| #Analog Circuits and Systems |
|
ㆍSession 2 / Power Conversion & Wireless Power Transfer
|
|
본 글은 Session 2에 대한 리뷰이다.
ASSCC 2021의 power conversion 분야에서는 여러 구조의 컨버터가 소개되었는데, 논문의 연구 방향은 컨버터의 자체 손실을 줄임으로써 전체 시스템의 효율 개선, 높은 효율을 유지하며 작은 사이즈로의 설계로 요약할 수 있다.
마찬가지로 wireless power transfer (무선 전력 전송) 분야 역시 시스템의 소형화에 대한 요구가 있으며, 동시에 Rx 단의 빠른 충전을 위해 큰 입력 파워를 견딜 수 있는 시스템에 대한 연구가 이루어졌다. 소형화에 대한 요구는 전력 변환 시스템을 웨어러블 장비 또는 IoT 센서 등에 범용적으로 활용하기 위한 일환으로 볼 수 있다.
|
|
#S2.1 An Arithmetic Progression Switched-Capacitor DC-DC Converter with Soft VCR Transitions Achieving 93.7% Peak Efficiency and 400 mA Output Current
Switched-capacitor (SC) DC-DC 컨버터 높은 power conversion efficiency (PCE) 및 power density를 보이며 스위칭을 통해 다양한 voltage conversion ratio (VCR)을 만들 수 있다. 그러나 VCR transition 과정에서 capacitor의 전압 불균형으로 인한 charge redistribution loss가 발생해 효율이 저하되는 문제가 있다. 그리고 기존 구조는 two-phase 동작에서 각 phase 동안 전달되는 전하의 불균형이 크기 때문에 출력 전압 ripple이 증가하는 문제가 있다.
본 논문에서는 등차수열 SC 컨버터 구조를 제안해, 총 n-1개의 flying capacitor가 사용되고 각capacitor의 steady-state 전압은 입력 전압의 1/n에 해당하는 등차수열 관계로 self-balance된다. 이로 인해 각 capacitor에 걸리는 전압이 VCR에 관계없이 고정 전압을 띄게 되어 전압 rebalance 영향을 제거하였다. 제안하는 구조는 각 phase에서 전달하는 전하량이 거의 동일하여 quasi balanced 전하 전달 특성으로, single-branch 구조만으로 출력 전압 ripple을 줄일 수 있고 dual-branch 구조 대비 사용된 수동 소자의 개수도 줄일 수 있었다. 제안하는 soft VCR transition구조는 5:1, 5:2, 5:3, 5:4의 VCR을 지원하며, 5:3 ↔ 5:4 VCR을 100kHz 및 250kHz의 주파수에서 transition할 때도 평균 89% 및 87%의 PCE를 유지하는 결과를 얻었다. 최대 PCE는 93.7%이며 single-branch 구조만으로 출력 전압 ripple 50mV이하를 달성하였다.
|
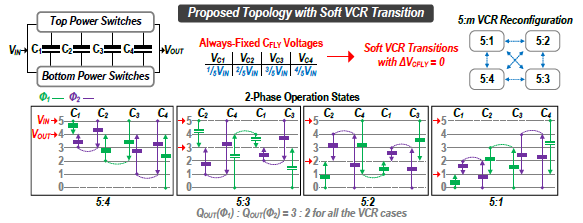 |
| [그림 1] 제안하는 soft VCR transition SC DC-DC 컨버터의 topology |
|
#S2.2 A 95% Peak Efficiency Modified KY (Boost) Converter for IoT with Continuous Flying Capacitor Charging in DCM
DC-DC 컨버터의 연구는 넓은 부하 범위, 높은 효율에 대한 연구 뿐만 아니라 더 큰 전압으로 증폭시키는 등의 방향으로 다양한 구조가 연구되었으며, 그중 KY converter는 charge pump를 결합시켜 전압 증폭 비율을 높인 구조이다. 하지만 flying capacitor의 충전 시간이 discontinuous conduction mode (DCM) 동작 과정에서 인덕터의 방전 시간으로 제한되어 완벽히 충전되지 못해 출력 부하 범위가 제한되고 효율이 저하되는 문제가 있다.
본 논문에서는 인덕터와 flying capacitor를 decoupling시키도록 인덕터에 직렬로 power switch를 추가해 DCM 동작으로 인덕터 전류가 차단된 동안에도 입력에 의한 충전이 가능해져 capacitor가 완벽하게 충전이 가능한 구조를 제안했다. 추가한 power switch를 이용해 기존 대비 정확한 zero-crossing detection이 가능해져 DCM 동작이 개선되었다. 그리고 인덕터 최대 전류를 기존 보다 작게 제한해 flying capacitor 충전 전류로 인한 손실을 줄여 효율을 개선하고, 부하 전류 크기에 따라 연결되는 power switch 개수를 조절함으로써 가변 width switch를 구현해 더 넓은 부하 범위에서 높은 효율을 보장한다. 이를 통해 0.001~100mA의 넓은 부하 범위와, 실제 칩 면적 0.158mm2, 부하 전류 1mA에서 최대 95%의 효율을 달성하였다.
|
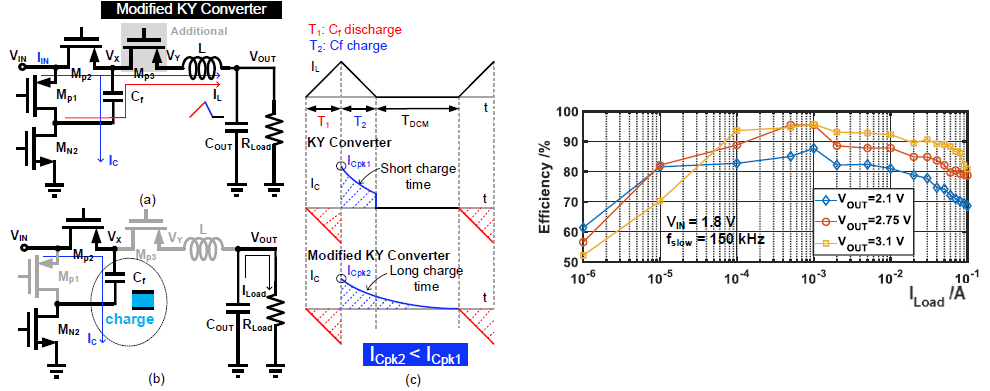 |
| [그림 2] (좌) 제안하는 개선된 KY 컨버터 구조. (우) 넓은 부하 범위에서의 효율 측정 결과. |
|
#S2.3 A 87.2%-Efficiency 27.12MHz Current-Mode Wireless Power Receiver with Ramp-Assisted Energy Delivery Controller for Implantable Devices
무선 전력 전송 기술은 Rx coil의 빠른 충전과 높은 효율을 위해 큰 입력 파워를 견디고 높은 공진 주파수에서 동작을 요구한다. 기존 시스템은 동작 주파수, 효율, 최대 허용 전압 간의 trade-off가 존재한다. 또한 컨트롤러 자체 delay로 인해 충전 시간이 짧아지는 문제도 있으며 특히 높은 공진 주파수에서 동작하거나 큰 사이즈의 power FET을 사용하면 영향이 증가한다.
본 논문에서는 double scaling down circuit (DSDC)을 이용해 LC 공진 tank를 위한 capacitor의 역할과 공진으로 증폭된 전압을 scaling down한 두 개의 전압으로 나누어 넓은 범위의 입력 파워에 대해서도 low-voltage 트랜지스터의 동작 신뢰성을 보장하여 트랜지스터의 사이즈를 줄여서 소형화하였다. 그리고 기존 방식은 공진 이후 전압이 최대가 되는 지점에서 trigger하는데, 컨트롤러 delay에 의해 실제 충전 시간이 제한된 반면, 제안한 구조는 ramp-assisted energy delivery controller (RA-EDC)를 이용하여 인덕터 전류가 최대가 되는 지점 즉, 기존 대비 3/4 cycle 미리 trigger하여 더욱 긴 충전 시간을 확보해 효율을 개선하였다. 그 결과 충전 시간은 16nsec이며 이는 공진 주기의 43.4%에 해당돼 기존 대비 긴 시간 충전이 이루어졌고, 허용 최대 입력 파워 312mW이며 최대 효율은 87.2%를 달성하였다.
|
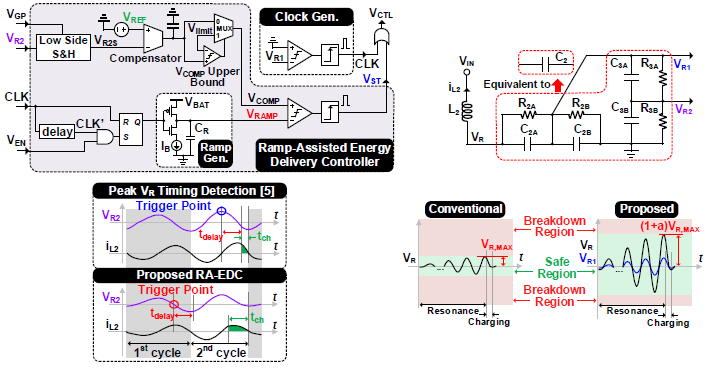 |
| [그림 3] (좌) RA-EDC 구조 및 그에 따른 동작 파형. (우) DSDC 구조 및 그에 따른 동작 파형. |
|
#S2.4 A 5.7GHz RF Wireless Power Transfer Receiver Using 84.5% Efficiency 12V SIDO Buck-Boost DC-DC Converter with Internal Power Supply Mode
무선전력전송을 통해 큰 파워를 전송하기 위해서는 Tx, Rx 단에서 높은 전압을 견딜 수 있는 컨버터가 필요하다. 동시에 입력이 작은 경우에도 효율적으로 동작하기 위해 컨트롤러의 전력 소모 최소화가 필요하며, 심지어는 입력이 없더라도 기능을 상실하지 않고 다음 입력을 대비하는 기능도 필요하다.
본 논문에서는 power stage와 gate driver 구동 전원과 컨버터 컨트롤러 전원을 분리하고, 컨트롤러 회로는 저전압으로 구동해 전력 소모를 줄였다. 입력 파워가 충분히 클 경우에는 single-input dual-output (SIDO) buck-boost 컨버터로 작동하고, 내부에서 생성된 낮은 전압으로 컨트롤러를 구동한다. 입력이 없을 경우 부하단의 배터리가 컨트롤러 전원을 공급하는 internal power supply (IPS) 모드로 동작한다. 높은 전압을 견디기 위해 HV 트랜지스터를 사용하고 reverse current에 의한 오동작 방지 구조로 동작 신뢰성을 향상시켰다. 그 결과 RF 입력 파워 범위는 6~19dBm, 입력 전압 범위 1.4~10V의 넓은 입력 범위를 가지며, 컨트롤러는 1.5V에서 동작해 전력 소모를 줄였다.
|
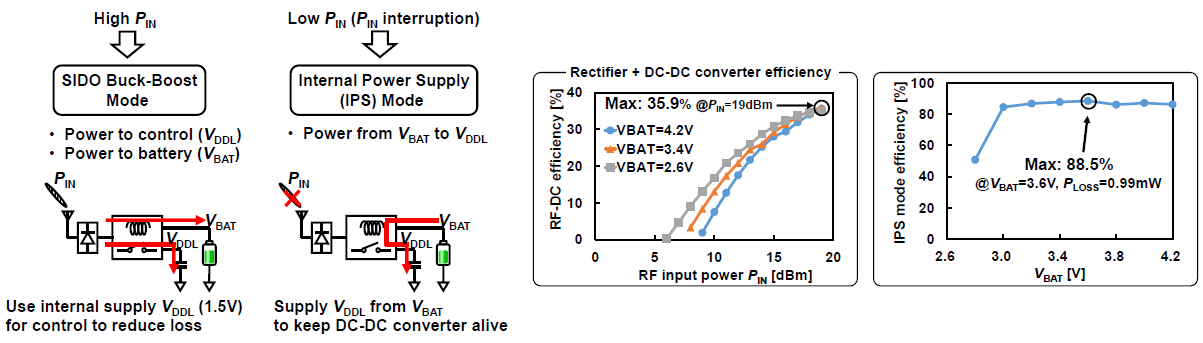 |
| [그림 4] (좌) 제안한 회로의 SIDO 모드 및 IPS 모드에서의 구조. (우) 정류기 및 buck-boost 컨버터 효율 측정 결과. |
|
#S2.5 A Multi-phase Series-Parallel with Bond Wire Auxiliary Fully-Integrated 250pF Switched-Capacitor with 13.6mV output ripple for Supplying Temperature Sensor with 0.1°C Accuracy to Early Detect COVID-19
웨어러블 디바이스 센서 전원 공급용 switched-capacitor (SC) 컨버터를 fully integrated 형태로 만들기 위해서는 flying capacitance, output capacitance의 합이 250pF이하를 만족해야 한다. 그리고 센서 감지 정확도를 만족하기 위해서는 SC 컨버터 출력 전압 ripple이 충분히 작아야 하는데, 동시에 output capacitor도 충분히 작아야 하기 때문에 동작 클락 주파수가 수십 GHz까지 높아지는 문제가 있다.
본 논문에서는 bond wire 인덕터(LBOND) 보조 SC 컨버터를 제안한다. Power stage가 LBOND 스위칭 네트워크와 SC 컨버터 네트워크로 구성되어 있고, multi-phase 동작으로, phase B 동안 LBOND가 SC 컨버터와 입력 전압을 이어주고, phase A 동안에는 LBOND가 입력과 출력을 직렬로 연결해 current injection이 이루어져 출력 전압 ripple을 감소시켰다. 출력 전압 ripple이 감소하여 동작 클락 주파수를 충분히 낮출 수 있어 스위칭 loss가 감소하고 효율이 개선되었다. 3개의 동일한 power stage가 120o phase차이로 동작하는데, 각 power stage 간의 bond wire mismatch에 의한 출력 전압 fluctuation을 해결하기 위해 phase A, B를 정하는 duty-cycle 생성회로 calibration 기능을 추가하였다. 그리고 부하 전류에 따른 출력 전압 ripple을 최소화할 수 있는 flying capacitor 및 output capacitor 간의 비율을 조절하는 binary flying capacitor scaling (BFCS) 메커니즘을 이용해 ripple을 더욱 감소시켰다. 전체 칩 사이즈는 0.07655mm2로 fully integrated 형태이며, 최대 전류 밀도 및 전력 밀도는 각각 0.261A/mm2, 0.248W/mm2의 결과를 얻었다.
|
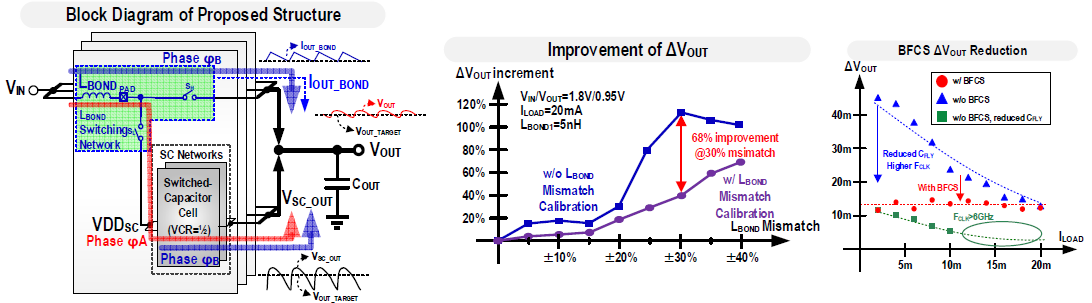 |
| [그림 5] 제안하는 bond wire 인덕터 보조 SC 컨버터 구조. Calibration 및 BFCS에 따른 출력 전압 ripple 감소 결과. |
| #Data Converters |
|
ㆍSession 10 / SAR-based Hybrid ADCs & TDC
ㆍSession 14 / Performance Enhancement Techniques for Oversampled ADCs
|
|
2021년 ASSCC에서 발표 된 Data converter관련 논문들은 session 10, 14에 실렸다. Session 10 (S.10)에는 SAR-based hybrid ADCs 와 TDC가 있으며 session 14 (S.14)에는 Oversampled ADCs의 성능을 높이기 위한 다양한 technique들이 소개되었다. S.10에서는 hybrid ADC는 noise shaping SAR ADC, input-buffer embedded pipelined SAR ADC, flash-assisted SAR ADC, 3-stage pipelined SAR ADC가 순서대로 소개 되었다. S.14에서는 oversampled ADC들이 겪는 stability 문제를 해결하며 ADC의 성능을 올릴 수 있는 MASH구조를 활용한 논문들이 여러 편 소개되었고 Input-Referred KT/C noise reduction 기술을 사용한 switched capacitor delta sigma ADC와 Tri-level Feedback 구조를 사용한 VCO-based delta sigma ADC, 그리고 input pre-conversion 기술을 이용한 4차 CT DSM이 소개되었다.
Session 10의 Noise shaping SAR ADC는 SAR ADC의 장점과 Delta Sigma ADC의 장점을 합치기 때문에 power efficiency 하며 high resolution 을 갖는 특징이 있다. S.10.1에서는 PVT 변화에 민감하지 않은 open loop voltage time voltage 변환기를 사용하여 noise shaping SAR ADC를 만들었고 active gain의 이점을 살려 active residue 처리방법을 선택하였다. 그 결과 1v supply voltage와 10MS/s sampling rate에서 173.2dB의 Schreier FoM과 14.2fJ/conversion-step의 Walden FoM을 얻었다. S.10.2에서는 pipelined-SAR ADC의 residue amplifier가 갖는 power 문제와 open-loop amplifier의 복잡한 calibration 과정을 없애기 위하여 dual-residue pipelined 구조를 활용하였다. 그 결과 input buffer power를 제외한 Nyquist input에 대한 FoM으로 80MS/s에서 31.34fJ/conversion step, 120MS/s에서 38.1fJ/conversion step을 얻었다. S.10.3에 소개된 flash-assisted SAR ADC는 1.75GS/s의 아주 빠른 conversion speed를 위해서 만들어졌다. 빠른 ADC를 만들기 위해서는 time interleaved 기술도 사용하지만 이 경우 power를 많이 쓴다는 문제점이 있다. 본 논문에서는 이러한 문제를 해결하기 위하여 single channel, flash-assisted SAR ADC를 활용하여 다른 논문들에 비해 현저히 낮은 power 소모를 달성하였으며 그 결과 1.75GS/s에서 41.1 fJ/conversion-step의 Walden FoM을 얻게 되었다. S.10.4 에서는 7T-dynamic residue amplifier를 사용하여 3-stage의 pipelined SAR ADC를 만들었다. Pipelined SAR ADC는 residue amplifier가 반드시 필요한데 종종 residue amplifier가 power bottleneck으로 작용한다. 이 논문에서는 power consumption을 낮추기 위하여 dynamic amplifier를 사용하였으며 dynamic amplifier가 갖는 문제점을 해결하기 위하여 kickback-cancelling 기술을 활용하였다. 그 결과 1.55mW의 power 소모와 800MS/s 에서 17.4fJ/conversion step 의 Walden FoM을 얻었다. S.10의 마지막 논문은 SAR ADC가 아닌 phase interpolation을 사용한 time-to-digital converter가 소개 되었다. 이 방식으로 0.015mm2의 작은 면적을 차지하며 1V supply에서 5mW 파워 소모와 1.5GS/s에서 0.11pJ/conversion step의 FoM을 얻었다. 21년 ASSCC s.10에 발표된 SAR-based hybrid ADC는 다양한 기법을 사용한 논문들로 구성되었다.
 |
| [그림 1] S10에 소개된 SAR-based hybrid ADC 구조들 |
| (a) S10.1 의 top schematic |
(b) S10.2의 top schematic |
(c) S10.3의 top schematic |
Session 14에서 소개된 첫 논문은 2nd order feedforward continuous-time incremental ADC 와Nyquist-rate SAR ADC를 결합한 hybrid two-step ADC 이다. 일반적인 MASH 구조에서는 첫 번째 스테이지의 quantizer의 입력에서 quantization error를 추출한 뒤 다음 스테이지로 넘기지만 소개된 논문에서는 residual error를 마지막 적분기의 출력에서 추출한 뒤 SAR ADC로 넘기는 전략을 취했다. 따라서 1MHz bandwidth에서 90.5dB의 넓은 DR을 가져갈 수 있었다. S.14.2에서는 새로운 sturdy MASH 구조가 소개되었다. 기본적으로 MASH구조는 noise-shaping의 차수를 3차 이상으로 가져가가고 싶은데 stability 문제를 해결하기 위해서 많이 사용한다. 하지만 stage간의 연산을 위해서 digital filter를 사용하게 되는데 이때 digital filter를 제거하고 바로 연산을 하는 것이 sturdy MASH 구조이다. 이 논문에서는 첫 번째 단의 quantization error를 추출하기 위해 필요했던 DAC을 제거하며 cascaded loop 안에 있는 feedback DAC을 제거함으로써 새로운 dual-loop sturdy MASH 구조를 제시하였다. 그 결과 18.75MHz BW에서 73.4dB의 SNDR과 17.85mW의 파워 소모를 달성하여 163.6dB의 Schreier FoM과 124.1fJ/conv-step의 Walden FoM을 얻었다. S.14.3에서는 switched-capacitor를 사용한 delta sigma ADC가 소개되었는데 input-referred kT/C noise reduction 기술을 활용하여 기존에 큰 값이 요구되었던 capacitor의 크기를 줄일 수 있었다. 따라서 180.4dB의 Schreier FoM을 얻으면서 0.022mm²의 면적을 차지하는 칩을 만들었다. S.14.4 논문은 합성가능한 VCO-based delta sigma modulator가 소개되었다. 특징으로는 Tri-level feedback 구조를 컨트롤 알고리즘을 통해서 합성하여 사용했다는 것이다. 그 결과 28nm CMOS 공정을 사용하여 0.006mm²의 면적을 차지하고 1.15mW 의 파워 소모와 5.33MHz의 BW에서 67.2dB의 SNDR을 달성하였다. 다른 논문들과 비교하였을 때 합성 가능한 ADC중 가장 작은 면적을 차지한다는 것이 특징이다. S.14의 마지막 논문은 pre-conversion method를 사용하여 4차 CT I-DSM에서 생기는 stability 문제를 해결하였다. 차수가 높은 incremental CTDSM에서 생기는 문제점 중 하나는 CT loop delay로 인해서 integrator가 reset 되었음에도 불구하고 quantizer output에 반영이 늦게 되어 integrator에 초기 error로 적용된다는 것이다. 이를 pre-conversion 방법으로 해결하여 32MHz의 sampling frequency와 64의 OSR을 가지고 78.5dB의 SNDR을 얻어 158.3dB의 FoM을 달성하였다.
 |
| [그림 2] S14에 소개된 oversampled ADC를 위한 다양한 기법들 |
| (a) S14.1 의 block diagram |
(b) S14.2의 block diagram |
(c) S14.4의 합성 알고리즘 |
2021년 ASSCC에 나온 data converter는 한 종류의 ADC를 사용하는 것이 아닌 여러가지 ADC를 섞어서 사용하는 경우가 많았다. 이를 보면 앞으로도 two-step 혹은 MASH구조 같이 이전 ADC들이 가지는 장점들을 섞어서 쓰기 위한 연구들이 많이 진행 될 것으로 보인다.
|
 |
|
| #Digital Circuits and Systems |
|
ㆍSession 3 / AI & Vision Processors
|
|
ASSCC 2021에 소개된 논문을 통해, 현재 Artificial intelligence (AI)와 Vision processors 분야에서는 이전보다 더 높은 에너지 효율성과 정확성을 목표로 연구가 진행되고 있음을 짐작할 수 있다.
우선, 많은 AI application에서 중요한 역할을 하고 있는 Deep neural network (DNN)의 효율성을 높이기 위해 DNN 내부에 있는 Multiply and accumulation (MAC) 회로의 성능이 우수해야 한다. 최근에는 저전력과 높은 처리량을 위해 디지털 회로가 아닌 아날로그 회로로 구성된 MAC에 대한 연구가 진행되고 있지만 효율성이 충분치 않았다. 이러한 아날로그 MAC의 문제점을 해결하기 위해 Session 3.1에서는 아날로그와 디지털 회로를 혼합한 FlashMAC 구조를 제안하였다. 해당 구조는 input 크기가 작을수록 처리속도가 더 빠른 특성을 가지고 있어, Loose synchronization (LS)를 도입할 경우, 기존에 있던 MAC 대기시간에 비해 크게 줄어드는 것을 확인할 수 있다. 결국, FlashMAC을 통해 기존 MAC에 비해 에너지 효율성을 더욱 향상시키는 성과를 나타냈다.
|
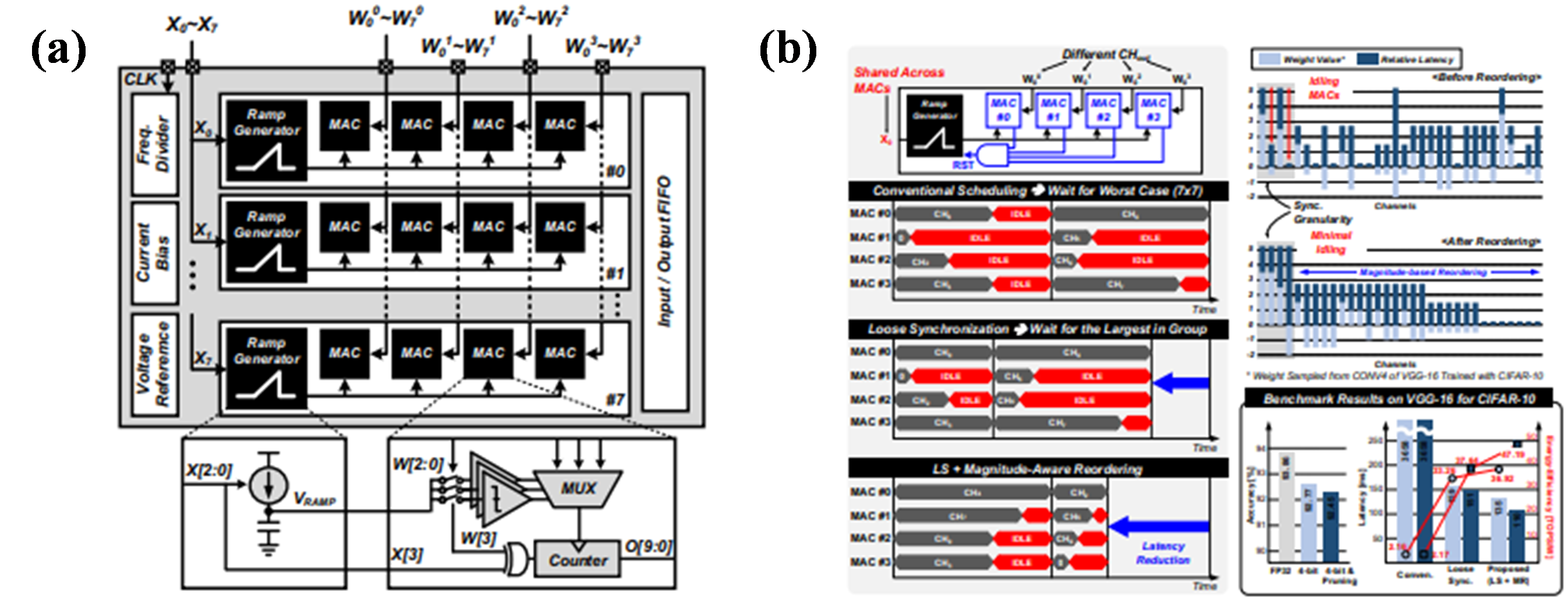 |
[그림 1](a) Overall the proposed FlashMAC architecture,
(b) Magnitude-aware reordering with loose synchronization |
|
이러한 에너지 효율성은 고화질 디스플레이 분야에도 요구되고 있다. Display stream compression (DSC) encoder가 휴대 장비에 도입이 되기 위해서는 에너지가 픽셀당 100 pJ 이하가 되어야 한다. 즉 DSC encoder에서 에너지 효율은 매우 중요한 요소이다. Session 3.3에서는 이러한 DSC encoder의 효율성을 향상시키기 위해서 component-wise memory 구조와 같이 여러 기술들을 도입한 새로운 DSC encoder를 제안하였다. 해당 encoder에는 면적과 에너지를 줄이기 위해 computation resource를 공유하는 time-interleaved encoding 기술이 도입되었다. 또한 prediction pipe line을 통해 해당 encoder의 처리속도를 향상시켰다. 이러한 기술들을 통해 해당 논문에서 제안하고 있는 encoder는 0.8 V의 supply 전압에서 픽셀 당 84 pJ라는 결과를 나타내었다. 즉 해당 encoder는 픽셀당 100pJ 이하의 에너지를 나타내기 때문에 휴대 장비에 도입이 가능하다. 뿐만 아니라 해당 논문에서 제안한 DSC encoder는 기존에 있던 DSC encoder와 비교하였을 때 면적 당 처리율과 에너지 효율성이 더 우수한 결과가 나왔음을 확인할 수 있다.
|
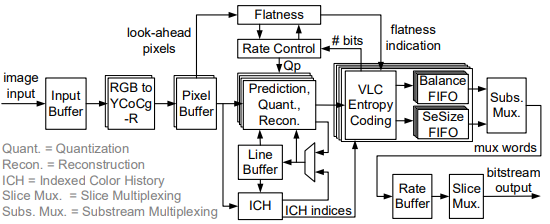 |
| [그림 2] Proposed DSC architecture for improved throughput, energy efficiency |
|
AI의 에너지 효율성 향상을 위한 연구뿐만 아니라 vision processor의 정확성 향상을 위한 연구도 진행되고 있다. Vision processing에서는 빛에 의해 발생하는 photocurrent의 전압 변환은 반드시 낮은 feature 추출을 띄는 첫번째 층 convolution만 진행하기 때문에 processing 성능에 한계가 있으며, 이러한 한계는 vision processor의 정확성에 영향을 미치게 된다. 이러한 문제를 해결하기 위해 session 3.4에서는 sensing과 computing이 융합된 vision system을 발표하였다. Sening과 computing의 융합을 성공시키면서 direct photocurrent computation (DPC) vision 센서의 processing 효율이 기존 센서보다 1.89배 더 높게 나왔으며 정확성도 98%라는 높은 성능을 나타냈다.
|
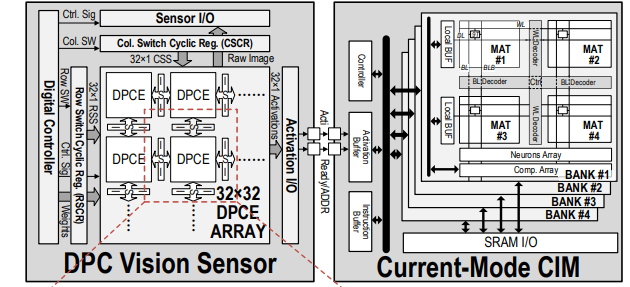 |
| [그림 3] Overall architecture of senputing system and direct photocurrent computation element |
|
마지막으로 물체 검출(detection)과 추적(tracking)에 대한 연구들도 진행되고 있음을 알 수 있다. 현재까지의 neural network processor는 패턴 인식(recognition)을 위한 구조로 디자인되고 있어 detection과 tracking 면에서는 효율성이 많이 떨어지는 문제가 발생하였다. 또한 object tracking processor들이 제안되어 왔지만 detection까지는 수행하지 못하였다. 이러한 문제를 해결하기 위해 session 3.2 논문에서 AI를 기반으로 object detection과 tracking을 수행하는 processor인 RAODAT를 발표하였다. 해당 RAODAT processor에는 물체의 detection과 tracking 부분에서 neural network learning을 가속시키기 위해 reconfigurable neural network inference/learning engine (RNILE)이 통합되었다. 또한 detection과 tracking 알고리즘을 프로그래밍할 수 있도록 object detection & tracking engine (ODTE)가 통합되었다. 이러한 구조를 가진 RAODAT processor에서는 detection과 tracking을 수행할 수 있을 뿐만 아니라 recognition 정확성도 매우 높다는 이점이 있다. 해당 processor는 online learning과 함께 tracking을 진행하여 물체의 dynamic variation을 배워 물체의 recognition의 정확성도 98.1%라는 결과를 나타냈다.
|
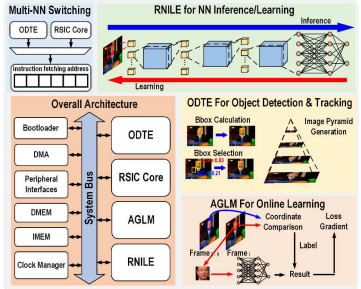 |
| [그림 4] Overall architecture of the proposed RAODAT processor |
| #Wireline Communications |
|
ㆍSession 9 / Clock Recovery & Generation
ㆍSession 21 / Wireline Transceiver Techniques
|
|
본 리뷰는 2021년도 ASSCC의 Wireline Communication을 다루고 있는 Session 9(Clock Recovery & Generation), Session 21(Wireline Transceiver Techniques)에 대한 것이다.
총 8개의 논문이 이번 session 9, session 21에서 소개가 되었다. 한국의 서울대학교[S9-1, S21-3, S21-4]에서 세 편의 논문을 발표하였고, 나머지 다섯 편의 논문은 대만[S9-2, S9-4, S21-1, S21-2]과 Texas Instruments-Kilby Labs[S9-3]에서 발표되었다.
발표된 8개의 논문 중 7개의 논문은 모두 CMOS 공정에서 칩으로 제작되었고 1개의 논문만 BICMOS 공정에서 칩으로 제작되었다. 이중 40-nm CMOS 공정에서 다섯 편의 논문[S9-1, S9-4, S21-1, S21-3, S21-4], 28-nm CMOS와 90-nm CMOS에서 각각 한 편의 논문 [S21-2]/[S9-2]이 제작되었다.
이번 학회에서 Wireline Communication을 다루는 session들에 소개된 논문들은 최근 다른 학회와 저널 등에서 많이 발표된 100~200 Gb/s data rate 이상을 지원하는 Transceiver(Transmitter + Receiver) architecture는 소개되고 있지 않다. 또한, 최근 발표된 많은 Receiver(RX) 구조들은 ADC-DSP(Digital Signal Processor)를 기반으로 하고 있는데 이러한 RX 역시 소개되지 않았다. 발표된 논문들의 큰 흐름을 보면 다음과 같다. 먼저, 최근 Data center interconnect에서 요구하는 data rate은 400 Gb/s 수준으로 증가하였고 이에 따라 Optical link의 수요 역시 증가하였다. Optical link에서 Vertical-cavity surface-emitting laser(VCSEL)은 다른 optical device들에 비해 비용적인 측면, packaging 효율성 등에서 장점을 가져서 많이 선택되고 있다. 하지만, VCSEL driver는 높은 operating voltage, 낮은 bandwidth, non-linear한 특성 등을 단점으로 가진다. Session 21에서는 이러한 단점들을 개선한 VCSEL Transmitter(TX) 구조가 발표되었다. 또한, 앞서 말한 ADC-DSP based RX의 경우 높은 speed와 resolution을 가지는 ADC를 사용해야 하고, ADC 후단에 들어가는 DSP가 너무 bulky 하여 area와 power 측면에서 단점이 있다. 이 때문에 Mueller-Muller PD(MMPD)를 이용한 Baud-rate Clock and Data Recovery(CDR)이 clocking power 소모를 줄이기 위하여 많이 사용되고 있다. 하지만, MMPD는 noise에 취약하고 lock point가 흔들릴 수 있다는 단점이 있다. ADC-DSP based RX, MMCDR이 가지는 이러한 단점들을 극복하고 Vertical Eye Opening/Margin(VEM, VEO)를 극대화 하기 위한 CDR based RX들이 session 9와 session 21에서 소개되고 있다.
소개된 8편의 논문을 주제별로 살펴본다면, [S21-1]과 [S21-4]에서는 PAM-4 VCSEL Transmitter with Feed-Forward Equalizer(FFE), [S21-2]에서는 Receiver with Reference-Less CDR, [S9-1, S21-4]에서는 Receiver with Baud-Rate CDR을 각각 주제로 다루고 있다. 또한, [S9-2]는 Multiplexed-DLL-Based CDR, [S9-3]은 Bulk Acoustic Wave(BAW) Oscillator, [S9-4]는 Dual-Loop PLL를 소개하고 있다.
8개 논문에 소개된 주요 idea, techniques 중 일부에 대하여 간단하게 살펴보겠다.
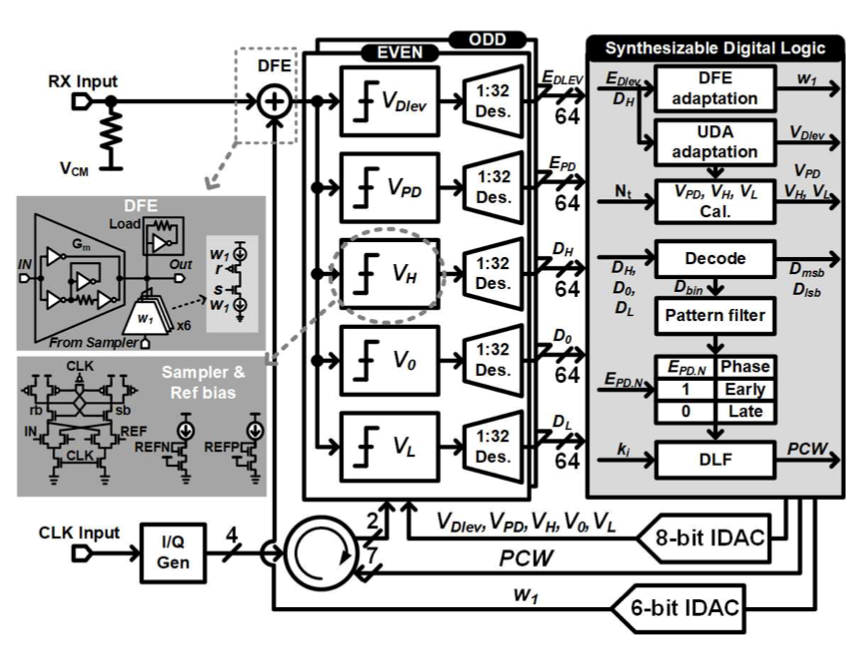
Session 9-1은 48 Gb/s의 data rate을 가지는 Baud-rate digital CDR based PAM-4 Receiver이다. 본 논문에서 제시한 baud-rate phase detector는 Stochastic Phase Detector(SPD)이다. 해당 동작은 다음과 같다. 먼저 sampling phase condition이 ‘Early’ 인지 ‘Late’ 인지 판단하여 연속적인 PAM-4 패턴의 histogram을 수집한다. 그 후, Bayesian 정리를 이용하여 SPD의 weight를 계산한고 그 값을 quantize 한다. 마지막으로 계산된 SPD weight 값을 random한 sequence와 곱하고 누적하여 SPD gain curve를 얻는다. 논문에서 제시한 SPD는 기존 사용되던 SS-MMPD(Sign Sign MMPD)에 비해 극대화된 VEO와 더 최적화된 phase-locking behavior를 보여준다.
|
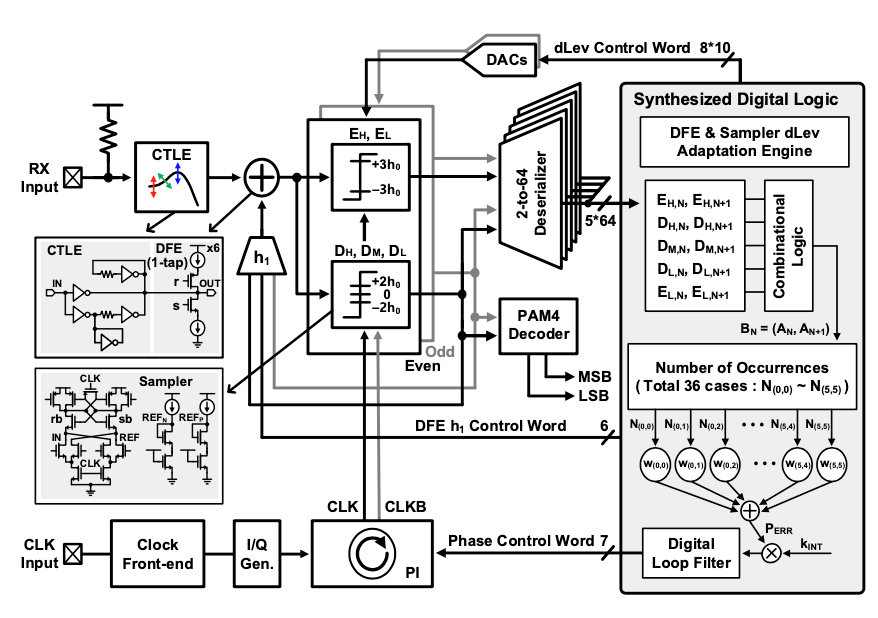 |
| [그림1] S9-1에서 제시한 PAM-4 Baud-Rate Receiver Architecture |
|
Session 21-3의 구조 역시 48 Gb/s의 Baud-rate PD based PAM-4 Receiver이다. 본 논문에서 제시한 multi-level signaling용 baud-rate phase detector는 기존 MMPD의 문제점인 first-tap pre-cursor ISI(Inter Symbol Interference)가 0이 되는 지점으로 locking point가 움직이는 문제를 개선하여 adaptive DFE(Decision Feedback Equalizer)이 unique한 lock point를 가지게 한다. 또한, 이 lock point는 post-cursor ISI와 무관하다.
|
 |
| [그림2] S21-3에서 제시한 PAM-4 Baud-Rate Receiver Architecture |
| #FPGA |
|
ㆍSession 7 / FPGA Design for AI/ML Applications
|
|
이번 A-SSCC에서 FPGA 분야와 관련해서 Session 7과 Session 19에서 총 10개의 논문으로 소개됐다. COVID-19의 영향으로 인해 모바일 초연결성 트렌드를 가속시켰다. 이로 인해 사람 간의 연결을 더 똑똑하게 개선시킬 수 있는 에너지 효율적이고 안전한 IC들의 역할이 더 중요해졌다. 그래서 이번 A-SSCC 2021에서는 IoT간의 연결을 더 강화시키는 IC 솔루션에 대해 탐구한다. 세션 7에서는 여러 목적에 맞는 에너지 효율적인 FPGA 시스템들에 대해서 소개한다.
#7.1는 칭화대에서 발표한 논문인데 object detection task에서 Non-Maximum Suppression (NMS) 알고리즘에서 오는 높은 복잡도에서 발생하는 여러 반복적인 process, sorting, IOU 연산으로 인해 복잡한 회로와 높은 에너지 소모가 발생하는데 이를 해결한 시스템에 대한 논문이다. FPGA에 구현한 전체 구조는 그림1과 같이 NMS 프로세서, DDR3 SDRAM, instruction BRAM, controller, 연산 코어 어레이로 구성된다. 후보 박스들에 대한 연산을 multiple thread 방식으로 grouping해 max-search 알고리즘을 통해 병렬 처리하였다. 각 NMS 코어는 multiple thread 연산 어레이, inter-thread Binary Max Engine (BME), Synchronization Controller (SC)로 구성되어 각 thread별로 intra-thread BME가 부착되어 이를 통해 pre-sort 해주어야 하는 단계를 없앴다. 또한, Intersection Over Union (IOU) 연산 자체를 대수적으로 간단히 하여 연산 overhead 자체를 낮췄다. Zynq XC7Z035 FPGA에 100MHz로 구동되는 시스템을 구현해 Yolo-v3 네트워크에 VOC2007 데이터셋을 넣어 2682 박스 중에 15개를 3.42us만에 cluster 작업한 것을 확인했다. 이전 연구에 비해 198.8배 빨라졌고 면적도 덜 소모하게 됐다.
|
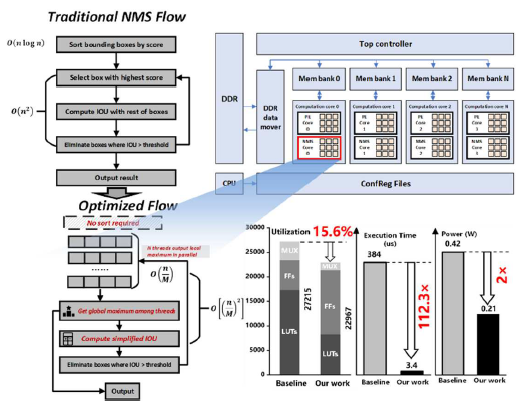 |
| [그림 1] 전체 NMS 프로세서 아키텍처와 주요 차별점들 |
|
#7.2은 카이스트에서 발표한 논문으로 deep reinforcement learning (DRL) 구현을 위해서는 큰 DNN 연산 및 긴 adaptation 시간이 필요하다. 그래서 이를 줄이기 위해 DNN 미세 튜닝이 이뤄지는데 큰 workload를 필요로 하고 연산 감수비가 정해져 있는 문제점이 있다. 그래서 Heterogeneous Replay Buffer (HRB)를 통해 이전 환경의 경험들을 활용해 workload를 줄였다. Baseline과 new buffer를 둬서 더 빠른 DRL finetuning의 빠른 수렴을 도와준다. HRB를 통해서 선택된 layer들만 re-training이 이뤄질 수 있는데 이 때, Multi-Precision SELective RETraining (MP-SELRET)을 통해 학습 layer가 아니면 FXP16으로 연산을 진행해 연산양을 줄였다. 전체 구시스템 조는 host CPU, weight 및 HBR을 저장하는 DDR3 SDRAM, 제안하는 FPGA 가속기로 이루어져 있고 FPGA는 크게 FP코어와 FXP 코어로 따로 구성되어 mixed-precision 연산에 대해 최적화시켰다. Intel Cyclone V에 구현해 200MHz로 구동, MuJoCo Humanoid를 학습할 때, 25.6GOPS의 최대 성능, 2.9W 파워 소모 하는 것을 확인하였다.
|
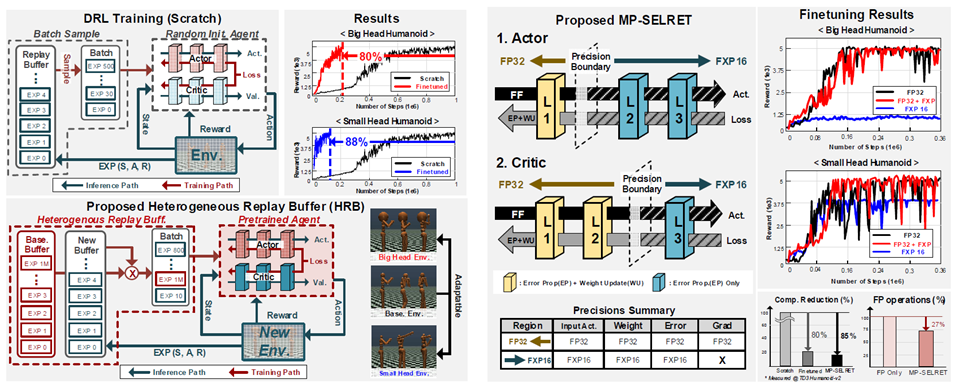 |
[그림 2] (좌)Heterogeneous Replay Buffer 구조
(우)Multi-Precision SELective RETraining (MP-SELRET) |
|
#7.3는 Macau 대학교에서 발표한 논문으로 CNN 가속을 위해 여러 기법들이 제안됐었는데, 이미 compressed된 모델에서는 관련 기법이 적용이 안 되고 CNN 연산에서 발생되는 많은 메모리 접근 에너지를 고려하지 못한다. MobileNetV2은 크게 그림3과 같이 inverse residual block과 bottleneck with expansion 부분으로 구성되는데 Double Layer MAC (DLM)을 통해 PW1과 DW 레이어를 pipeline 시켜 연산하게 구성했다. 그리고 각 pipeline 효율을 높이기 위해 digital signal processor를 동적으로 할당해 다양한 레이어에 최적화시켰다. 그리고 더 낮은 precision으로 같은 weight를 사용하는 2개의 곱셈을 하나의 DSP 동작으로 진행되는 방식도 제안했다. Accumulate하는 adder tree 같은 경우도 다양한 layer들을 지원할 수 있게 reconfigurable한 방식으로 설계했다. 이를 Xilinx VC709에 구현해 338 DSP만 사용해 246.7GOPS, 504 GOPS/W의 성능과 4.89W 파워를 소모하는 것을 확인했다. 전체적으로 MobileNetV2에 대해 TOP-1 정확도 4%만 감소하면서 operation 수는 20% 줄일 수 있었다.
|
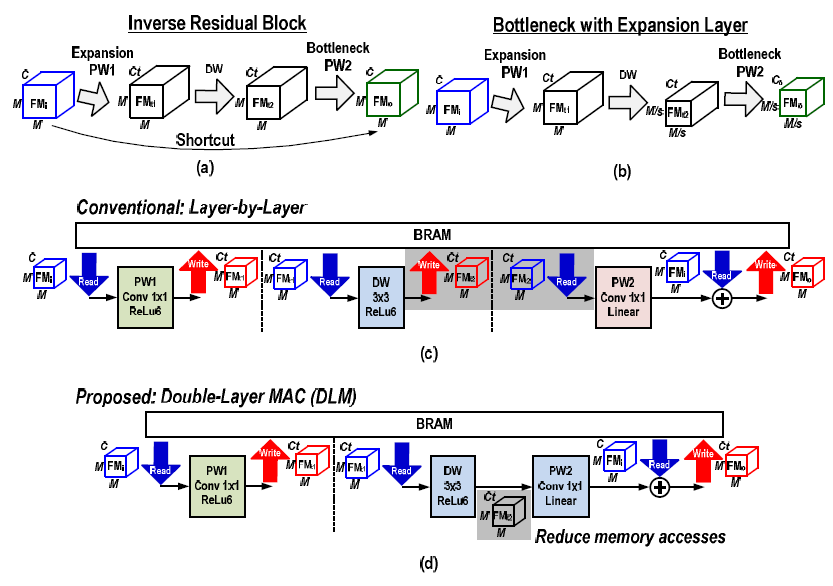 |
| [그림 3] MobileNetV2 구조와 제안하는 Double-Layer MAC 구조 |
|
#7.4는 Huazhong 과학기술 대학교에서 발표한 논문으로 자율로봇에는 여러 DNN 및 navigation 알고리즘을 필요로 하는데 이는 큰 연산양을 요구한다. 최근 연구는 특정 알고리즘에만 최적화되어 Intelligent and Autonomous Mobile Robots (I-AMR)의 요구사항에 따른 HW utilization을 보여주지 못한다. 제안하는 전체 로봇 SoC는 그림4와 같이 Application Processing Unit (APU), Reconfigurable Matrix Multiplication (RMM) coprocessor들로 구성되어 각 RMM이 navigation, intelligent 코어의 역할을 수행하게 되어 있다. 각 RMM에는 local memory buffer (LMB)로 구성된 조직이 있어 병렬 processing과 데이터 재사용이 가능하고 address generation decode (AGD)가 있어 데이터 sparsity나 symmetry에 대해 최적화할 수 있다. RMM에서 reconfigurable systolic array 구조로 되어 있어 다양한 레이어에 따라 위 동작들을 활용해 matrix segmentation과 mapping scheme을 적용할 수 있다. Extended Kalman Filter (EKF) 알고리즘의 7개의 matrix multiplication에 대해 93.47% HW utilization을 보여주는 것을 확인했고 청 924.5MOPS, 1.98 GOPS/W 성능으로 이전 연구 대비 1.09x, 4.83x 향상했다.
|
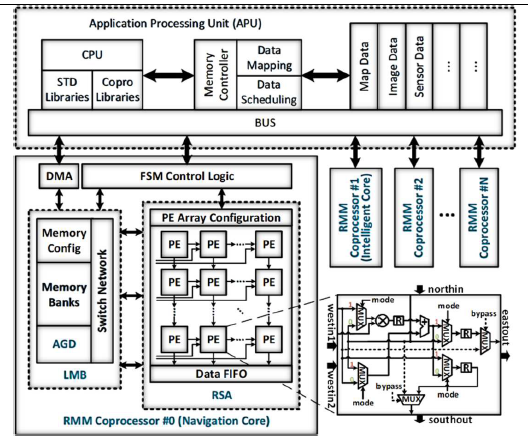 |
| [그림 4] Intelligent robot SoC의 구조와 내부 RMM coprocessor 구조 |
|
#7.5는 Beihang 대학교에서 발표한 논문으로 AI 알고리즘을 embedded FPGA에 구현할 때 기존 방식을 사용하면 local-optimal한 성능이 나오지 않게 된다. 그래서 Hardware-aware Neural Architecture Search (HW-NAS)가 필요로 한데 이는 복잡한 search space로 필요로 하고 여기서 나온 결과가 edge AI 디바이스에서 사용 불가한 문제점이 있다. 그림 5와 같은 프레임워크를 제안하고 강화학습을 사용한다. RNN controller NN 아키텍처들을 탐색하고 HW 스케줄러로 탐색된 아키텍처의 configuration을 탐색한다. 여기서 NN을 통해 성능 수치를 뽑아 joint 성능을 보상 함수로 주게 된다. 여기서 residual block들은 학습 과정에서만 사용되고 inference 과정에서는 합쳐지면서 short-cut-free 아키텍처가 나오게 된다. 그 외에도 adaptive low-bit quantization 기법과 pipelined reconfigurable streaming 구조로 구성해 효율적으로 동작한다. 이를 Xilinx Zynq Ultra96v2 FPGA에 구현해 CIFAT-10과 ACM DAC2020-SDC 데이터셋을 이용해 테스트해 65.49% Intersection over Union (IoU), 72.7FPS, 60.1frame/J의 성능을 확인하였다.
|
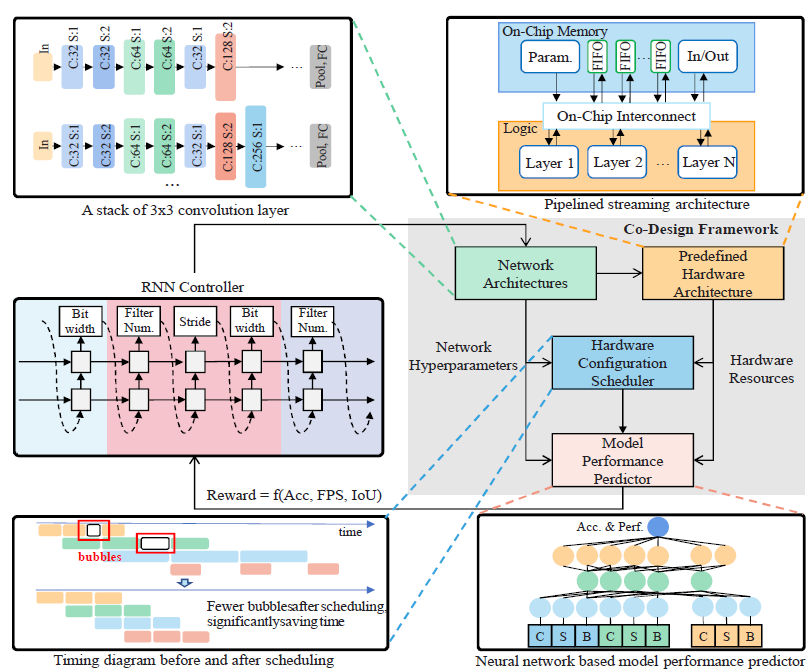 |
| [그림 5] 전체적인 Software-Hardware co-design 프레임워크 |
|



