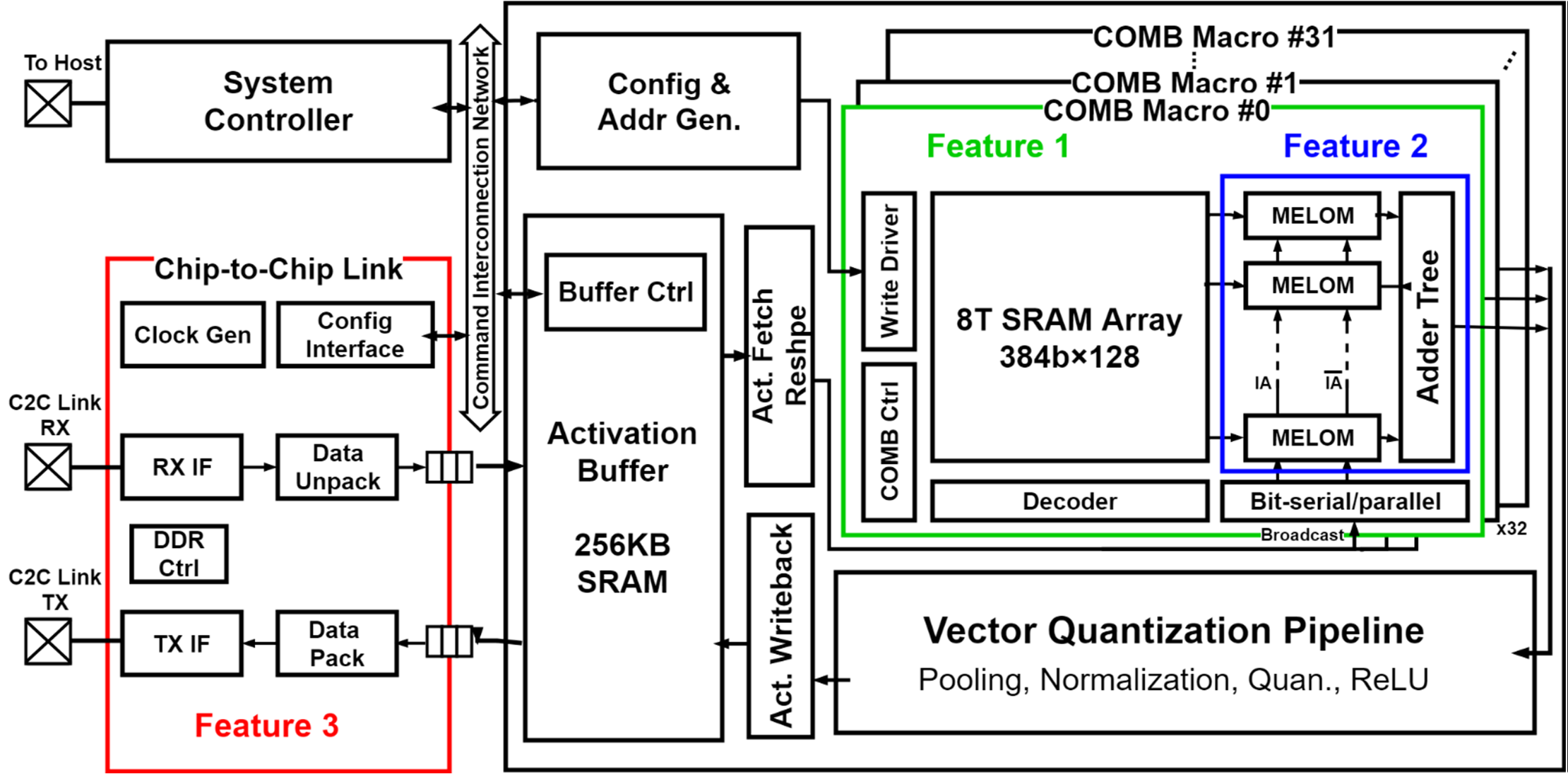 |
| [그림1] Chip-to-Chip 확장 고려한 COMB 구조 |
|
#15.5는 Tsinghua University에서 제안한 재구성 가능한 디지털 CIM 프로세서로 높은 연산 정확도가 요구되는 cloud DL을 목표로 한다. Floating Point (FP) 지원을 위한 data alignment logic을 메모리 내부에 배치할 경우, 면적 및 에너지 효율이 감소하기 때문에 기존의 CIM 논문에서는 주로 integer (INT) 연산을 지원하였다. 하지만 해당 논문에서는 input alignment logic을 CIM Macro 외부에 배치한 reconfigurable CIM 구조를 제안하여 동일한 dataflow을 통하여 FP와 INT 연산을 모두 지원한다. 또한 reconfigurable in-memory accumulator는 BFloat16/FP32 그리고 INT8/16을 동일한 CIM macro 내에서 연산할 수 있도록 하였다. CIM 내부의 연산 방식으로는 Booth multiplication algorithm 방식을 채택하여 기존의 bit-wise multiplication 대비 cycle count를 50% 감소시켰다. 결과적으로 최근 FP 연산을 지원하는 CIM processor 대비 20.42x 높은 29.2 TFLOPS/W의 에너지 효율을 달성하였다.
#15.6은 KU Leuven에서 제안한 DIANA 프로세서로 digital NN acceleration의 장점인 dataflow flexibility와 Analog in-Memory Computing (AiMC)의 장점인 에너지 효율을 모두 갖춘 low-power hybrid NN processing SoC이다. Digital NN core에서는 첫 번째 layer의 high-precision CONV 연산과 FC Layer 연산을 담당하며, AiMC core에서는 이외의 CONV layer 연산 담당한다. AiMC 내부의 SIMD module은 digital post-processing을 지원하여 memory traffic과 latency를 감소시켰다. 또한 한번 load 된 activation tile에 대하여 모든 layer 연산을 우선으로 수행하는 layer fusion 기법을 적용하여 latency를 약 40% 감소시켰다. 하지만 weight data load를 위한 bandwidth 충분히 확보하지 못하여 AiMC의 utilization이 낮을 때 더 높은 시스템 성능을 보이는 아쉬움이 있다.
#15.7은 KAIST에서 발표한 ARCHON으로 analog Neuronal computation unit (ANU)와 Analog Memory (AMEM)를 활용하여 CNN model 연산 과정에서 모든 layer에 걸쳐 A/D domain conversion 없이 analog domain만으로 연산하는 CNN processor이다. AMEM은 metal-oxide-metal cap과 unity-gain buffer로 구현되어 read/write operation 간의 path를 분리했다. 또한 analog processing의 문제점인 variation을 해결하기 위하여 AMEM에서는 write-with-feedback 구조를, ANU에서는 voltage-to-time converter를 활용한 연산방식을 적용했다. ARCHON은 332.7 TOPS/W의 높은 에너지 효율의 달성함과 동시에, variation에 의한 정확도 저하가 0.7%밖에 되지 않는 것이 인상적이었다.
|
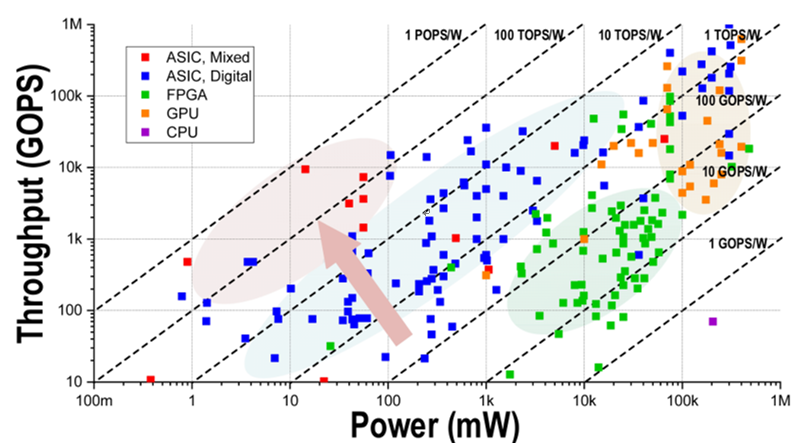 |
| [그림2] Analog Computing과 기존의 연산 장치 간의 에너지 효율 비교 모식도 |
|
#29.3은 Tsinghua University에서 발표한 논문으로 transformer의 attention mechanism을 CIM을 통해 가속한다. 해당 CIM 프로세서는 two-stage-pipeline을 통해 transformation의 attention layer를 INT16으로, FC Layer에서는 INT8로 연산한다. 또한 QKT pipeline 과정에서 필요한 transpose buffer를 bitline-transpose 구조를 통해 해결함과 동시에 sparse attention scheduler를 통해 불필요한 연산을 제거하였다. 이를 통해 최대 20.5 TOPS/W 달성하였으며, 각 연산 단계에서 정확도 손실을 최소화하면서 에너지 효율적인 연산에 집중한 것이 주요 아이디어이다.
|
| #Memory |
|
ㆍSession 7 / NAND Flash Memory
ㆍSession 11 / Compute-in-Memory and SRAM
|
|
최근 빅데이터 처리 및 인공지능 분야가 산업계와 학계에서 주요 이슈로 등장하면서 메모리 분야가 시스템에서 핵심적인 영역으로 다시 성장하고 있으며, 산학계에서 모두 관심도가 증가하고 있다. 이러한 현상이 반영, ISSCC 2022에서 전년대비 5편 증가된 21편의 논문이 발표되었다.
#Session 7 (NAND Flash Memory) 의 5편은 모두 기업체에서 발표했으며, 1Tb NAND Flash 4편의논문은 웨스턴디지털, 마이크론, SK하이닉스, 삼성전자에서 각각 발표했고, 대만 Macronix사에서 NAND Flash를 이용한 In-Memory-Computing 논문을 발표하였다.
#7.1 논문에서는 웨스턴디지털과 키옥시아가 공동 참여했고 162단 레이어를 사용한 1Tb QLC(4bit/cell) NAND로서 15 Gb/mm2의 bit density를 가지며, 2.4Gb/s의 IO 속도를 제공한다.
#7.2 논문에서는 마이크론에서 발표한 176단 레이어의 QLC로서, quad-plane동시 read를 제공했으며, dual verify방식을 사용하여 프로그램 속도가 향상되었다. 또한, #7.3 논문은 SK하이닉스에서 발표했고, 176단 레이어를 사용하여 14.8 Gb/mm2의 bit density를 가진다. 최적 read 레벨을 찾는 알고리즘 사용으로 read bit error rate가 향상되었다.
#7.4 논문에서는 삼성전자에서 TLC(3bit/cell)와 220단 레이어를 이용하고, CMOS under array기술을 사용해 11.6 Gb/mm2의 bit density를 달성했고, 164MB/s의 write throughput특성을 가진다. #7.5 논문에서는 대만 Macronix에서 발표한 기술로, face recognition시 유사한 vector matching을 위해 NAND Flash를 이용 CIM(Compute-in-Memory)를 구현했으며, latency를 향상하기 위해 pooled sampling기술을 사용했다. 참고로 수년 전 NAND Flash는 용량을 증가시키는 추세가 있었으나, 최근에는 용량을 유지하면서 성능을 향상시키는 추세가 있다.
#Session 11 (Compute-in-Memory and SRAM) 논문은 기업체가 3편(SK하이닉스 1, TSMC 2) 발표를 했고, 대만 칭화대가 3편, 북경대가 2편을 발표했다. #11.1 논문에서는 SK하이닉스가 GDDR6기반으로 Accelerator-in-Memory를 발표했다. 딥러닝 동작의 다양한 명령셋을 제공하며, 8Gb용량으로 1TFLOPS와 1GHz의 MAC동작을 구현한다. #11.2 논문에서는 칭화대에서 4Mb STT-MRAM을 사용하여 NMC(near memory computing) macro를 구현하였으며, 내부 2.3K bus를 이용 192GB/s read와 8b-input, 8b-weight, 26b-output MAC동작에서 25.1~55.1 TOPS/W를 달성했다. #11.3 논문에서는 TSMC에서 40nm PCM(phase change memory) CIM macro를 구현했으며, 2Mb macro로 8b-input, 8b-weight, 26b-output로 20.5~60 TOPS/W를 달성했다. #11.4 논문은 칭화대에서 8Mb ReRAM을 이용하여 CIM macro를 구현한 것으로, DC 전류가 최소화된 time-domain MAC기술이 적용되었다. #11.5 논문은 북경대에서 발표한 6T-SRAM논문으로, 누설전류를 최소화한 것이 특징으로, keeper supply rail을 이용, 256Kb 에서 2.53fW/bit의 leakage를 구현했다. #11.6 논문은 TSMC에서 발표한 fully digital방식의 CIM macro로서, 4b-input 4b-weight 14b-output MAC동작에서 254 TOPS/W를 달성했다. #11.7 논문은 북경대에서 발표한 dynamic logic과 SRAM에 기반한 digital방식의 CIM Macro이고, #11.8 논문은 칭화대에서 발표한 1Mb SRAM-CIM macro로서 time domain accumulation방식을 이용한 TDC(time-to-digital converter)방식으로 구현되었다. CIM은 메모리 분과에서 점점 영역이 확대되는 추세이며, 수년 전에는 대학과 연구소에서만 논문을 발표했지만, 최근에는 삼성전자, SK하이닉스, TSMC등 주요 기업에서도 참여를 시작하고 있다.
#Session 28 (DRAM and Interface) 논문은 기업체 3편(SK하이닉스 1, 삼성전자 2)을 비롯, 포항공대 2편, 고려대 1편, 서울대 1편, KAIST 1편을 발표했다. #28.1 논문에서는 SK하이닉스가 HBM3를 최초로 발표하였고, TSV auto-calibration, In-DRAM ECC, NN-DFE 등의 기술을 적용하여 최대 896GB/s의 대역폭을 달성했다. #28.2 논문에서는 삼성전자가 T-coil기반으로 IO속도를 향상시키고, quad skew training을 최적화하여 현재 DRAM에서 가장 빠른 27 Gbps의 핀속도를 달성했다. #28.3 논문에서는 삼성전자가 신규 Mobile DRAM표준 제품인 LPDDR5X를 발표하였고, extended DVFSC (dynamic voltage frequency scaling)와 stacked transmitter기술이 적용되어 9.5Gbps의 속도를 달성했다. #28.4 논문에서는 포항공대에서 single-ended기반의 20 Gbps transmitter를 발표했고, 신규 기술인 inverter기반의 4-tap addition-only FFE를 사용하여 robustness를 강화한 것이 특징이다. #28.5 논문에서는 고려대에서 TIA(trans-impedance amplifier)기반의 Di-code transceiver를 발표했고, static전류를 최소화한 것이 특징이며 0.385pJ/b의 energy efficiency를 달성했다. #28.6 논문에서는 서울대에서 커패시터 구동방식의 transceiver를 발표했고, FFE와 ground-force bias기술로 78.8 fJ/bit/mm의 energy efficiency의 특성을 가진다. #28.7 논문에서는 포항공대에서 single-ended기반의 20 Gbps의 DECS(data-embedded clock signaling)기술을 발표했으며, 1.24pJ/b의 energy efficiency를 달성했다. #28.8 논문에서는 KAIST에서 supply-noise induced jitter(SIJ) 제거 기술을 발표했으며, LMS 알고리즘을 기반으로 CDN과 TX/RX영역의 jitter를 제거한 것이 특징이며, 특히, LPDDR5의 RDQS의 RMS jitter를 80%개선하여 6.4Gbps에서 4배의 data eye를 확보하였다. DRAM은 주요 기업체가 신제품의 기술을 매년 발표하고 있으며, 최근 DRAM의 bandwidth 향상이 크게 요구되어, 다양한 interface 한계 극복 기술이 필요해서 학계의 관심도가 증가하고 있다.
|
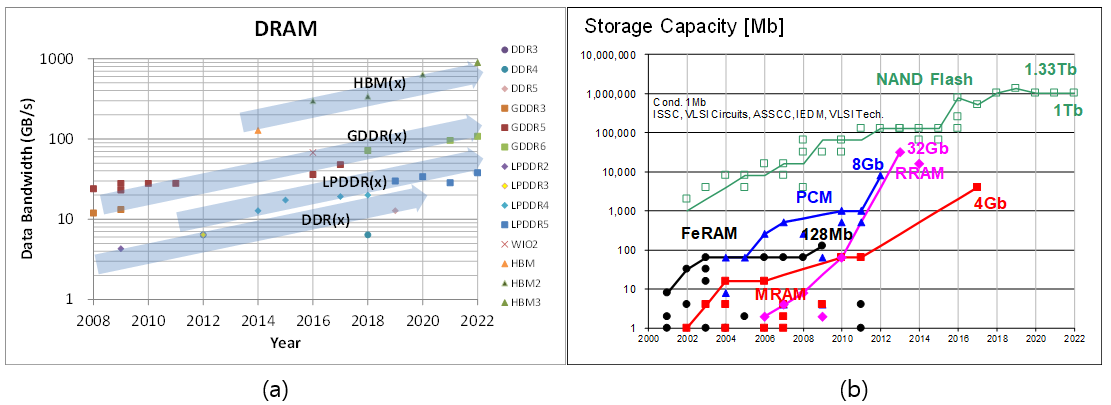 |
| [그림 1] 메모리 연도별 트렌드 (a) DRAM Bandwidth (b) Nonvolatile Memory Density |
|
|







