| #Power Management |
|
ᆞSession 17 / DC-DC Converters
|
|
이번 ISSCC 2021에는 총 20편의 Power conversion 관련 논문이 발표되었다. #17 DC-DC Converters (9편)에서는 하이브리드 구조에 관한 논문 4편과 fully integrated inductor를 사용하는 논문 2편, 에너지하베스팅 1편, SIMO 1편, Charge-pump+LDO 1편이 발표되었다. 하이브리드 구조에 대한 논문의 비율이 높았다. #29 Digital Circuits for Computing, Clocking and Power Management(2편) 디지털 LDO와 SIMO가 발표되었다. 또한, #33 High-Voltage, GaN and Wireless Power (9편)에서는 GaN을 사용한 converter 논문이 4편, 무선전력 전송 논문이 3편, Switching Supply Modulator논문 1편, High-voltage converter 논문 1편이 발표되었다. 본 후기에서는 총 3편의 논문을 살펴보고자 한다.
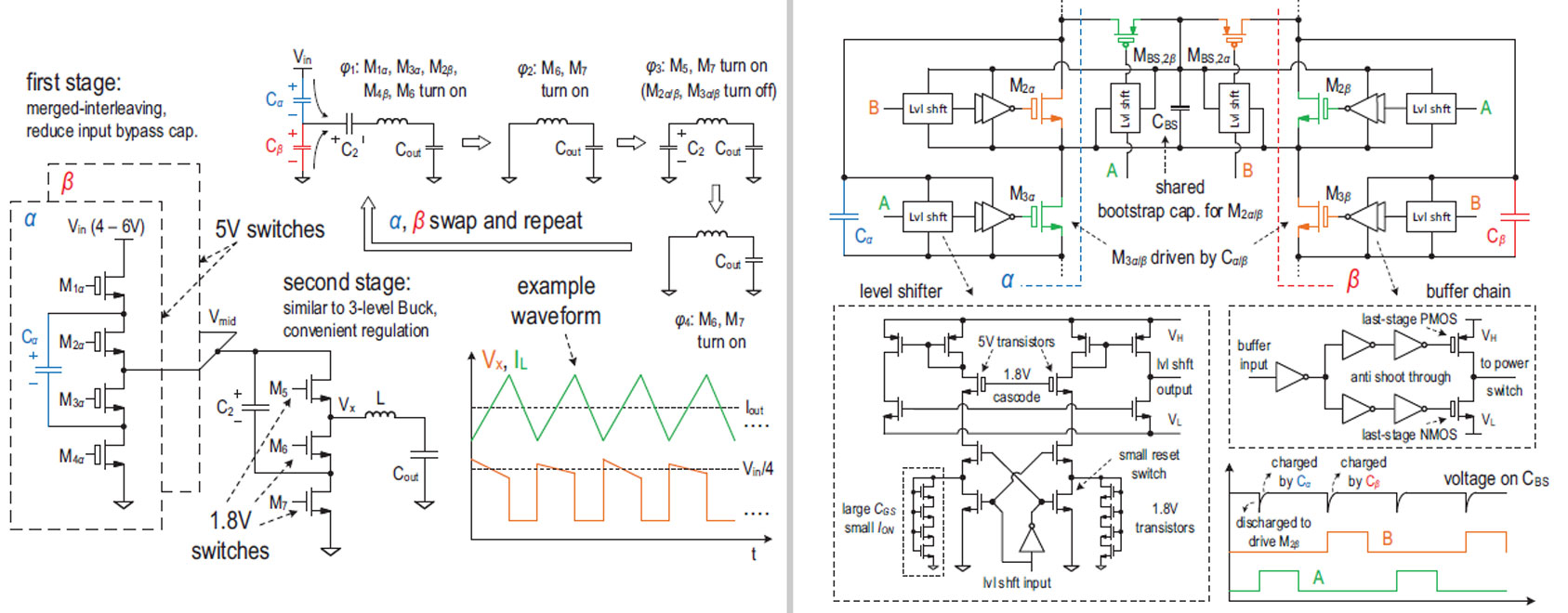
#17.1은 4V ~ 6V의 입력 전압을 0.4V ~ 1.2V의 낮은 출력 전압으로 변환하기 위해서 필요한 High conversion-ratio를 가지는 하이브리드 구조를 제안했다. 이 논문에서는 스타트업 같이 입력 전원이 변할 때 큰 전압 스트레스가 스위치들에 가해지는 문제점을 해결하기 위해 2-stage cascaded 구조를 사용하였다. (그림(17.1.1))
본 논문의 구조의 첫 번째 stage는 두 개의 2:1 switched-capacitor로 구성되어 있으며, 두 번째 stage는 변형된 3-level converter로 구성되어 있다. 이 컨버터는 Cα 와 Cβ의 연결을 절반의 주기(4 phases)마다 바꿔주면서 동작하며, 이에 따라 전체 주기는 8 phases로 이루어진다. 이 논문에서는 스타트업 시 flying capacitor의 전압을 빠르게 증가시키기 위해, φ1 또는 φ5에서 C2의 전압이 원하는 전압(=Vin/4)보다 낮을 경우 φ3 또는 φ7의 동작을 스킵해서 C2가 방전되지 않도록 하였다. 제안하는 구조와 컨트롤 방법을 이용하여, 스타트업 시간을 다른 논문 대비 100배 정도 감소하였다.
|
 |
| [그림 1] |
| 17.1.1 Schematic, Phase-wise equivalent circuits and example waveform of proposed converter. |
17.1.2 Illustration of the gate-drive strategy with circuit details of the level shifter and buffer chain |
|
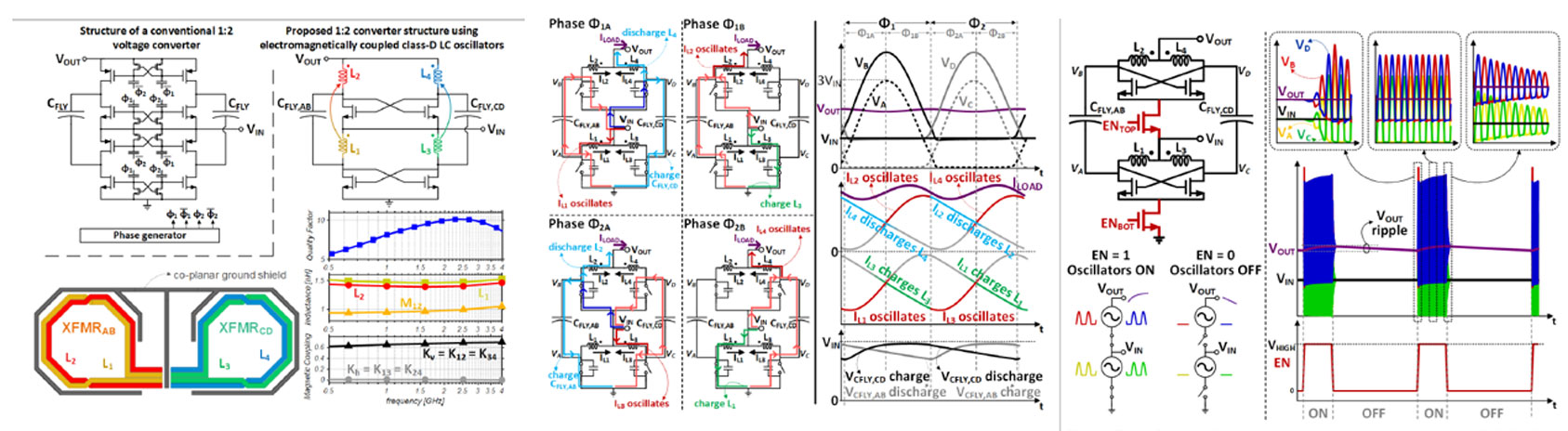
#17.3 논문은 아래 그림 17.3.1에 나와있는 것처럼, 1:2 charge pump의 4개의 스위치를 4개의 인덕터로 치환한 구조로 fully integrated power management 회로를 제안했다. 이 회로는 구조 자체가 오실레이터처럼 동작하기 때문에 frequency reference, non-overlapping phase generation, clock buffers, level shifters 와 같은 회로가 필요 없어서 효율이 좋아지고, 필요한 면적이 줄어든다는 장점을 가진다. 또한, 그림 17.3.2를 보면 알 수 있듯이 출력으로 전력이 연속적으로 공급되므로 출력 리플이 감소된다는 또 다른 장점을 가진다. 이 구조는 구조적으로 왼쪽과 오른쪽이 서로 대칭적으로 동작하므로, 위아래 사이의 인덕터에서는 커플링이 크게 일어날수록 효율적이고 좌우 사이의 인덕터에서는 커플링이 적게 일어날수록 효율적이다. 이 회로는 1.25GHz에서 동작하며, 최대 효율은 67%를 얻었다.
|
 |
| [그림 2] |
17.3.1: Schematic of the conventional 1:2 voltage converter(top left) and the proposed coupled class-D oscillator-based converter(top right). Layout and EM simulation results of the on-chip transformer(bottom)
|
17.3.2: Operating principle of the proposed converter divided into four sub-phases(left) and the simulation results(right) |
17.3.3:Duty-cycling scheme to extend the operation range to light loads. |
|
#17.9은 High-conversion-ratio를 달성하는 동시에 큰 부하 전류를 공급하기 위한 하이브리드 boost converter를 제안했다. 이 회로는 인덕터 전류를 빌드업 할 때 캐패시터를 충전하고, 아웃풋으로 파워를 전달 할 때, 인덕터와 캐패시터가 직렬로 연결되기 때문에 기존의 boost converter보다 더 큰 conversion gain을 가진다. 그렇기 때문에 더 짧은 duty로도 기존 boost converter와 같은 conversion gain을 얻을 수 있다. 이로 인해 인덕터 전류의 실효값이 감소되어 효율이 증가된다. 이 논문은 높은 출력 전압 (30V)을 생성하는 동시에 최대 1.2 A까지 부하 전류를 공급할 수 있으며, 97.4%의 peak 효율을 달성하였다.
|
|
[그림 3] |
17.9.1: CF charged in φ2 in prior arts limits the driving capability in high CR (top); 3S boost converter charges the CF in φ1 fitting the demand of high CR, high driving capability (bottom) and low voltage stress on switches.
|
17.9.2: Proposed 3S boost converter has widest CR either under no load or heavy load. The CF, with sufficient energy can bring low inductor ripple, fast transient response, and low inductor de current. |
| #Analog |
|
ᆞSession 5 / Analog Interfaces
ᆞSession 31 / Analog Techniques
|
|
이번 ISSCC 2021의 Analog Subcommittee에서 총 14편의 논문을 “Analog Interfaces”와 “Analog Techniques” 두 세션으로 구성하였다. Analog Interfaces (T5) 세션은 capacitance-to-digital converter (CDC) 2편, 온도센서 2편, magnetic 전류센서 2편, MEMS 기반 mass flow 센서 1편, 그리고 출력버퍼용 아날로그 증폭기 1편 (총 8편)이 발표되었다. Analog Techniques (T31) 세션에서는 증폭기 2편과 주파수 레퍼런스 2편 (총 4편)을 선보였다. 종래 연구 트렌드와 동일하게 대다수의 논문들이 낮은 리소스(저전력, 저면적, 저가격 등)로 성능(속도, 해상도, 정밀도 등)을 극대화하기 위한 새로운 회로설계 기법들을 발표하였다.
(#5.1 – Peking Univ.) 논문은 1.5μW 전력소모로 0.0094%의 상대습도(RH) 분해능을 갖는 고성능 CMOS 습도센서를 발표하였다. 본 논문의 습도센서는 넓은 동적영역 확보를 위해 zoom-SAR와 3차 DSM 구성의 capacitance-to-digital converter (CDC)로 구현하였다. 기본적으로 저전력을 위해 floating inverter amplifier (FIA) array를 사용하였는데, 입력 커패시턴스 범위에 따라 FIA 채널 수를 조절하는 power-aware 가변 기법을 제시하여 소모전력을 최적화 했다. 또한 DSM의 동작범위를 적응적으로 시프팅하는 ARS 방법을 제안하여 비교기와 OTA 블록에서의 저전력화를 달성하였다. 본 논문은 습도센서 부문에서 세계최고 수준의 FoM (= 0.135pJ·RH²)를 달성한 것에 의미가 있다.
(#5.2 – NUS) 논문은 하베스팅 에너지로 구동되는 초저전압 capacitance-to-digital converter (CDC)를 발표하였다. 두개의 oscillator에 레퍼런스 커패시터와 입력 커패시터를 서로 swapping하는 구조를 통해 전원 전압 regulation 및 레퍼런스 전류 없이도 동작할 수 있는 CDC를 제안하였으며, 0.3V 전원과 1.37nW 전력소모로 7-bit ENOB을 달성하였다.
(#5.3 – Delft Univ. of Tech. & 연세대) 논문은 SoC 내에서 국부적 hot-spot 모니터링을 위한 초저면적 저항기반 온도센서를 발표하였다. 종래 PD-DSM (phase-domain delta-sigma modulator) 구조의 온도센서는 저면적화가 가능했지만 전류-주파수 변환기 (CCO)의 비선형성과 카운터 회로의 시간영역 양자화-잡음 때문에 높은 정밀도와 높은 해상도를 기대하기 어려웠다. 본 논문은 dual gated-ring-oscillator (dual GROs)를 활용하여 양자화-잡음을 shaping하면서도 위상검출의 선형성을 높여 종래 PD-DSM 기법대비 10배 개선된 해상도(12.8mK)와 저전력화(28μW)를 달성하였다.
(#5.5 – Texas Instruments & MIT) 논문은 integrated fluxgate (IFG)를 이용한 비접촉식 전류센서를 발표하였다. 전기차(eV) 등 산업용 고전압 응용분야에서는 비접촉식 전류센싱이 반드시 필요한데 종래 hall 센서대비 IFG 방식은 해상도를 높이고 부피나 가격 측면에서 이점이 있지만 선형성 확보를 위해서는 큰 보상전류가 필요하다. 특히, IFG 방식은 초기 긴 응답시간이 필요하여 duty-cycling을 이용한 전력소모 저감이나 고속응답을 요구하는 고장(fault)감지 응용에는 적합하지 않다는 문제점이 있었다. 본 논문은 mixed-signal 기반 front-end 설계로 이전 수렴지점 (LCP)를 다음 duty cycle때 이어가는 방식을 구현하여 신호 수렴에 필요한 시간을 대폭 감소시키고 계층화된 검색 모드로 더욱 빠른 응답시간을 확보하였다. 그 결과 경쟁력 있는 응답시간 (125 kHz BW)을 확보하면서도 적극적인 duty-cycling으로 소모전력을 100배 가까이 줄일 수 있었다.
(#5.8 – KAIST) 논문은 구동속도를 획기적으로 증가시키기 위한 출력버퍼용 증폭기 회로구조를 제안하였다. 입력에 따라 비선형적인 전류를 증폭 및 생성하여 출력에 공급하는 dynamic Class-C 증폭기 (DCCA)와 넓은 입·출력 전압을 커버할 수 있는 선형증폭기 (OTA)가 병렬 연결된 구조로, 응답초기에는 DCCA가 매우 높은 슬루율을 제공하고 linear settling 구간에서는 전력대비 GBW 부스트된 선형 OTA가 고속 안정화를 담당한다. DCCA는 선형안정화 구간까지 슬루를 지속할 수 있는 near-zero dead-zone을 구현하였으며, 선형 OTA는 rail-to-rail 입력에서도 높은 GBW가 유지될 수 있도록 전류-재분배 회로기술을 제안하였다. 제안된 증폭기는 정적소모전류 대비 최대 2,600배의 전류를 구동할 수 있으며 세계최고수준의 슬루율 FoM과 경쟁력있는 GBW FoM을 넓은 전압범위(5V)에서 달성하였다.
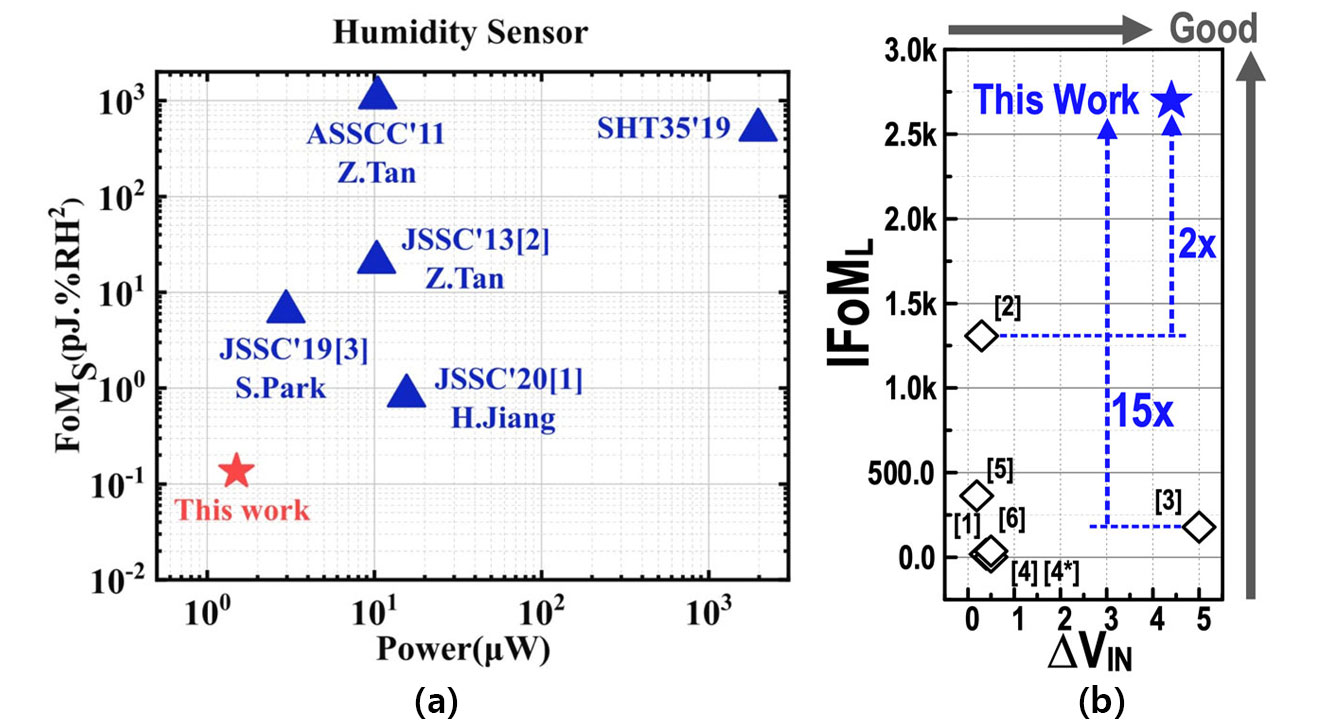 |
| [그림1] FoM 비교 그래프
|
| (a) #5.1논문 습도센서의 전력소모 x 검출시간 x RH해상도, |
(b) #5.8 논문 증폭기의 슬루율 x 부하커패시터 / 전류소모 |
(#31.1 – Analog Devices) 논문은 최근 유행하고 있는 true wireless stereo (TWS) 무선헤드폰용 digital-input Class-D 오디오 증폭기를 발표하였다. 저전압 (1.8V)에서 Class-D의 높은 선형성 확보를 위해 디지털 기반의 feedforward 기법을 포함한 5차 DSM을 구현하였으며, 저출력 오디오에서 정적 소비전류를 줄이기 위해 가변 DSM 주파수를 사용하였다. 특히 공통모드 안전화를 위한 local-feedback의 power stage 구성은 filter-less 구조에서 에너지 효율적인 전류 DAC으로 직접 구동이 가능하도록 하였다. DSM 주파수가 극도로 낮아지는 제로 출력에서는 오직 CMFB 증폭기가 출력의 공통모드 전압을 유지시킨다. 이러한 기법들을 통해 본 논문은 93% 전력효율로 Class-D의 -93dB THD+N 선형성을 달성하였다.
(#31.2 – 연세대) 논문은 세계최고수준의 에너지 효율과 칩 면적을 달성한 RC기반 주파수 레퍼런스 생성회로를 발표하였다. 종래 RC 기반 주파수 레퍼런스들은 높은 효율과 완전 집적화가 가능하였지만 on-chip 저항의 온도에 따른 가변특성(Temperature Coefficient, TC) 때문에 높은 정밀도를 갖기 어려웠다. 종래에는 polynomial TC특성을 보상하기 위한 dual-RC 구조를 제안되었는데 두개의 아날로그 phase-domain DSM이 필요하여 역으로 전력소모가 커지거나 면적이 증가하여 RC 주파수 레퍼런스 본연의 장점을 살리지 못하는 한계가 있었다. 본 논문은 아날로그 phase-domain DSM을 zero-crossing 기반 디지털 phase-domain DSM으로 대체하여 높은 에너지 효율 (5pJ/cycle)과 작은 면적 (0.06mm²), 그리고 높은 정밀도 (±200ppm) 모두를 달성하였다.
|
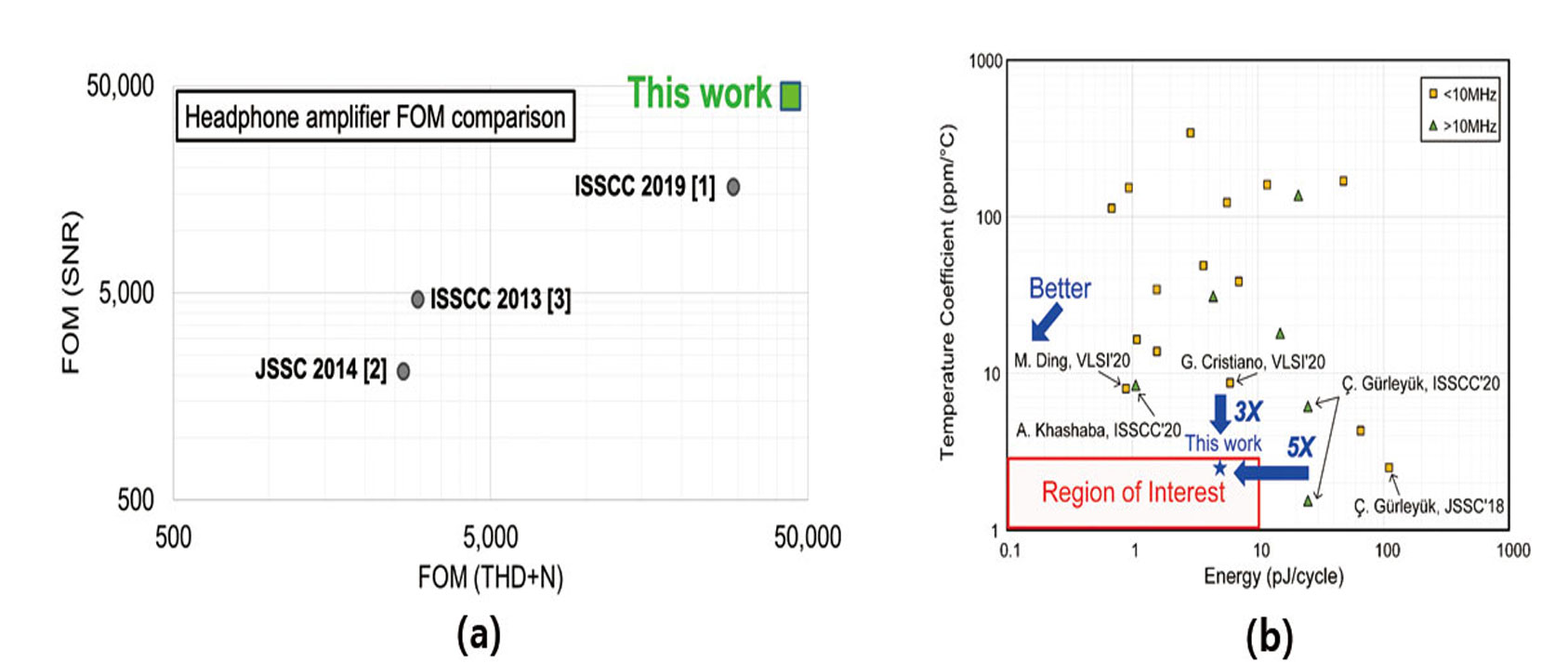 |
| [그림2] FoM 비교 그래프
|
| (a) #31.1논문 헤드폰용 오디오 증폭기의 출력전력 / 정적소비전력 / SNR |
(b) #31.2 논문 에너지 소모 및 TC 특성 |
| #Medical Applications |
|
ᆞSession 18 / biomedical devices, circuits, and systems
|
|
올해도 어김없이 ISSCC에서 다양한 회로 기술 및 응용들이 발표되었으며, 그 중 biomedical devices, circuits, and systems 세션 18에 4편의 페이퍼가 발표되었다. 작년과 비교하였을 때, 바이오메디컬 분야에서의 집적회로의 새로운 응용분야들이 더 집중되어 소개되었다고 생각되며, 앞으로도 집적회로 기술로 바이오메디컬 분야에 더 다양한 문제들을 해결할 수 있을 것이라 확신된다.
|
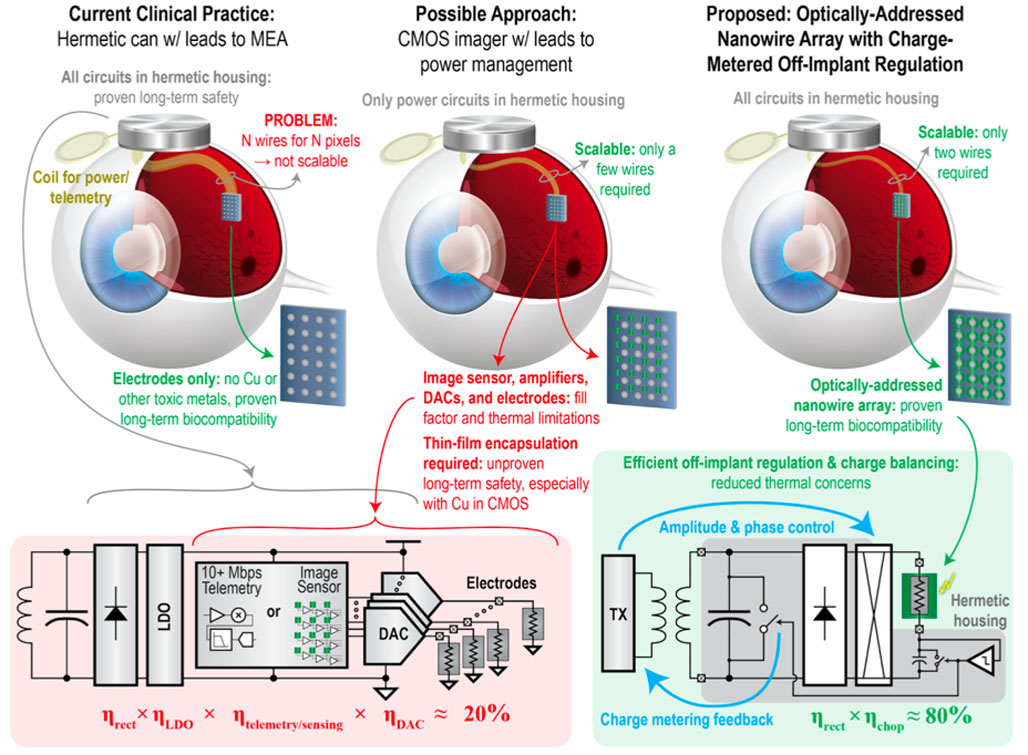 |
| [그림 1] 18.1 Nanowire array-based Retinal Prosthesis |
|
#18.1 연구는 Retina implant로 알려진 집적회로의 대표적인 바이오메디컬 응용에서 기존의 interconnection 혹은 발열, 생체 이식 안정성 문제 해결하기 위해 nanowire array를 이용하여 최대 1512채널을 구현한 기술을 소개한다. 그림 1의 왼쪽 기술은 카메라가 체외에 위치하여 영상을 캡쳐한 후 해당 영상을 무선으로 체내 전송한다. 이후 이를 전극으로 전송하는데, 데이터 수신칩과 전극 사이의 연결이 N 픽셀을 위해 N개의 선이 필요하며, 이로 인해 약 256개의 채널만 구현되며, 매우 제한적인 시력 회복만 가능하게 된다. 이를 해결하기 위해 최근 제안된 a full-CMOS solution(그림 1 가운데) 기술은 이미지 센서, 전기자극회로, 전극 어레이 등을 하나의 칩 위에 구현하며, 이를 통해 해당 칩과의 통신 및 전력 공급을 하기 위한 몇 개의 유선 연결만 필요하게 된다. 하지만 칩 위에 모든 요소들이 다 집적화되기에, 칩의 면적이 커져야만 하고, 전력소모로 인한 발열문제를 피할 수 없게된다. 특히나 칩에서 사용되는 메탈(Cu)이 생체 안정성에 위험을 주기에 칩에 완벽한 보호막 구현이 요구된다. 이 모든 것을 해결하고자 본 연구(그림 1 오른쪽)는 나노와이어를 이용하였다. 나노와이어는 입사되는 빛의 세기에 따라 저항이 변하며, 이로 인해 결국 자극하는 전류의 양이 결정된다. 해당 기술을 이용하기 위해 charge-metering feedback기법을 응용하였으며, 이것으로 자극되는 전하의 양을 외부에서 측정/조절할 수 있다.
|
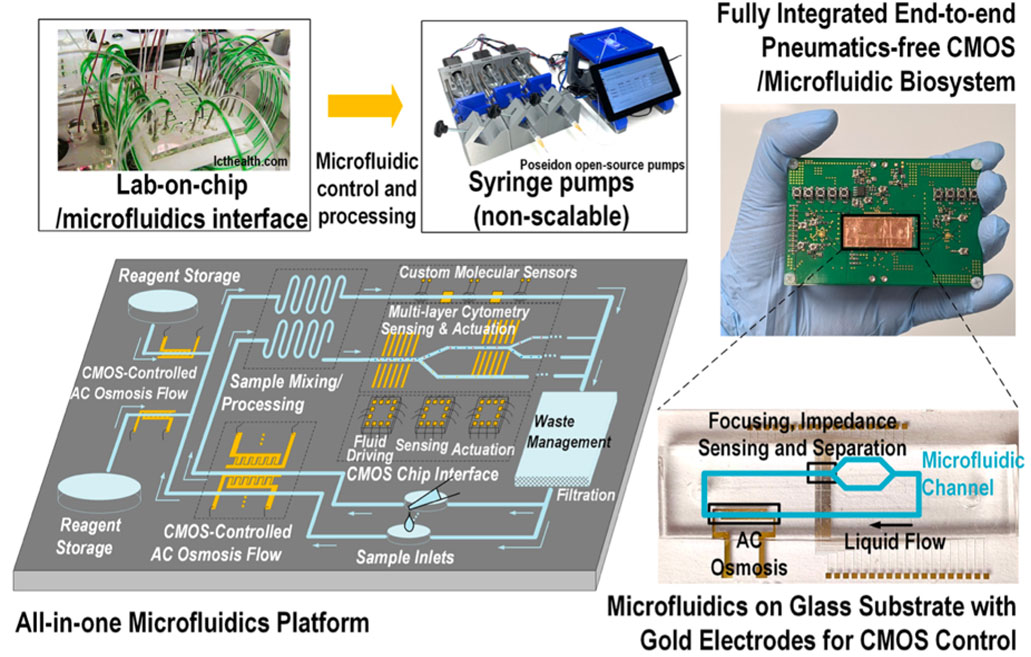 |
| [그림 2] 18.2 a CMOS-microfluidic system |
|
#18.2본 논문에서는 point-of-care (POC) 분자진단 플랫폼을 발표하였다. 기존의 초소형 고속 플랫폼과는 달리, sample fluid부터 진단 정보까지 아우르는 end-to-end 프로세스를 포함하였으며, 해당 시스템은 all-in-one microfluidics platform이라 명명하였다. 기존의 칩 스케일 플랫폼은 syringe pump등을 이용하거나 혹은 수작업으로 진행 되어야만 했던 많은 프로세스들(bio-sample handling, filtering, mixing with re-agents 등)을 자동으로 할 수 있기에 매우 혁신적인 연구로 판단된다. 핵심은 CMOS-based electrically driven electrokinetic flow 기능을 구현했기 때문이며, 이를 위해 전극에 인가되는 전압을 변경함으로 전기장 패턴을 적절히 조정한다. 해당 기술은 1) 많은 electrolyte 유체의 흐름을 AC electro-osmosis를 통해 조정하고, 2) 셀 manipulation과 분리 기능, 그리고 3) label-free bio-molecular와 cell sensing, 그리고 분리 기능을 선보인다. 기존의 회로설계기술과 유체역학등의 다양한 분야의 지식이 반드시 필요한 연구이며, 집적회로의 응용처가 계속 확대되는 좋은 예라고 볼 수 있다.
|
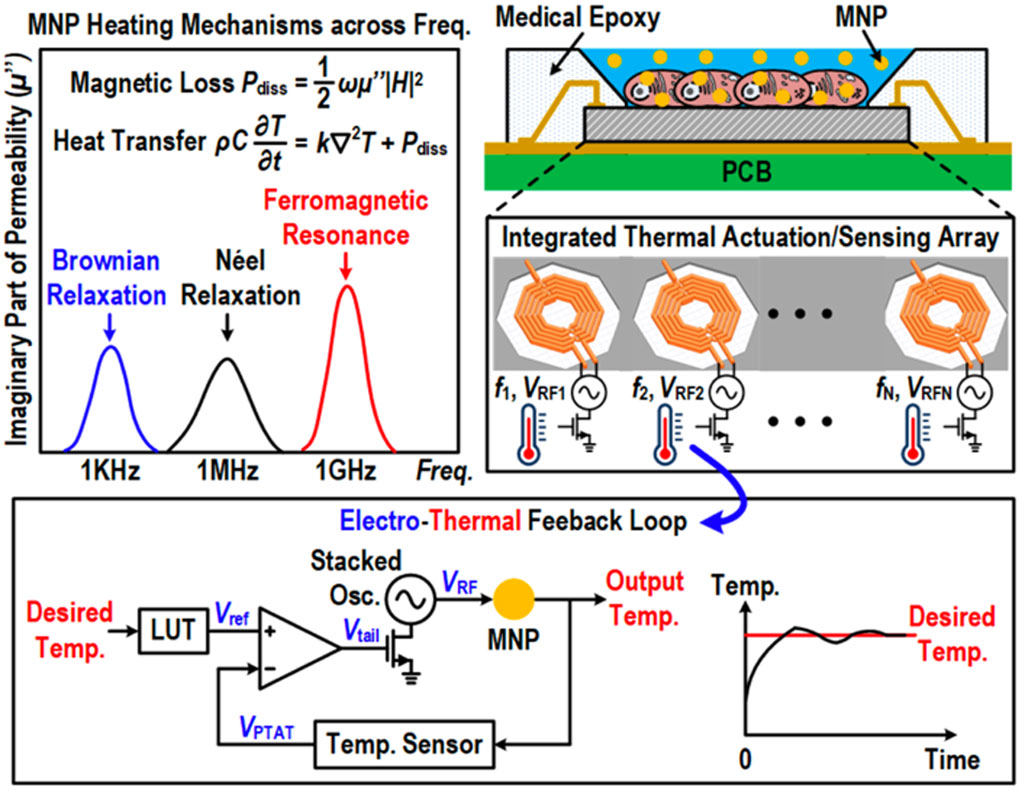 |
| [그림 3] 18.3 Integrated thermal actuator/sensor |
|
#18.3 Magnetic nanoparticles(MNP)은 AC magnetic field가 인가되면 국부 열을 발생시킨다. 이를 이용해 hyperthermia cancer therapy등의 국부 열이 필요한 응용처에 적용될 수 있다. 기존의 방법은 낮은 주파수를 이용해 MNP에 열을 발생했지만, 이 경우 많은 에너지 소모가 필요하거나, 공간해상도가 늦은 단점이 존재한다. 이를 동시에 해결하기 위해 본 논문은 GHz영역에 존재하는 Ferromagnetic resonance 부분에서 AC magnetic field를 생성하는 기술과 온도 레귤레이션을 위해 temperature sensor를 활용한 피드백을 제안 하였다. AC magnetic field를 생성하는 픽셀의 크기는 0.6mm x 0.7mm로 매우 작아 공간해상도를 향상시켰으며, 20Vpp가 넘는 높은 AC excitation 전압을 45nm CMOS SOI공정으로 구현하였다.
|
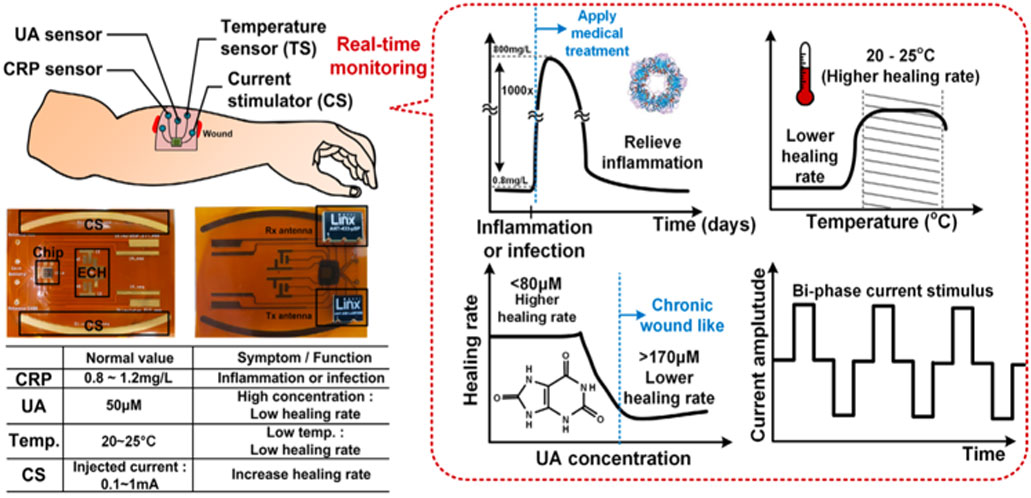 |
| [그림 4] 18.4 Chronic wounds healing process monitoring system |
|
#18.4 상처(Chronic wounds) 치료 과정을 모니터링하는 장치가 본 논문에서 발표되었다. 이를 위해 C-reative protein(CRP), uric acid (UA), temperature 모니터링, 전기자극 기능을 포함하고 있다. Three -electrode sensor는 CRP, UA의 존재 여부에 따라 다른 양의 전류가 흐르게 되고 해당 전류를 증폭한 뒤 time-based ADC를 통해 디지털 변환을 한다. 온도 센서는 저전력을 위해 leakage-based 온도 센서로 설계하였으며, 두개의 주파수 밴드 무선 통신 모듈도 해당 칩에 설계되어 있다.
|
| #RF |
|
ᆞSession 6 / High-Performance Receivers and Transmitters for Sub-6GHz Radios
ᆞSession 14 / mm-Wave Transceivers for Communication and Radar
ᆞSession 21 / UWB Systems and Wake-Up Receivers
ᆞSession 22 / Terahertz for Communication and Sensing
ᆞSession 23 / THz Circuits and Front-Ends
ᆞSession 26 / RF Power-Amplifier and Front-End Techniques
|
|
RF 분야는 THz영역까지 포함하여, 6개 세션에서 35편의 논문이 발표되었다. Session 6 (High-Performance Receivers and Transmitters for Sub-6GHz Radios) 과 session 26 (RF Power-Amplifier and Front-End Techniques) 은 RF/mm-Wave 영역에서의 기술을 중점적으로 다루었고, session 21 (UWB Systems and Wake-Up Receivers) 은 UWB 영역, session 14 (mm-Wave Transceivers for Communication and Radar) 는 mm-Wave 영역, session 22 (Terahertz for Communication and Sensing) 와 session 23 (THz Circuits and Front-Ends) 은 THz 영역에서의 기술로 분류되었다.
Session 6은 총 7편의 논문으로, sub-6GHz에 해당되는 5G 및 Wifi에 적용 가능한, high bandwidth 및 low power로 동작하는 기술, out-of-band noise를 낮추는 기술들에 대해 주로 발표되었다. #6.1은 Samsung 에서 발표한 논문으로, 단일 칩으로 2G/3G/LTE/cellular FR1 그리고 dual-band GNSS 동작까지 모두 제공해줄 수 있었다. 또한 저전력 동작을 위해 TX 단에 dynamic biasing 및 adaptive supply voltage 기술을 적용하였다. #6.2는 Delft 공대에서 발표한 transmitter 관련 논문으로, wide modulation bandwidth 동작 및 power-back-off efficiency 개선을 위해, sign-bit를 활용한 50% LO up-conversion 방식 및 4-way Doherty combiner 구조를 제안하였다.
Session 26은 총 7편의 논문으로, 첫 3편은 5G를 target으로 한 mm-Wave PA, 1편의 mm-Wave antenna-tuner 용 28GHz reflection-coefficient sensor, 2편의 sub-6GHz의 digital PA, 1편의 N-path filter로 구성되었다.#26.3은 조지아 공대에서 발표한 논문으로, 기존의 common-source 방식에서 source에까지 신호를 인가한 형태의 dual-drive 형태의 PA를 제안하였다. 제안한 구조는 30GHz 주파수에서 50% PAE (power-added-efficiency), 60%의 DE (drain efficiency)를 얻을 수 있었다. #26.5는 기존의 switched-capacitor PA 구조에서 일부 capacitor를 floating 시키는 switched/floated capacitor PA 구조를 제안하였다. 이를 통해 power-back-off efficiency 를 향상시킬 수 있었다.
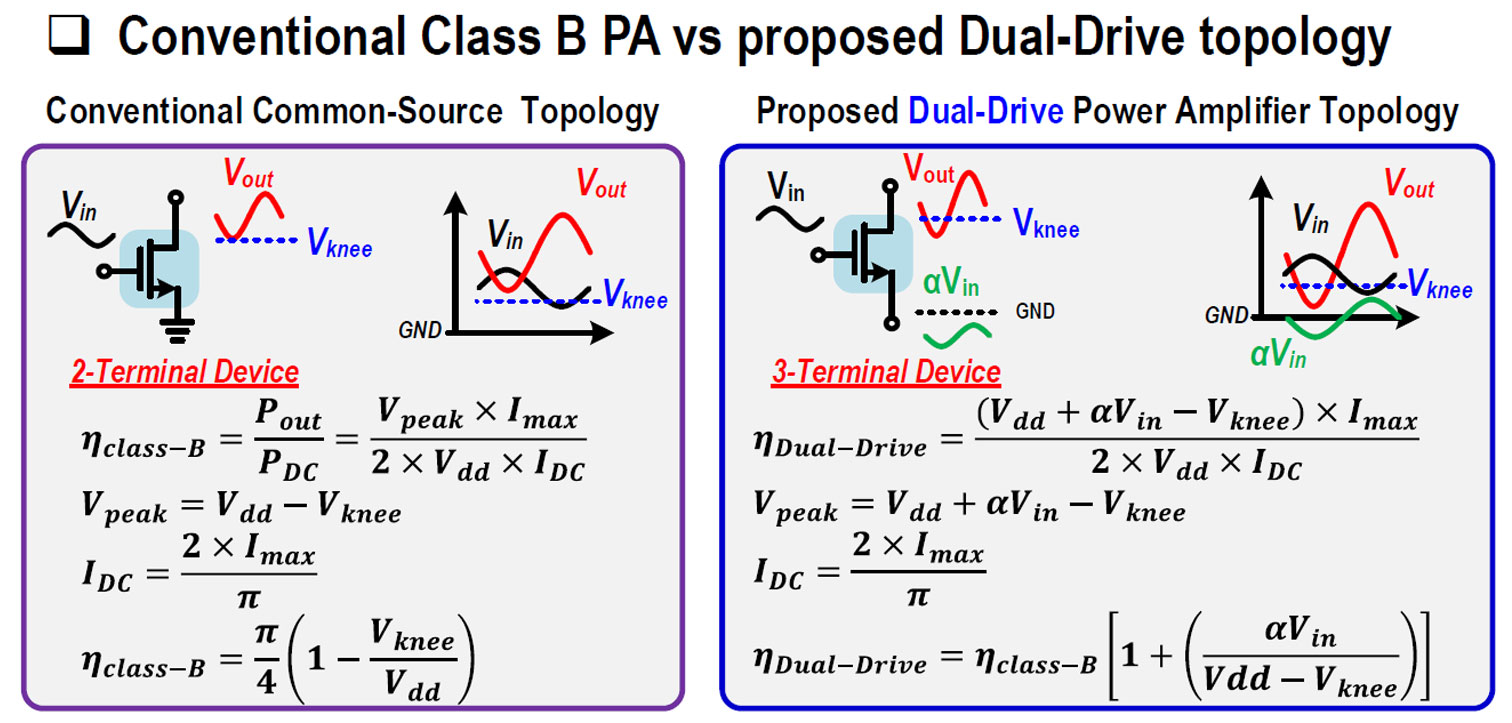 |
| [그림 1] 26.3에서 소개한 dual-drive topology |
|
Session 14는 총 8편의 논문으로, multi-user beamforming receiver, RADAR/LiDAR system, self-interference cancellation, FMCW radar MIMO transceiver 등에 관한 내용이다. #14.1은 UC버클리에서 발표한 논문으로, E-band (71-76 GHz, 81-86 GHz) 영역에서 동시에 16 beam 사용자에게2Gb/s/user 속도로 제공해주는 receiver 설계를 제안하였다. 또한 multi-user MIMO를 제공해주기 위한 저전력을 설계를 위해, 시스템 최적화에 집중하여, 기존의 결과에 비해 매우 낮은 7mW/user/element 성능을 나타내었다.#14.2는 난양공대에서 발표한 논문으로, smart sensing 과 imaging을 위한 phased-array RADAR-LiDAR TRX를 발표하였다. Chip, pulse, LiDAR 방식을 모두 제공하는 multimodal modulation engine을 제안함으로써 early fusion sensor를 구현하였다.
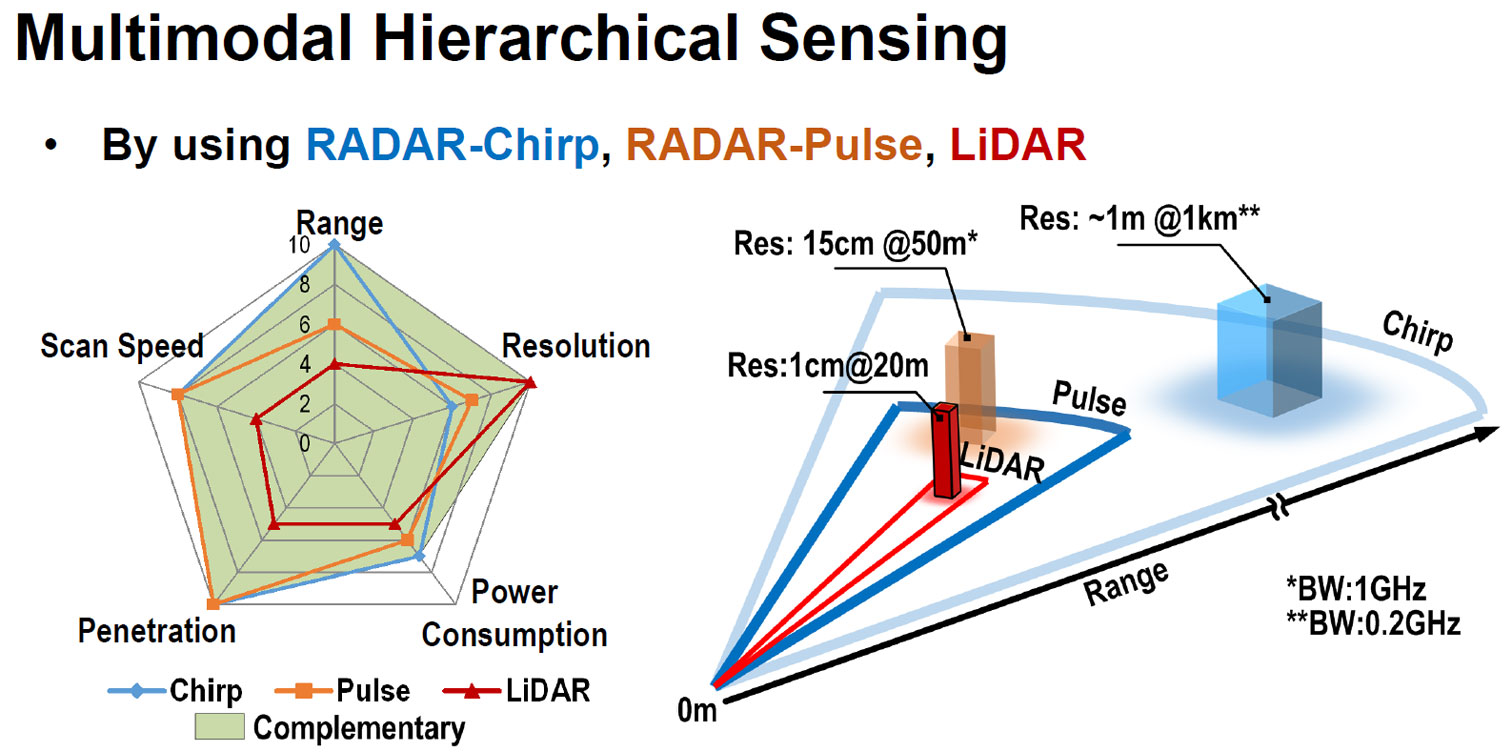 |
| [그림 2] 14.2에서 소개한 multimodal hierarchical sensing |
|
| #Data Converter |
|
ᆞSession 10 / Continuous-Time ADCs and DACs
ᆞSession 27 / Discrete-Time ADCs
|
|
Data Converters 분과에서는 두 세션 (세션 10, 세션 27)에 걸쳐 총 14편의 논문이 발표되었다. Continuous-Time 입력을 갖는 oversampling ADC가 4편 (10.1, 10.2, 10.3, 10.4) 발표 되어 resistive 입력을 갖는 ADC에 대한 관심이 지속되는 것을 확인할 수 있었다. 또한 다수의 논문들이 Noise-Shaping (NS) SAR를 기본 양자화기로 사용하여 확장하는 구조 (10.3, 10.4, 27.1, 27.3, 27.5, 27.6, 27.7)를 채택하고 있어, 미세 공정에서의 oversampling ADC 아키텍쳐는 NS-SAR중심으로 진화하고 있음을 알 수 있다. 고속 ADC구현을 위한 pipeline기법과 (10.5, 27.4, 27.6)과 time-interleaving 기법(10.3, 27.5)에 관한 연구도 꾸준히 진행되고 있음을 알 수 있었고, Beyond 5G RF system을 위한 두 편의 RF DAC논문이 발표되었다. 발표된 논문의 핵심적인 내용을 아래와 같이 간추려 보았다.
|
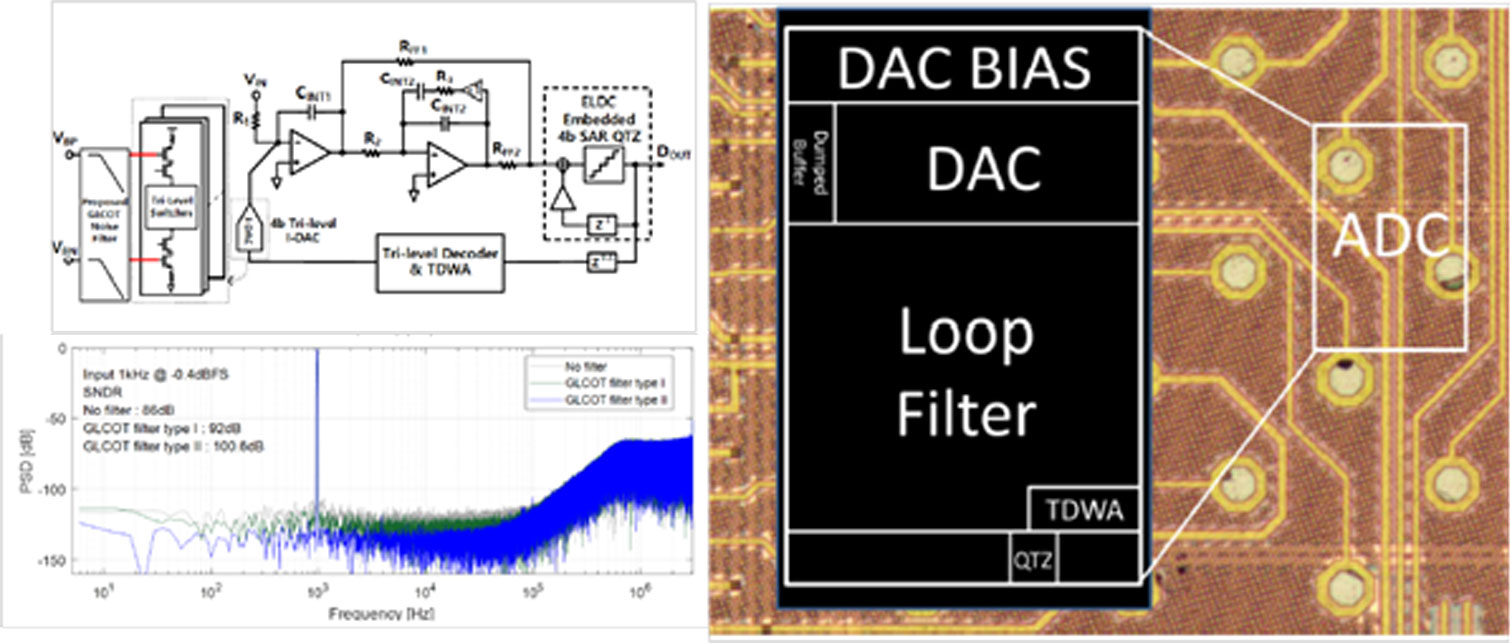 |
| [그림 1] 10.1에서 발표한 ADC의 구조, Die Photo와 성능 측정 결과 |
|
#10.1은 삼성전자에서 발표한 Audio향 CTDSM 이다. 4-bit Multi-bit SAR Quantizer에 3차 CIFF구조를 Biquad와 적분기를 활용하여 opamp 2개만을 이용하여 구현하였다. Feedback Current DAC의 노이즈를 줄이기 위해 bias에 RC filter를 삽입하였는데, 큰 저항을 효율적으로 구현하기 위해 VDD로 Bias된 거의 꺼져있는 PMOS를 저항으로 사용하였고, 여기서 생길수 있는 leakage를 보정해주는 아날로그 루프를 별도로 사용하여 전류 정확도와 노이즈를 모두 개선시킬수 있었다.
#10.2은 UCSD에서 발표한 논문으로 #10.1논문과 같이 24kHz의 bandwidth를 갖는 오디오향 CTDSM이다. 전력소모중 가장 큰 부분을 차지하고 있는 integrator의 opamp의 효율 개선을 위해 Opamp 3개를 stacking하는 current reuse구조의 OTA를 이용하여 current efficiency를 극대화 하였다. 다수의 transconductor를 합치기 위하여 입력에 AC coupling을 사용하였는데, 1-bit quantizer 차용으로 생기는 DAC의 큰 step response를 개선하기 위해 FIR Feedback DAC을 활용하여 AC coupling으로부터 생길 수 있는 문제를 완화하였다.
#10.3은 University of Michigan에서 발표했고, CTDSM의 단점으로 지적되고 있는 Loop Filter가 Tuning이 필요한 점과 Sampling 주파수를 dynamic 하게 바꿀 수 없는 문제를 해결하고자 하였다. 기본 아이디어는 Frontend에 CT loop filter를 채용하여 CT의 장점을 살리면서 뒷단에 CT+DT로 Noise-Shaping을 구현하여 DT DSM의 장점을 추가한다는 것이고, 이것을 기본 골격으로 Timing-Interleaving을 추가하고 Loop Filter를 Bandpass로 구현하여 전체 ADC를 완성하였고, 이를 통해 100MHz의 BW를 갖는 I-Q RF sampling ADC를 구현하였다.
#10.4논문은 University of Texas at Austin 에서 발표한 논문으로 #10.3과 마찬가지로 CTDSM의 단점을 보완하기 위한 CT+DT Hybrid 구조에 대한 논문이다. Biquad 기반의 2차 CT와 2차 Passive Noise Shaping SAR DT를 결합하여 opamp하나로 4차 noise shaping을 구현하였다. High Bandwidth CTDSM에 필연적인 ELD (Excess Loop Delay) 보상을 Feedforward와 Feedback Path를 모두 사용하여 효율적으로 구현하였다.
#10.5은 삼성전자에서 발표한 고성능 12b 600MS/s Pipelined SAR ADC에 대한 논문으로, Residue Amplifier설계의 어려움을 줄이기 위해 Gain이 1인 Residue Buffer로 대체하였고, Stage 2에서의 노이즈 이득 손실을 보완하기 위해 고해상도 2x Time-interleaved incremental ADC를 Quantizer로 사용하였다. 7nm FinFET공정으로 구현하여 Gain Calibration 없이도 Robust한 성능을 보여주었다.
#10.6은 Intel에서 발표한 고성능 12b 16GS/s DAC에 대한 논문으로, 기존에 고성능 DAC에서 주로 사용되는 Current-Steering DAC이 아닌 Capacitor DAC기반의 논문이다. Inverter기반의 Unit Cell에 Linearizing 저항을 추가하여 선형성을 개선하였고, digital segment mismatch calibration을 통해 선형성을 추가적으로 확보하였다. 또한 Mid-band에서의 supply 저항을 줄이기위한 shunt regulation기법을 LDO에 도입하여 고속 동작을 구현하였다.
#10.7 역시 Intel에서 발표한 DAC논문으로 #10.6과 연계된 논문이다. 이 논문은 고성능 ADC에 필연적으로 사용되는 input calibration 신호를 내부적으로 만들어 내기 위한 calibration DAC에 구현에 관한 논문으로, 선형성 확보를 위해 1-bit DAC을 unit으로 하되 Analog 4-tap FIR Filter를 구현하여 multi-bit DAC과 같은 효과를 구현하여 OSR을 적당한 수준으로 쓸 수 있게 하였다. 실제 구현에서는 64GS/s, 4x interpolation을 사용하였는데, 출력을 6GHz on-chip LPF를 통과시켜 4.5GHz의 two-tone test에서 IMD<-85dBC인 고품질의 sinewave를 만들어 냈다.
#27.1 논문은 Tsinghua University에서 발표한 논문으로 Noise Shaping SAR ADC구현에서 가장 핵심이 되는 저전력 Loop Filter 구현에 대한 연구이다. Gain-of-1 Buffer와 Capacitor Stacking을 이용하여 거의 이상적인 적분기 동작을 저전력으로 구현하겠다는 아이디어로 Flipped Voltage Follower를 Buffer로 사용하여 저전력의 ADC를 구현하였다.
#27.2 논문은 University of Michigan에서 발표한 논문으로 기존의 Voltage Buffer기반의 CDAC을 MSB, current-mode로 CDAC을 충방전하는 Charge-Injection Cell을 LSB로 사용하는 Hybrid DAC구조를 사용하여 Area-Efficient하게 고해상도 ADC를 구현하고자 하는 시도이다. Direct Mismatch Detection과 Repeated LSB Decision을 활용하여 14b 이상의 ENOB을 구현하였다.
#27.3 논문은 Georgia Tech에서 발표한 논문으로 Error-Feedback과 CIFF구조의 혼합사용을 통하여 고차 Noise Shaping을 구현하였는데, 이 기법은 하나의 Residue Amplifier로 CIFF와 EF Filter를 모두 Drive함으로써 3차 NTF를 구현할수 있는 장점이 있고, 13b ENOB을 0.4pF의 작은 CDAC capacitance를 가지고 구현하였다.
#27.4 논문은 Tsinghua University에서 발표한 Pipelined ADC논문으로 저전력 Residue Amplifier로Floating Inverter Amplifier(FIA)를 사용할 때 문제가 되는 동작 속도와 Gain 이슈를 해결하기 위한 개선책을 제시한다. 우선 positive feedback을 이용한 gain boosting을 채용한 multi-stage FIA를 제안하여 Gain을 향상시켰고, Dual Reservoir Capacitor사용을 통해 증폭기 동작 초기에는 Fast Settling Mode로 동작시키게 하여 저전력과 고속 동작을 모두 실현하였다.
#27.5 논문은 MediaTek에서 발표한 Time-Interleaved NS SAR ADC에 대한 논문으로 Wi-Fi 6E System에 필요한 DR을 저전력으로 구현한 논문이다. Fully-Passive Loop Filter를 이용한 NS SAR를 기본 Slice ADC로 사용하였고, 전체 ADC에서는 4-way TI ADC로 구현하여 80MHz 대역폭에서 66dB의 SNDR을 얻을 수 있었다.
#27.6 논문은 University of Macau에서 발표한 Noise-Shaping SAR를 Stage1에 채용한 2-0 MASH구조의 Pipelined SAR ADC에 대한 논문으로, Residue Amplifier의 Gain Error에 대한 Sensitivity가 Stage 1의 Noise Shaping에 의해 감쇄된다는 점을 활용하였고, 설계된 ADC는 25MHz Bandwidth에서 75dB의 SNDR을 얻었다.
#27.7 논문은 University of Texas Austin에서 발표한 논문으로, Noise-Shaping SAR를 N-path Filter에 적용하여 Bandpass DSM을 구현하다. 저전력 Floating Inverter Amplifier를 채용한 CIFF구조의 사용과 Time-Interleaved N-pass Filter구조의 저전력 구현의 용이함을 이용하여 전력 효율이 높은 Bandpass DSM을 구현하였다.
|
 |
|
| #Digital Architecture & System |
|
ᆞSession 3 / Highlighted Chip Releases: Modern Digital SoCs
ᆞSession 4 / Processors
|
|
코로나19로 인해 온라인으로 열린 ISSCC지만, 올해 ISSCC에 발표된 논문들을 살펴보면 사실상 코로나19와는 무관한 발전을 이룬 것 같다. 올해 ISSCC 논문들을 Digital System의 관점으로 리뷰해본다.
Session 3
#3.1 이번 ISSCC에서 가장 흥미롭게 본 paper이다. AMD와 Microsoft가 공동제작한 가장 최신의 XBOX가 어떻게 구성되어 있는지를 다양한 설계의 관점에서 설명하였다. 기존 generation인 Xbox One X (2017) 대비 상당한 성능향상을 이루어 낸 것에 대해, 예상되는 소비자의 요구사항인 1) 고 사양의 화질 (e.g., 4K and beyond), 2) 긴 로딩 시간에 대한 문제, 그리고 3) 물리적인 업데이트가 불가능한 콘솔의 문제를 해결하고자 한 강력한 동기가 좋은 설계로 드러났다고 본다. 아키텍처는 Customized 된 Zen2 코어를 사용하였으며, XBOX의 chip이 5nm이 아닌 7nm 공정을 사용한 이유는 작년 ISSCC에 발표한 Zen2 프로세서가 7nm 공정으로 설계된 것에 대한 안정성 확보의 목적이었으리라 추정한다. 아키텍처에서 볼 수 있듯이, 상당히 다양한 모듈이 결합된 혼합시스템이며, 설계의 주안점 중 하나는 다양한 모듈들이 결합됨에 따라 생기는 최적화에 있었으리라 예상 가능하다. 트랜지스터 개수는 지난 XBOX One X 대비 약 3배 증가하였으며, 설계한 패키지도 안정성을 위해 metal layer를 아낌없이 사용한 것을 알 수 있다. 칩 사이즈는 기존 대비 약간 감소하였는데, XBOX 시스템에서 발생하는 열 문제를 해결하기 위한 종합적인 솔루션도 같이 이야기하였다. CPU와 GPU에서는 예상대로 상당한 열이 발생하지만, 그럼에도 불구하고 작아진 form factor와 그 밖의 다양한 power management 기술들은 이제 게임 콘솔을 제대로 만들기 위해 얼마나 다양한 분야의 전문 인력이 투입되어야 하는지를 보여준 흥미로운 논문이었다고 생각한다.
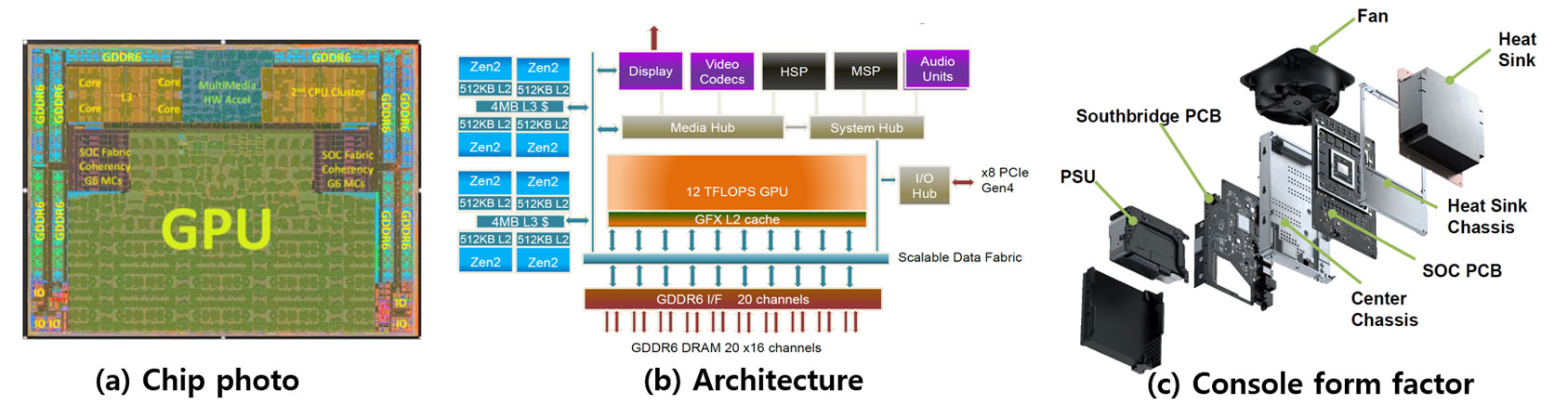 |
| [그림 1] 3.1 XBOX Series X SoC |
|
#3.2 작년에 NVIDIA에서 출시한 A100 GPU에 대해 자세히 공개하였다. TSMC 7nm 공정으로 설계되었으며, XBOX에 사용된 트랜지스터 개수보다 3배 이상 많은 트랜지스터를 집적한 NVIDIA의 설계능력은 언제나 봐도 놀랍다. 인공지능 연산에 더 최적화된 아키텍처가 어떤 방식으로 동작하는지에 대한 내용들을 잘 설명하였다. L2 cache bandwidth 및 DRAM bandwidth 등 bandwidth 증가를 위한 기술들과 아키텍처에 대한 설명도 잘 되어있다. 이번에 발표한 A100 GPU가 NVIDIA가 개발한 이전 GPU들 대비 얼마나 성능향상을 이루는지는 자사 홈페이지등을 통해 잘 나타나 있으니 관심있는 분들은 참고하면 되겠다.
#3.3 Baidu에서 개발한 AI 프로세서에 대한 내용이다. 2011년부터 AI를 시작한 Baidu에서 기존까지 사용하던 FPGA 솔루션이 물리적인 한계로 더 이상 쉽지 않다는 것을 시인했다. 이는 1) AI 관련 소프트웨어 회사들은 저마다 다른 목적으로 AI 기술을 사용하다보니 전용 하드웨어의 필요성이 반드시 있다는 점, 2) FPGA로 하드웨어 솔루션을 마련하던 많은 AI 관련 소프트웨어 회사들이 중장기적으로는 FPGA에서 다른 솔루션을 마련해야 한다는 점, 그러나 3) GPU와 같은 off-the-shelf 제품들은 모든 AI 기업에 유용한 솔루션이 아닐 수 있다는 분석/전망을 가능하게 한다. AI 전용 하드웨어의 중요성을 Google이 TPU를 개발하면서 세상에 알렸듯이, 이후 Baidu를 포함한 많은 AI 회사들에서 다양한 AI 칩을 개발하며 하드웨어의 중요성을 알리기를 기대한다. 칩 설계의 관점에서는, 무엇보다도 삼성 14nm 공정을 이용하여 설계한 것이 매우 반갑다. 아울러 Physical design engineer들이 13개의 metal layer을 사용해야 할 정도로 심각했을 routing의 압박에 주목해본다. 아키텍처의 관점에서는 Baidu에서 응용하는 다양한 AI 연산을 위한 XPU-SDNN (software-defined neural network) engine을 개발한 이유도 이해가 된다. 이제는 많이 상용화가 된 2.5D 패키지를 이용하였으며, PCIE 카드 슬롯에 삽입 가능하도록 만들어 필요 이상으로 AI 가속기를 위한 시스템을 복잡하게 설계하지 않겠다는 Baidu의 전략을 확인할 수 있다. 자체 실험 결과, 상용하는 다른 회사의 chip 들 대비 자사의 chip이 우수하다는 것을 증명하였다.
Session 4
#4.1 MediaTek에서 흥미로운 SoC를 개발하였다. 저전력과 고성능 모두를 잡기 위해 8개의 core 중 1개는 high-performance, 3개는 balance-performance, 그리고 4개는 high-efficiency core를 결합하였다. 모바일 CPU에서 요구하는 상당히 넓은 전력/성능 스펙트럼을 충족하는 기발한 발상이라고 생각하며, physical design engineer 사이에서는 저전력 설계를 위한 2-fin cell, 3-fin cell에 대한 이슈를 간략하게 다루었다.
#4.2 Renesas에서 개발한 자율주행 프로세서에 관한 paper다. SAE 레벨 2,3을 타겟하는 프로세서에서 필요로 하는 연산 및 개발한 프로세서에 대한 spec를 상세하게 서술하였고, 프로세서 설계에 있어 필요로 하는 CNN 아키텍처에 대한 자세한 설명이 추가되어 있다.
#4.3 Berkeley에서 개발한 RISC-V Vector Machine에 관한 내용이다. 개인적으로 XBOX 논문 다음으로 흥미롭게 보았다. 학계 및 팹리스 산업계에 시사하는 바가 크다고 생각하는데, 설계한 chip 그 자체도 흥미롭지만, HW를 설계하기 위한 상당한 개발시간 및 iteration을 줄이는 방법을 제안하기에 그 가치가 더 크다고 생각한다. 요약하자면, 5명의 대학원생이 6개월 내에 24.01mm2에 해당하는 대형 chip을 설계했다는 것이 그 핵심인데, chip 설계에 많은 인력을 동원하기 어려운 중소 팹리스 업계에서는 논문에서 제안한 자동화 방법론을 이용하면 상당한 개발시간 및 비용을 줄일 수 있으리라 생각한다. 다만, 설계 인력이 chip 설계에 필요한 모든 구성요소들의 동작원리에 대해 정확하게 알아야 이와 같은 저인력 설계가 가능하기 때문에, chip 설계의 다방면을 두루 아는 엔지니어의 필요를 역설적으로 더욱 강조하게 되었다고 생각한다.
#4.4 Bologna 대학, ETH 취리히 대학과 Greenwaves Tech. 라는 회사에서 협업하여 제작한 IoT 칩에 관한 논문이다. RISC-V 아키텍처로 구성되어 있으며, cognitive unit이 자동 wake-up 기능을 하도록 제작되어있으며 DNN연산을 위한 가속유닛도 포함되어있다. #4.5 Biomedical AI 프로세서에 관한 논문이다. Biomedical device들에서 더욱 강조되는 저전력의 다양한 AI application을 소화하는 chip을 reconfigurable core을 통해 구현하였다.#4.6 Hitachi에서 최적화 문제를 해결하기 위한 Annealing 프로세서를 설계하였다. Metropolis SA Annealing 방식을 사용하여 기존에 설계된 chip들 대비 가장 많은 144k number of spins을 구현하였으며 eight-way chip-to-chip connection을 지원한 확장성도 확보하여 CPU보다 annealing에서 233배 빠르고 972배 낮은 전력의 성능을 구현하였다. #4.7 초해상도 (Super Resolution) 프로세서와 관련된 논문이다. 올해 ISSCC에 초해상도와 관련된 논문이 1개밖에 없다는 것은 사실 많이 놀라웠다. 40nm TSMC 공정으로 구현하였으며, 기존 논문들 대비 약 1/3정도되는 사이즈로 external memory access 없이 구현한 것이 이번 논문의 특징이다.#4.8 삼성에서 자사의 5nm 공정을 이용한 Video Decoder를 선보였다. Chip 구현을 위한 새로운 아키텍처에 대한 분석은 미뤄두더라도, 5nm 0.7V 공정을 이용하여 설계한 Video Decoder는 삼성 파운더리의 자사 공정에 대한 자신감을 드러낸 전략적인 노출이 아닌가 생각한다.
 |
| [그림 2] 4.8 삼성의 Video Decoder의 specifications. 자사의 5nm 공정을 사용한 것에 주목한다 |
| #Digital Circuits &memory |
|
ᆞSession 12 / Innovations in Low-Power and Secure IoT
ᆞSession 15 / Compute-in-Memory Processors for Deep Neural Networks
ᆞSession 16 / Computation in Memory
ᆞSession 24 / Advanced Embedded Memories
ᆞSession 25 / DRAM
ᆞSession 29 / Digital Circuits for Computing, Clocking, and Power Management
ᆞSession 30 / Non-Volatile Memories
|
|
Session 12 (Innovations in Low-Power and Secure IoT)의 #12.1 논문에서는 AIoT 어플리케이션의 에너지 효율을 높이기 위해 always-on clock-free level-crossing ADC, asynchronous spike-based feature extractor, 그리고 CNN-based intelligent inference engine을 사용하는 general-purpose event-driven wake-up IC가 제안되었다. #12.3 논문에서는 IoT의 보완 문제를 해결하기 위하여 power amplifier의 spectral regrowth를 RF fingerprint (IoT의 ID)로 사용하는 advanced PUF solution이 제안되었다.
Session 15 (Compute-in-Memory Processors for Deep Neural Networks)의 #15.1 논문에서는 HW의 energy efficiency 뿐만 아니라 SW-mapping efficiency를 향상시키기 위하여 in-memory computing programmable core array, digital near-memory computing, 그리고 localized buffeing/control을 기반으로 하는 scalable neural-network inference accelerator가 제안되었다. #15.2 논문에서는 energy efficient를 높이기 위하여 zero skipping (skipping zero-valued activations and weights), shared ADC using ping-pong CIM, 그리고 digital-predictor-assisted adaptive bit-precision을 이용하는 CIM neural-network processor가 제안되었다. #15.3 논문에서는 6T/8T/10T SRAM 기반 CIM array로 기인되는 메모리 density 제한 문제를 해결하기 위해 3T dynamic-analog RAM 기반 CIM Macro가 제안되었으며, ADC power 감소를 위하여 analong sparsity를 이용하는 ADC skipping technique을 CIM Macro에 적용하였다. #15.4 논문에서는 energy efficiency를 높이기 위하여 DNN을 compress하는 tensor-train decomposition method가 사용된 in-memory-computing processor가 제안되었다.
Session 16 (Computation in Memory)의 #16.1 논문에서는 차세대 메모리 중 하나인 Resistive RAM (ReRAM or RRAM)을 이용하는 4Mb 8b-precision (8b-input and 8b-weight MAC operations) CIM Macro를 선보였으며, 저전력/고성능/고정확도를 위해 asymmetric group-modulated input scheme, weighted current-to-voltage signal stacking converter, 그리고 hybrid-precision voltage-mode readout scheme을 적용하였다.#16.2 논문에서는 고성능 logic transistor와 monolithcally 연결되는 1T1C embedded DRAM (eDRAM)을 사용하는 eDRAM-CIM prototype을 선보였다. #16.3 논문에서는 energy efficiency와 signal margin (against transistor process variation)을 향상시키기 위해 segmented-BL charge-sharing scheme, source-injection local-multiplication cell, 그리고 prioritized-gybrid-ADC을 이용하는 SRAM CIM macro가 제안되었다. #16.4 논문에서는 all-digital SRAM 기반 full-precision (programmable input bit-widths of 1-8, signed or unsigned, programmable weight of 4-16bit) CIM macro가 제안되었다.
Session 24 (Advanced Embedded Memories)의 #24.1 논문에서는 고성능/저전력 8T SRAM을 위한 single-ended current-sense amplifier가 제안되었다. #24.2 논문에서는 the smallest bitcell size, reliable write operation을 위한 self-adaptive delayed termination scheme, 그리고 reliable read operation을 위한 multiple cell reference를 기반으로 하는 state-of-the-art RRAM이 제안되었다. #24.3 논문에서는 SRAM margin과 power/performance/area (PPA)를 향상시키는 3nm gate-all-around (GAA) SRAM design이 제안되었다. #24.4 논문에서는 small macro를 타겟으로 하는 고성능/저전압 standard-cell based 16T SRAM macro가 제안되었다.
Session 25 (DRAM) 논문은 역시나 모두 기업체(삼성2, SK하이닉스1, 마이크론1)에서 발표하였다. #25.1과 #25.3 논문에서는 22-24Gb/s/pin의 maximum pin speed를 가지는 next-generation graphics application을 위한 8Gb GDDR6 DRAM이 소개되었다. #25.2 논문에서는 low power mobile application을 위한 sub-1V 16Gb LPDDR5 DRAM이 소개되었다. #25.4 논문에서는 machine learning application을 위한 삼성의 HBM2 기반 processing-in-memory (HBM-PIM)인 20nm 6GB function-in-memory (FIM) DRAM이 소개되었다.
Session 29 (Digital Circuits for Computing, Clocking, and Power Management)의 #29.1 논문에서는 active-feedback-based read & in-situ write verification을 이용하는 hybrid compute-in-memory/digital RRAM macro가 제안되었다. #29.2 논문에서는 partial differential equation을 풀기 위한 dynamic-precision bit-serial graph accelerator가 제안되었다. #29.3 논문에서는 고성능 SoC를 타겟으로 하는 fast-lock (80ns), wide-range (0.4-to-6.5GHz) clock generator가 제안되었다.
Session 30 (Non-Volatile Memories) 논문은 모두 기업체(SK하이닉스1, 인텔1, 삼성1, 키옥시아1)에서 발표하였다. #30.1 논문에서는 SK하이닉스에서 peripheral-circuit-under-cell-array (PUC) architecture를 사용하는 176-stacked 512Gb 3b/cell (TLC) 3D NAND flash memory를 선보였으며, PUC architecture를 사용한 기존의 128-stacked 3b/cell 3D NAND (7.8Gb/mm²) 대비 38% 향상된 10.8Gb/mm²의 bit density를 달성하였다. #30.2 논문에서는 인텔에서 CMOS-under-array technique을 사용하는 144-tier (stacked) 1Tb 4b/cell (QLC) 3D NAND flash memory를 선보였다. #30.3 논문에서는 삼성에서 cell-over-pari (COP) technique을 사용하는 7세대 170+ stacked 512Gb 3b/cell 3D NAND flash memory를 선보였다. 30.4 논문에서는 키옥시아(구 도시바)에서 circuit under array (CUA) technique을 사용하는 170+ stacked 1Tb 3b/cell 3D NAND flash memory를 선보였다. 참고로 PUC, CMOS-under-array, COP, CUA는 모두 같은 뜻 다른 표현으로, 면적 효율을 높이기 위해 peripheral circuit을 memory cell array 아래에 배치하는 기술을 의미한다.
|
 |
|
| #ML |
|
ᆞSession 9 / ML Processors From Cloud to Edge
|
|
Machine Learning Processor(Session 9)는 Cloud와 Edge 컴퓨팅을 타겟으로 하여 총 9편의 논문이 발표되었으며, 이 중 3편은 삼성, IBM Research, Sony에서 발표했다. 대부분의 가속기는 높은 전력 효율을 선보인 반면 초저전력 프로세서도 보였다. 처음 7편의 논문은 이미지 처리를, 마지막 2편의 논문은 음성 인식을 타겟 어플리케이션으로 제작되었으며, 이번 후기를 통해 7개의 이미지 처리를 위한 프로세서 논문에 대해 간략하게 살펴보고자 한다.
#9.1은 IBM Research의 논문으로서 low-precision을 사용하여 Training (fp16, hfp8)과 Inference (int4, int2)를 가속한다. 총 4개의 AI 코어가 두 개의 ring bus 형태로 연결되어 칩 내부의 코어 간 통신과 멀티칩 통신을 담당하며, 각 코어는 2개의 corelet이 2MB L1 cache를 공유하는 구조이다. 각 corelet은 training/inference engine으로 구성된 mixed precision engine의 8x8 배열로 이루어있다. Clock-edge skipping을 통해 복잡한 레이어를 선별적으로 쓰로틀링하는 workload-aware throttling의 구현으로 제한된 전력 안에서 가장 높은 성능을 갖도록 조종하는 기법을 제안하였다. 하나의 칩뿐만 아니라 여러 개의 multi-chip system을 위한 구성이 돋보인다.
#9.2는 중국 Tsinghua 대학교의 논문으로 불필요한 연산과 메모리 접근을 줄이기 위하여 Effective-weight-convolution, error-compensation-based prediction, residual-pipeline 모드에 기반한 quantized network acceleration processor를 제안했다. 수학적인 인수분해를 통해 MAC 횟수를 줄이기 위한 dataflow 와 residual-pipeline의 구현으로 off-chip memory access를 줄인 것이 주된 아이디어이다.
#9.3은 서울대학교에서 발표한 Training Processor로써 Leaky ReLU 등의 사용으로 non-sparse 네트워크의 학습과 추론을 가속하는 것이 목적이다. 이를 위해 shared exponent bias를 활용한 fp8 포멧의 사용과 24way fused multiply-add tree 회로, 2D 라우팅 기법을 제안한다. 전체 프로세서는 4x16 개의 PE array에 특화된 2D input/output routing으로 구성되며, 각 PE는 24-way FMA tree와 high-precision adder, scratchpad memory를 탑재하였다. Input/output에서의 routing 기법으로 전체 칩 대비 사용하는 면적과 에너지 비중을 대폭 줄였으며, 외부 메모리 접근까지 43%나 줄이고 4.8 TFLOPS/W의 높은 성능을 보여주었다.
|
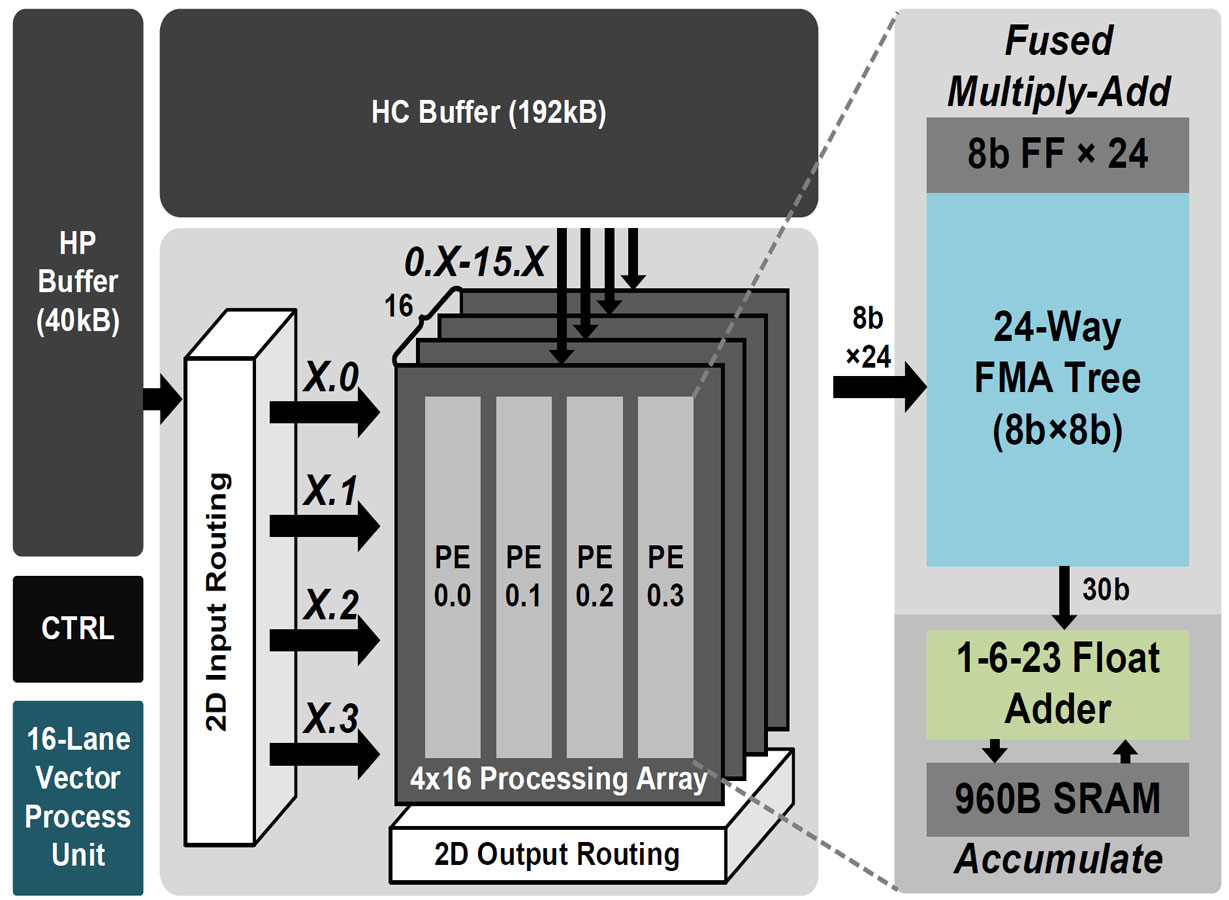 |
| [그림 1] Training을 위한 프로세서 모식도 |
|
#9.4는 KU Leuven의 Probabilistic Inference 가속기에 관한 논문으로 메모리 계층에 최적화된 스트리밍 연산 기법과 가변 정확도 연산법, 컴파일러 최적화가 주된 아이디어이다. 총 64개의 연산 유닛으로 구성되며 컴파일러가 Sum-Product Network를 층으로 분리된 subgraph로 변환하여 병렬 처리한다. Greedy clustering 기반의 partitioning으로 쓰루풋을 두 배 늘렸으며, local data reuse rate를 높이 가져가도록 메모리를 계층화하였다. 가변 정확도와 스트리밍 연산 기법 등, 기존의 개념을 사용하여 새로운 응용에 적용한 프로세서이지만 비교군이 ASIC이 아닌 점이 아쉽다.
#9.5는 삼성에서 발표한 Neural Processing Unit으로 3 [core] x 2048 [MAC/core]의 거대한 연산 가속기이다. 재구성가능한 adder-tree 기반 datapath와 feature map zero-skipping을 통해 높은 에너지 효율을 도모하고, weight/FM 압축으로 메모리 용량과 대역폭을 줄이며, 빠른 resource scheduling을 통해 MAC 연산 시간과 DMA를 병렬화한 것이 특징이다. 본 가속기는 5nm 공정으로 5.46mm²를 차지하는 방대한 크기의 가속기임에도 불구하고 실질적으로 높은 에너지 효율과 면적 효율을 달성한 것이 돋보인다.
#9.6은 Sony의 CMOS Image Sensor와 CNN Processor를 stacking한 프로세서이다. CNNP는 image signal processor (ISP), digital signal processor (DSP), 메모리로 구성되며 CNN 가속을 위해 제작된 DSP가 주요 내용이다. DSP는 높은 연산 밀도와 기본 연산밀도를 갖는 이종코어로 구성되어 CNN을 가속하거나 기존 DSP 연산을 수행하며, Tensor DMA의 집적으로 데이터 포멧과 구조를 변환할 수 있게 설계되었다. 하지만 DSP 내부에서 CNN에 특화하기 위한 가속기 구조의 독창성이 돋보이지 않은 점이 아쉽다.
|
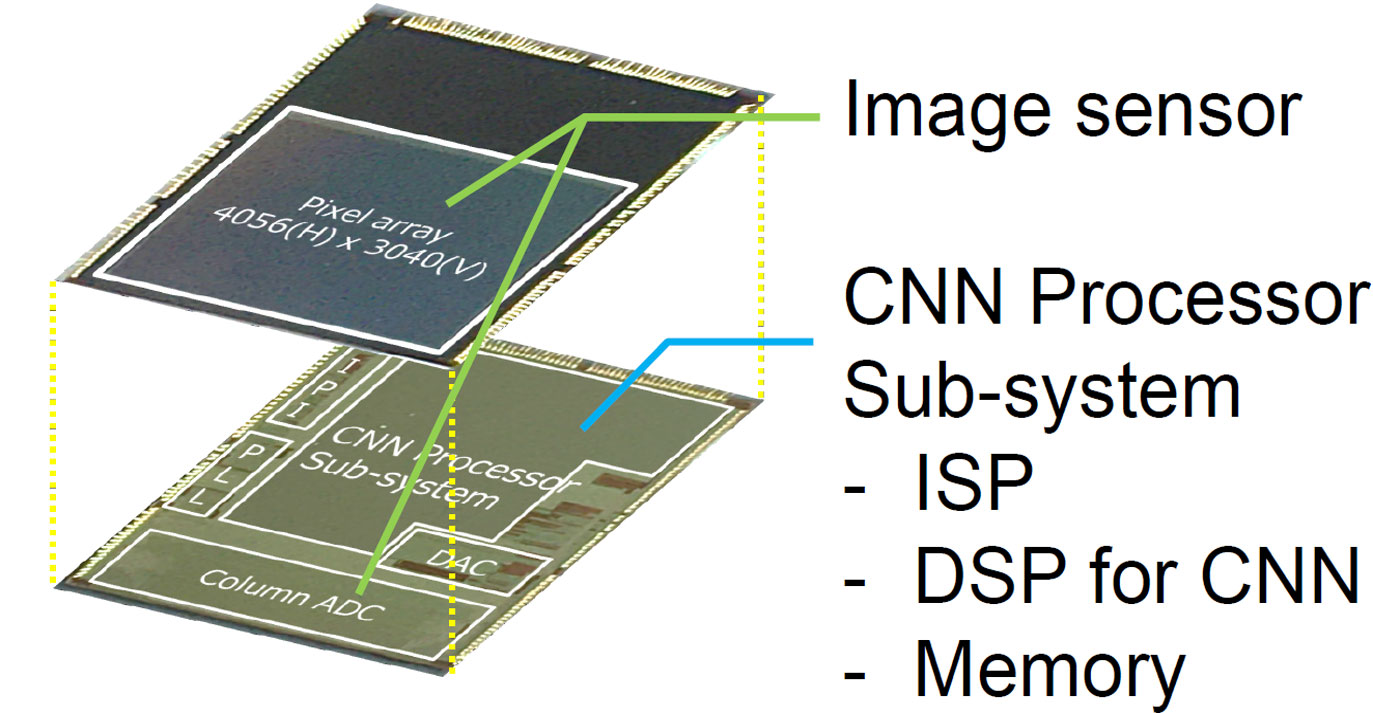 |
| [그림 2] 3D Stacking을 통한 CIS와 CNNP 프로세서 모식도 |
|
#9.7은 Nanyang Technological University의 Hand Gesture Recognition을 위한 multi-classifier system 가속 칩으로 비교적 가벼운 2-layer Edge-CNN을 사용하여 전력과 시간 지연의 overhead를 감소시키면서도 decision tree를 통해 정확도를 향상하고, Edge-CNN 코어 내부의 연결을 통해 높은 data reuse rate를 달성하며, 에러에 강인한 Sequence Analyzer로 dynamic hand gesture 인식률을 높인 점이 주요 아이디어이다. 전반적으로는 기존의 하드웨어와 크게 다르지 않지만, majority voting을 통한 Sequence Analyzer의 집적으로 움직임을 포착하며, 매우 낮은 전력으로 (184㎼)실시간 동작 가능한 것이 특징이다.
|
| #Image Sensor |
|
ᆞSession 7 / Imagers and Range Sensors
|
|
Imagers and Range Sensors에서는 Industry에서 6개, Academia에서 3개의 논문을 발표하여 총 9개의 훌륭한 논문이 발표되었다. 2019년 이후로 세션 이름도 기존의 Image Sensors에서 Image Sensors & ToF Sensors (2020년) 혹은 Image Sensors & Range Sensors(2021년)등으로 변경되면서, 거리센서에 대한 다양한 연구가 활발해지고 있으며, 또 이러한 연구에 대한 관심도가 높아지고 있음을 알 수 있다. 올해 발표된 논문 9개 중 첫 5개의 논문이 모두 거리센서에 관한 내용이다. ToF센서 시장에서 높은 시장점유율을 나타내는 소니의 경우, 다양한 응용을 위한 ToF센서외에 고사양의 CIS들을 선보였으며, 삼성 역시 ToF센서와 초소형 픽셀크기를 갖는 CIS를 발표하여 높은 주목을 끌었다. 또한 UNIST와 EPFL에서 제안한 ToF센서 역시 새로운 구조의 Time-to-digital converter(TDC)에 대한 흥미로운 연구내용을 담고 있다. 이번 후기를 통해 일부 논문에 대해 간략히 살펴본다.
#7.1은 삼성에서 발표한 1.2M픽셀 iToF (indirect ToF) 센서는 4-tap 3.5μm의 Shared-pixel 구조을 이용하였다. 이 논문에서 기존 iToF (Indirect ToF)에서 발생하는 문제점인 (1)글로벌 셔터동작 시, 노출 중 발생하는 순간적인 높은 전류 및 (2)주변 ToF카메라에 간섭에 의한 신호의 왜곡/정확도저하에 대한 해결방안을 제시하였다. 전체 노출시간을 총 40 time-slots 나뉜 뒤, 그 중 한 개만 선택하여 동작시키는 방법 (Multiple interleaving demodulation)을 통해 전류를 분산시켜 0.9A이하로 순간전류를 감소시키고, Fixed-pattern phase noise도 감소시키는 회로기법을 발표하였다. 또한 각 Packet의 초기 위상을 랜덤하게 변화시키는 Pseudo-random modulation기법을 제안하여, 다른 주변 2개의 ToF카메라로부터 발생하는 신호왜곡을 차단할 수 있음을 보여주었다
|
 |
| [그림 1] 7.1 다수유저 간섭 시, 신호왜곡 차단효과를 보이는 삼성의 측정결과 |
|
#7.2는 UNIST가 발표한 논문으로써 SPAD-based flash LiDAR기반의 ToF센서를 선보였다. 기존의 연구는 dToF(Direct ToF)로부터 생성되는 대량의 데이터처리를 위해서는 복잡한 구조의 TDC가 요구되므로, iToF대비 해상도나 속도를 향상시키는데 한계가 있었다. 이를 해결하기 위해 작은 면적을 갖는 In-pixel zoom histogram TDC구조(two-step, SAR 타입)를 제안하여 병렬로 데이터를 처리하는 방식으로 속도를 향상시켰고, dToF와 iToF장점을 결합하여 거리측정 범위도 넓힐 수 있었다.
#7.3은 소니는 자율주행용 자동차응용에 적합한 긴 거리범위와 높은 해상도(유효화소: 약 11만)를 갖는 MEMS-based SPAD LiDAR센서를 발표하였다. 소형화를 위해 콤팩트한 SPAD (10μm x 10μm)를 개발하였고, SPAD로부터 나오는 신호를 Passive quenching and recharge front-end circuit 기술을 이용하여 905nm의 파장에서 6nsec의 짧은 Dead time을 달성하였다. 또한 차량용반도체 사용을 위한 -40~125℃의 열악한 조건하에서도 안정적인 동작 및 응답속도를 실현하여 신뢰성향상에 기여하였다. #7.5에서는 photon-counting기법을 적용 시, SPAD에서 발생가능한 SNR dip 문제를 해결하여 120dB이상의 높은 Dynamic range를 갖는 구조도 제안하였다.
#7.6는 소니에서 발표한 5천만화소 250fps CIS를 발표하였고, 고속동작을 위해 14b Delta-sigma(ΔΣ) ADC를 설계하였다. 기존의 Single-Slope ADC의 경우 해상도가 높아질수록 대략 2N에 비례하여 속도를 감소시키므로 높은 동작영역을 얻기 위해 낮은 노이즈 특성을 갖는 높은 해상도의 ΔΣADC가 필요하다. #7.3과 마찬가지로 Back-illuminated 3D Stack공정을 사용하였는데, Top layer에 있는 pixel로부터 나오는 신호를 분리하여 Bottom layer의 중심부로 보내면서 pixel의 출력신호길이를 줄여 기생부하성분을 감소시켰다. 또한 4개의 컬럼이 공유된 구조의 Sample & hold 회로에서 Negative feedback기법을 통해 kT/C노이즈를 감소시키고 Pipelined 동작을 통해 추가적으로 동작속도를 향상시켰다.
#7.7는 Université catholique de Louvain에서 발표한 논문으로 이미지센서내에서 이미지검출 등의 기능을 수행하는 In-sensor Convolutional Neural Network (CNN) processing을 발표하였다. 기존의 연구는 외부 칩이 아닌 칩 내부에서 CNN을 수행할 경우 병렬연산이 가능하다는 장점이 있음에도 불구하고, 프로세싱을 위한 회로들이 픽셀 내에 집적되어야 하므로 픽셀피치가 매우 크거나 (> 30μm) 필터, 가중치, Stride값이 고정(hard-wire)되는 단점이 있었다. 이를 개선하기 위하여 9μm의 픽셀피치 내에 1.5b 가중치조절 로직, 픽셀주변회로 및 전류소스를 추가하여 픽셀전류를 통한 곱셈 및 열/행 어레이레벨 에서의 풀링(accumulation)기능을 수행하였다. 65nm 로직공정을 사용함에도 불구하고, 픽셀의 성능 및 에너지효율이 비교논문에 비하여 우월한 것이 매우 인상적이다.
#7.9는 삼성에서 발표한 논문으로 작년 ISSCC (#5.6)에서 0.7 µm의 픽셀크기를 발표한데 이어, 0.7µm 픽셀과 유사한 성능을 보이는 0.64µm 픽셀을 선보였다. 픽셀크기를 줄이면서 Full-well capacity(FWC)를 유지하기 위해 N-PD의 이온주입의 농도 및 Shallow-trench isolation의 깊이를 증가시켰다. 또한 Reset 트랜지스터에서 발생하는 누설전류 감소 및 Source follower의 입력 트랜지스터의 Oxide두께 및 Spacer면적 스케일링을 통해 오히려 0.7µm보다 낮은 암전류를 보이는 점이 흥미로웠다. 픽셀크기가 감소할수록 더 높은 해상도의 이미지센서를 기대할 수 있기에 현재 1억만 화소에 이어 언제쯤 2억만화소의 이미지센서가 발표될지 기대된다.
|
 |
|
|
|
| |





