| #ADC |
|
ᆞSession 16 / High-Speed and Low-Power Techniques for SAR-Based ADCs
ᆞSession 4 / High Resolution ADCs with Linearity Enhancement Techniques
|
|
본 글은 Session 16에 대한 리뷰이다.
2020년 ASSCC에 제출된 SAR ADC의 논문은 high-speed와 low-power를 위한 technique 위주의 논문들이 많이 나왔다. #16.1 논문인 경우 low power를 위해서 low supply에서 동작할 수 있는 ADC를 만들었다. 이 논문에서 low supply로 동작 할 수 있겠 만들어 준 것이 VCM-based LSB-first switching scheme이다.
<그림 1>. 또한 기존의 VCO-based comparator들이 갖고 있는 문제점을 adaptive-latching OSC-based comparator를 사용하였다<그림 2>. 이러한 technique들을 활용하여 8.1~11.1-nW 수준의 SAR ADC를 만들었다. #16.2의 논문은 #16.1 논문과는 high-speed에 좀 더 초점을 맞추었다. Speed 효율을 높이기 위해서 open-loop 증폭기를 사용한 MDAC을 사용하였다. Open-loop 증폭기를 사용하였을 때 발생할 수 있는 문제들을 해결하여 900MS/s에서 10bit의 SAR ADC를 만들었다. 1번째 stage는 (5+1)bit이며 2번째 stage는 5bit으로 총 10bit이다.
|
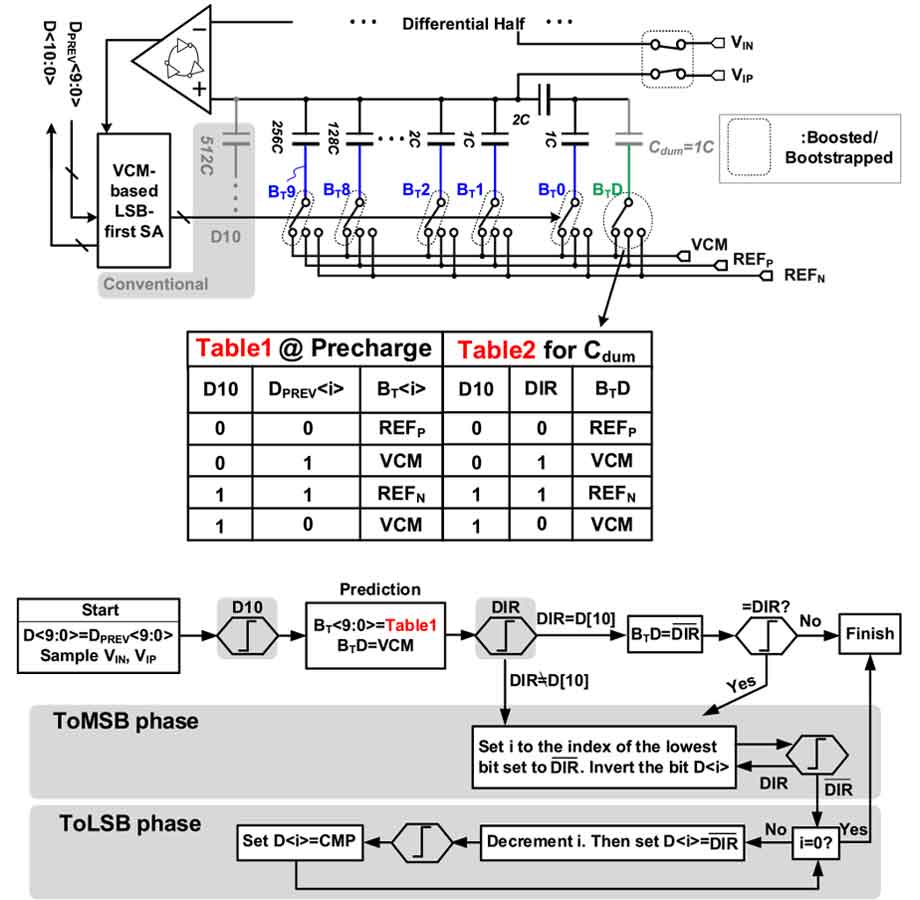 |
| [그림 1] #16.1 에서 소개된 VCM-based LSB-first ADC |
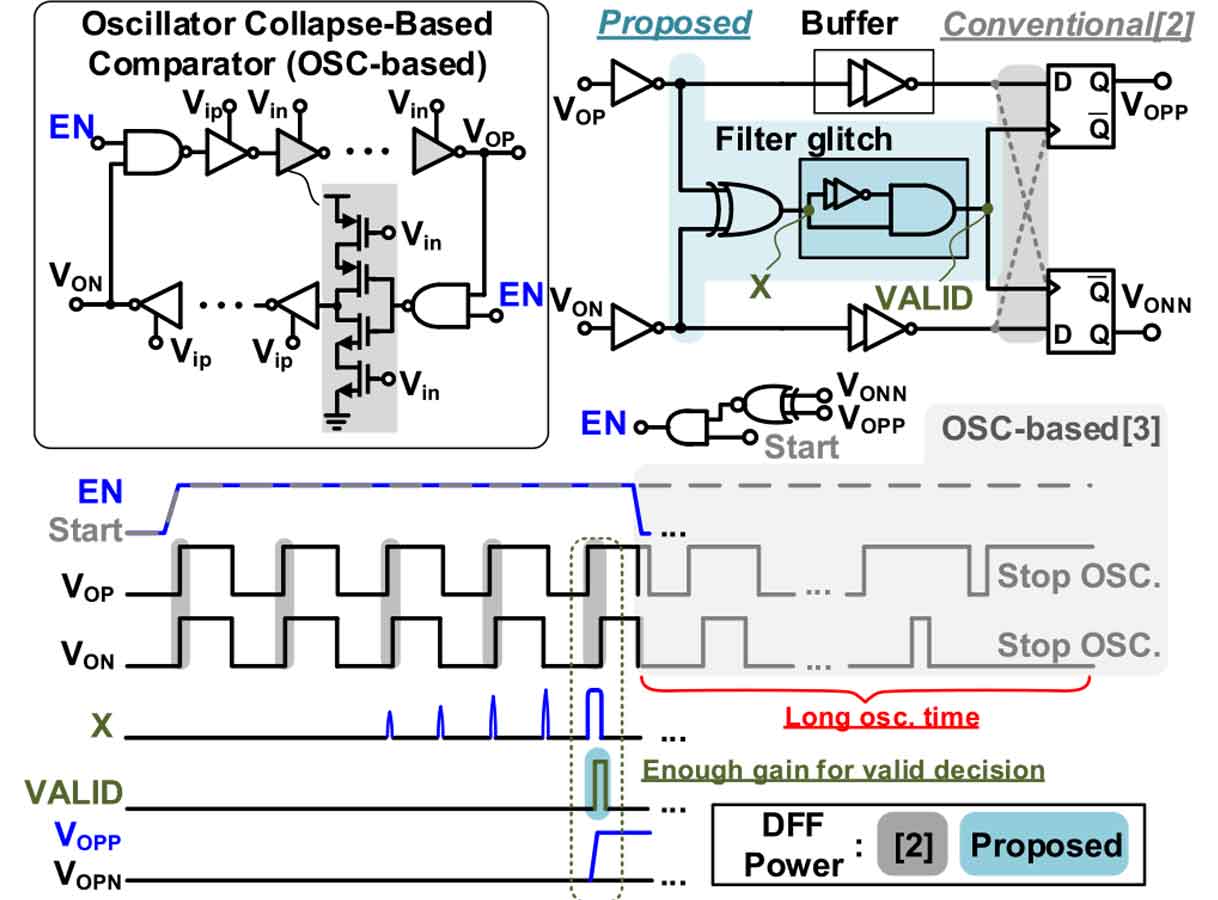 |
| [그림 2] #16.1 에서 소개된 Adaptive-latching OSC-based comparator |
|
#16.3 논문은 앞선 논문들과 다르게 high-speed와 low-power를 둘다 고려하였다. #16.3은 two-step pipelined SAR ADC인데 1번째 SAR ADC stage에서 스위칭 power를 줄이기 위해서 매우 작은 capacitor로 separate DAC을 구현하였다. 또한 dynamic register를 사용하여 즉각적인 DAC switch를 조절하므로 SAR decision delay time을 줄일 수 있었다. 또한 28nm의 공정을 사용하였다. 따라서 2.2mW로 12-bit 200MS/s의 pipelined SAR ADC를 구현할 수 있었다.
본 글은 Session 4에 대한 리뷰이다.
ASSCC 2020 의 4번째 section은 linearity를 향상시키는 technique에 대한 내용들로 구성되어 있다. #4.1은 least-mean-square (LMS) 알고리즘을 사용한 multi-rate back ground calibration을 통하여 온도와 frequency에 의한 variation을 최소로 만든 multi-stage noise-shaping (MASH) delta-sigma ADC이다<그림 1>. 첫 번째 단은 quantizer delay를 충분히 고려하여 설계했다. 따라서 첫번째 단의 두번째 적분기로부터 quantization error를 quantizer delay 동안 충분히 연산할 수 있게 되었다. 이로 인해 finite gain을 가지는 op-amp를 가지고 두 번째 단으로 넘어가는 input signal의 leakage를 최소로 만들었으며 두 번째 단의 distortion도 낮출 수 있었다.
|
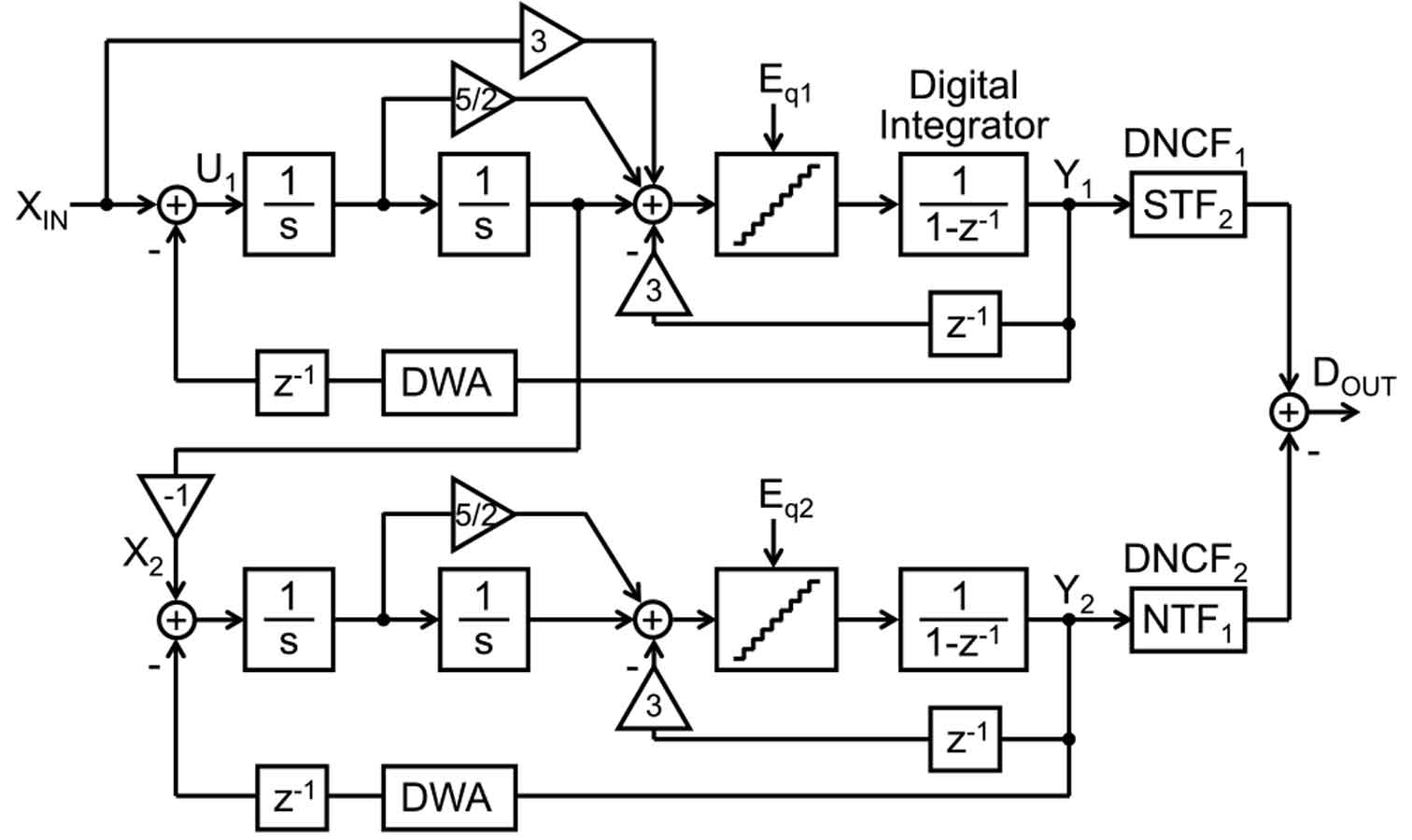 |
| [그림 1] #4.1 에서 소개된 CT MASH 구조 |
|
#16.2 논문은 symmetric 특성을 고려하여 THD 성능을 올리는데 집중하였다<그림 2>. 이 특성으로 DAC mismatch로 생기는 even order distortion을 어떠한 calibration 이나 DEM 없이 없앨 수 있었다. 또한 다른 구조들과 비교 해보았을 때 High-gain amp가 없음에도 불구하고 100dB의 SFDR까지 만들어 냈다.
|
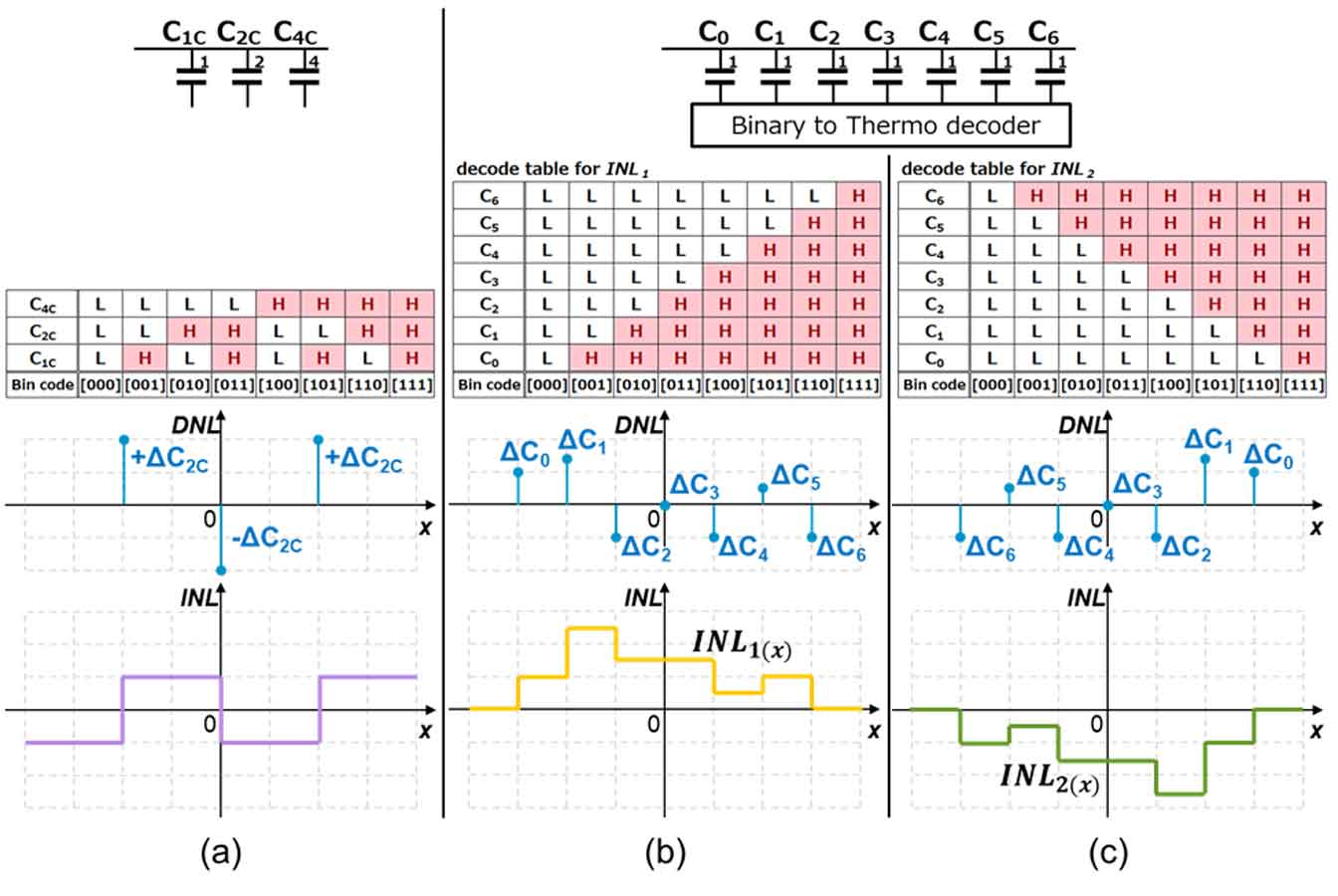 |
| [그림 2] #4.2 에서 소개된 SAR ADC 구조와 timing diagram |
| #Analog #Sensor |
|
ᆞSession 10 / Analog Techniques
ᆞSession 13 / Bandgap and Temperature Sensors
|
|
올해 A-SSCC 2020에는 총 14개 Session에 총 62편의 논문들이 발표되었다. 그 중 Session10 - Analog Techniques에는 5편의 논문이, 그리고 Session13 - Bandgap and Temperature Sensors에는 4편의 논문이 발표되었다.
Session10 - Analog Techniques는 5편의 논문이 발표되었으며, 각 논문 마다 highly configurable
discrete-time low-noise amplifier (LNA), time-domain output-capacitorless low-dropout regulator (LDO), electrocardiogram (ECG) amplifier, impulse response (FIR) filter and infinite impulse response (IIR) filter embedded successive approximation register (SAR) analog-to-digital converter (ADC) 등 다양한 주제의 아날로그 회로 기법들에 대한 논문들이 발표되었다. S10-1는 switched-capacitor (SC) 기반의 series–parallel amplifier (SPA)를 analog front-end (AFE)에 적용하여 AFE의 noise requirements 및 전력 소모를 줄여, 현재 발표된 증폭기 중에서 가장 낮은 0.45의 noise efficiency factor (NEF) 및 0.2 power efficiency factor (PEF) 성능을 가진다. 그림 1과 같이 series–parallel and successive approximation SC scheme을 SPA에 적용하였으며, discrete-time operation에 의한 sampling noise는 높은 oversampling ratio을 통해 우수한 noise 성능을 얻었다.
|
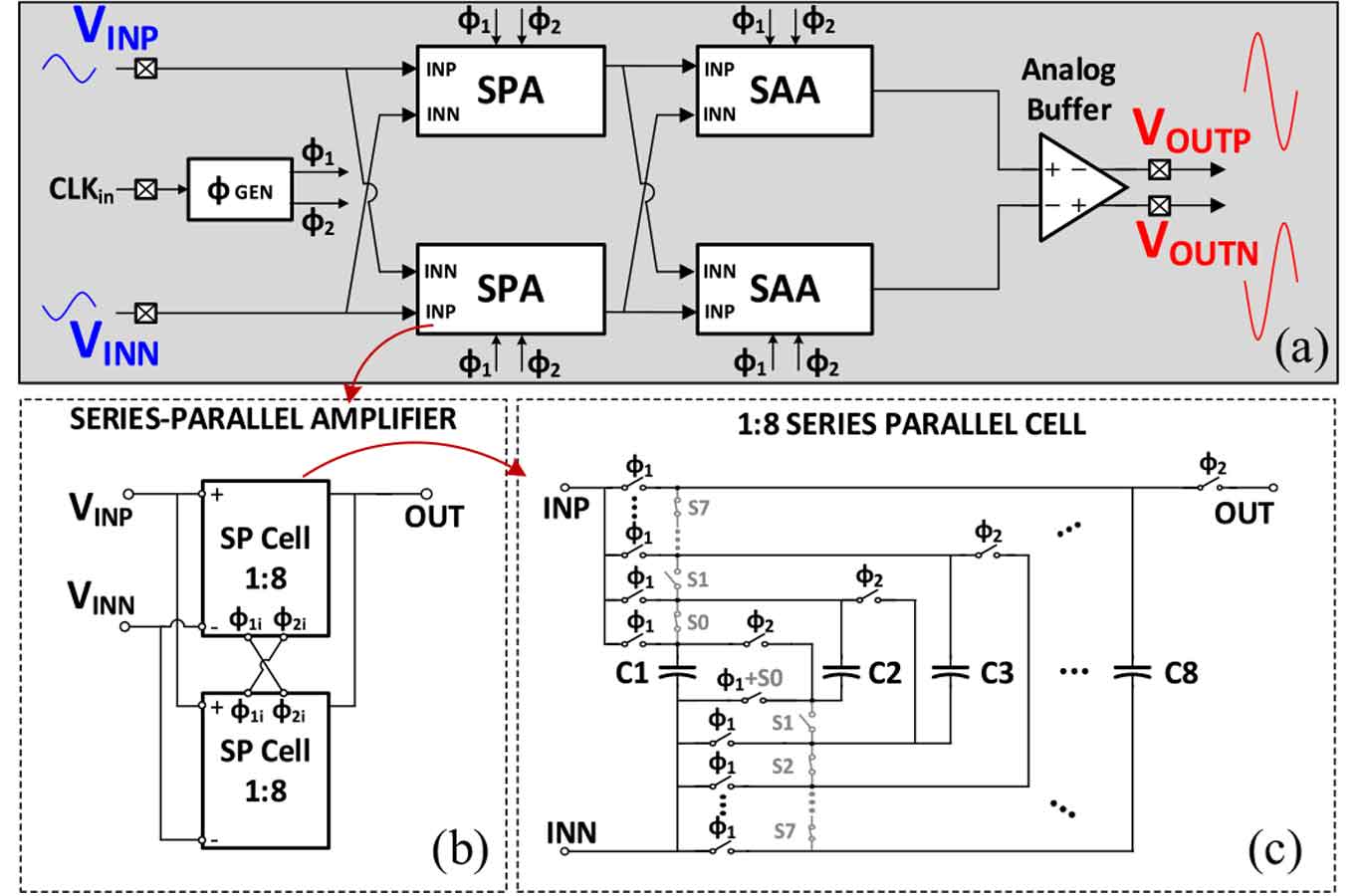 |
| [그림 1] S10-1 논문에서 소개된 discrete-time amplifier의 schematic: (a) total amplifier chain, (b) series–parallel input stage, and (c) implementation of a single 1:8 series–parallel cell |
|
S10-2은 sub-1 V의 core voltage 공급을 위해 기존 LDO들의 단점들을 극복하기 위해 time-domain output-capacitorless LDO를 제안했다. 본 논문의 핵심 아이디어는 fully differential voltage-controlled oscillator (DVCO) comparator를 이용하여, LDO output error voltage를 time-domain signal로 변환시켜 propagation-delay-triggered edge detector를 적용한 frequency comparator (FC)를 이용하여 LDO의 pass transistor의 바이어스 전압을 push-pull resistor들을 통해 컨트롤 하여 전력 효율을 높이는 것이다.
S10-3은 2-electrode ECG signal acquisition 시 발생하는 common-mode interference (CMI)를 해결하기 위하여 active lead bias를 instrumentation amplifier (IA)에 적용하였다. 또한, common–mode rejection ratio (CMRR), the DC electrode offset (DEO) tolerance, 그리고 the input impedance 성능을 높이기 위해 direct electrode offset filtering 및 negative-impedance compensation 제안하는 current-balancing IA (CBIA) scheme에 적용하였으며 linear input transconductance 및 drain voltage regulation을 통해 nominal voltage gain shift < 0.5 % 및 total harmonic distortion (THD) < 0.13 % 등 기존 발표된 연구들 보다 개선된 성능을 얻었다.
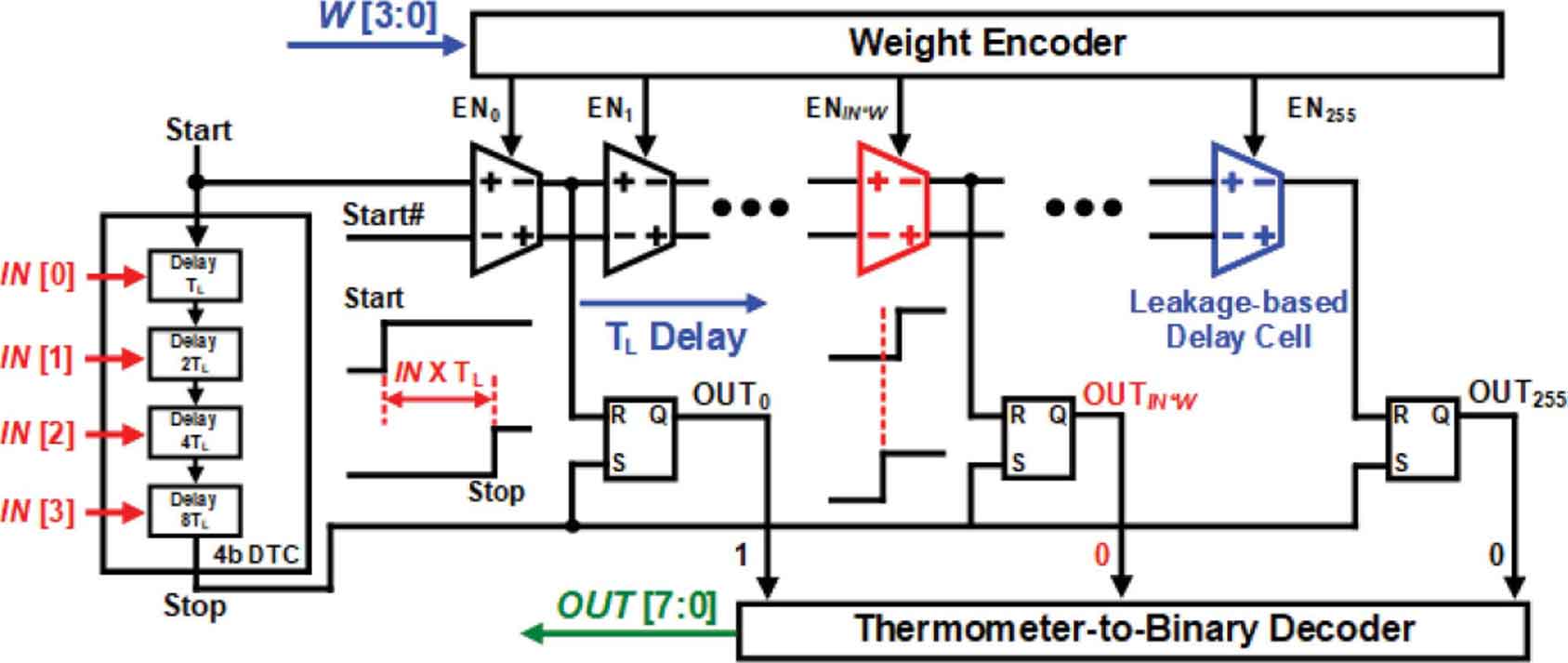
S10-4은 FIR filter와 IIR filter를 10-bit SAR ADC와 함께 적용하는 새로운 방향을 제시하였다. SAR ADC의 capacitive digital-to-analog converter (DAC)에 충전되는 charge들을 FIR filter와 SAR ADC가 주기적으로 공유하면서 DC attenuation 없이 IIR filtering을 가능하게 하였다. 제안하는 회로에서 IIR filtering은 time-interleaved 와 추가적인 두 개의 phase로 최적화하였으며, 제안하는 discrete-time passive 13-tap FIR filter 와 IIR filter embedded 10-bit SAR ADC scheme은 power-efficient, scaling-compatible, 및 PVT-robust 등 장점을 가진다.
S10-5는 input-adaptive control logic을 ECG front-end에 적용하여, AFE의 gain을 입력 신호에 따라 조절 가능하게 하여 집적된 8-bit SAR ADC의 dynamic range (DR)를 common-mode level 근처에서 67.6 dB까지 얻을 수 있다. 본 논문의 핵심 아이디어인 adaptive-gain technique은 매 클럭 주기 마다 입력신호를 두 번 sampling을 통해 동작하는데, 첫 번째 sampling 된 신호는 adaptive logic을 통해 ADC의 gain을 결정하게 되고, 두 번째 sampling 된 신호를 디지털 코드로 변환하며, 제안하는 scheme은 backend calibration process에 의해 동작하게 되어 높은 전력 효율을 갖는다.
Session13 - Bandgap and Temperature Sensors에는 4편의 논문이 발표되었으며, 1편의 bandgap reference 논문과 3편의 온도센서 관련 논문이 발표되었다. S13-1은 KAIST 발표한 논문으로 단일 bipolar junction transistor (BJT)와 proportional to absolute temperature (PTAT)-embedded amplifier에 cascode Miler compensation을 통해 0.0082 mm2의 소면적과 192 nW의 저전력을 갖게 구현하였으며, 0.33 %의 voltage spread(σ/μ) 및 −40 ∼ 140 ℃ 온도범위에서 26.3 ppm/℃의 temperature coefficient (TC) 성능을 가진다.
S13-2는 바오메디컬 어플리케이션 적용을 위한 fully energy-autonomous temperature-to-time converter (TTC)에 대한 논문으로 본 논문에서 최초로 triboelectric energy harvester (TEG)로 converter의 전체 전력을 공급하였다. 본 논문에서 제안한 TTC는 최근 연구들과 비교하여 state of the art 성능을 보이며, 제안한 TTC에 적용한 dynamic leakage suppression full-bridge rectifier (DLS-FBR)으로 reverse leakage current를 1/100로 줄여 연구 결과들 중 가장 낮은 energy-per-conversion을 가지며 5 nW의 적은 전력을 소모한다.
S13-3의 relative inaccuracy (R-IA) CMOS subthermal drain voltage-based temperature sensor는 PTAT 출력의 linearity를 증가시켜 sensor의 accuracy를 증가시켰다. 제안하는 온도센서의 frequency-locked loop (FLL)-based current-to-frequency converter (CFC)를 통해 전력소모 및 공급 전압 변동에 대한 내성을 개선하였다. 제작한 온도센서는 6.5 nW의 전력을 소모하며, −30 ∼ 70 ℃ 온도범위에서 off-chip nonlinearity fitting 이나 post-fabrication trimming 없이 1.7 %의 R-IA 성능 및 75 mK의 resolution 과 2.8℃/V line sensitivity을 가진다.
S13-4는 leakage-based ring oscillator를 사용한 power-efficient temperature-to-digital convertor (TDC)에 대한 논문으로 reversely-biased transistor들을 core inverter 와 supply rails 사이에 더하여 core 회로의 전력소모를 제한했으며 temperature-to-current conversion gain을 개선하였다. 제안하는 TDC는 temperature independent sampling time control을 적용하여 conversion gain과 resolution을 개선하였으며, 0.55 V 전원전압에서 950 pW의 전력을 소모하고 20 ∼ 80 ℃ 온도범위에서 43 mK의 temperature resolution과 −1.6/+2.1℃ 의 maximum temperature error를 가진다.
 |
명예기자 김형섭
- 소속 : 충남대학교 전자공학과 박사과정
- 연구분야 : 아날로그/혼성신호 집적회로설계, 저전력 저잡음 집적회로설계, 센서 인터페이스
회로 설계, 생체신호 계측 회로 설계C
- 이메일 : hanafos24@cnu.ac.kr
- 홈페이지 : icdl.cnu.ac.kr
|
|
| #Biomedical |
|
ᆞSession 17 / Biomedical & Bioinspired SoCs
ᆞSession 18 / Intelligent Memory & AI/ML-Assisted Biomedical SoCs
|
|
ASSCC에서 Biomedical 및 Bioinspired SoC관련해서 Session 17과 Session 18에서 8개의 논문으로 소개됐다. 이번 ASSCC-2020 theme이 “Intelligent Chips for AIoT Era”인 만큼 AI technique을 접목하여 기존 biomedical SoC를 개선시키거나 AI 연산에 efficient한 architecture 회로를 소개했다. 또한 biomedical SoC에서 communication을 줄이고 edge에서 연산을 진행하도록 특정 내부 module들의 개선 방법을 소개했다. 이 8개의 논문 중에서 각 Session의 주제와 밀접하다고 판단되는 논문을 각 세션에서 3개씩, 총 6개의 논문에 대해서 살펴보겠다. 특히 이 두 session의 내용이 밀접해서 따로 구분 짓지 않고 같이 살펴보도록 하겠다.
AI/ML-assist technique의 적용 여부에 대해서 두 그룹으로 나눠서 보겠다. 먼저 적용한 경우에 대해서 살펴보겠다. #17-2는 KAIST & UNIST에서 발표한 논문인데 Deep Neural Network (DNN) 기반 지속적 electrocardiogram (ECG) monitoring을 wearable device에서 이뤄지게 하려면 저전력 구동 및 computation in memory (CIM)이 필수인데 이를 위해 저전력, 고밀도 STT-MRAM을 사용했고 leakage-based delay MAC(LDMAC)으로 inference를 수행했다. 해당 SoC는 STT-MRAM array, LDMAC array, ResNet기반 DNN learning cores (LCs)와 ECG Analog Front End (AFE)로 구성됐다. 여기서 wake up algorithm을 도입해 유의미한 ECG 신호인 게 판별이 되면 켜지게 함으로써 전력 소모를 줄였다. 또한 LDMAC를 통해 leakage current로 time-domain operation을 수행해서 높은 정확도로 저전력 연산을 가능케했다.
|
 |
| [그림 1] LDMAC block diagram |
|
#17-3은 Columbia University와 삼성전자에서 발표한 논문인데 저전력 AI로 각광받고 있는 SNN classifier를 성능보다는 저전력, always-on 동작에 초점을 맞춰서 개선한 연구이다. 저전력 동작을 위해 NTV에서 동작하는 static logic을 사용했고 전체적으로 fully spike-event-driven으로 설계했다. Integrate & Fire (IF) neuron을 asynchronous wake-up 회로와 synchronous FSM으로 구성했고 추가로 clock-gating과 power gating circuits (PGSs)도 배치했다. Synapse 회로도 spike-event-driven 방식으로 구성했고 spike 들어올 때 local clock generator가 시작하게 되면서 적당한 정확도에 전력소모를 크게 줄일 수 있었다.
|
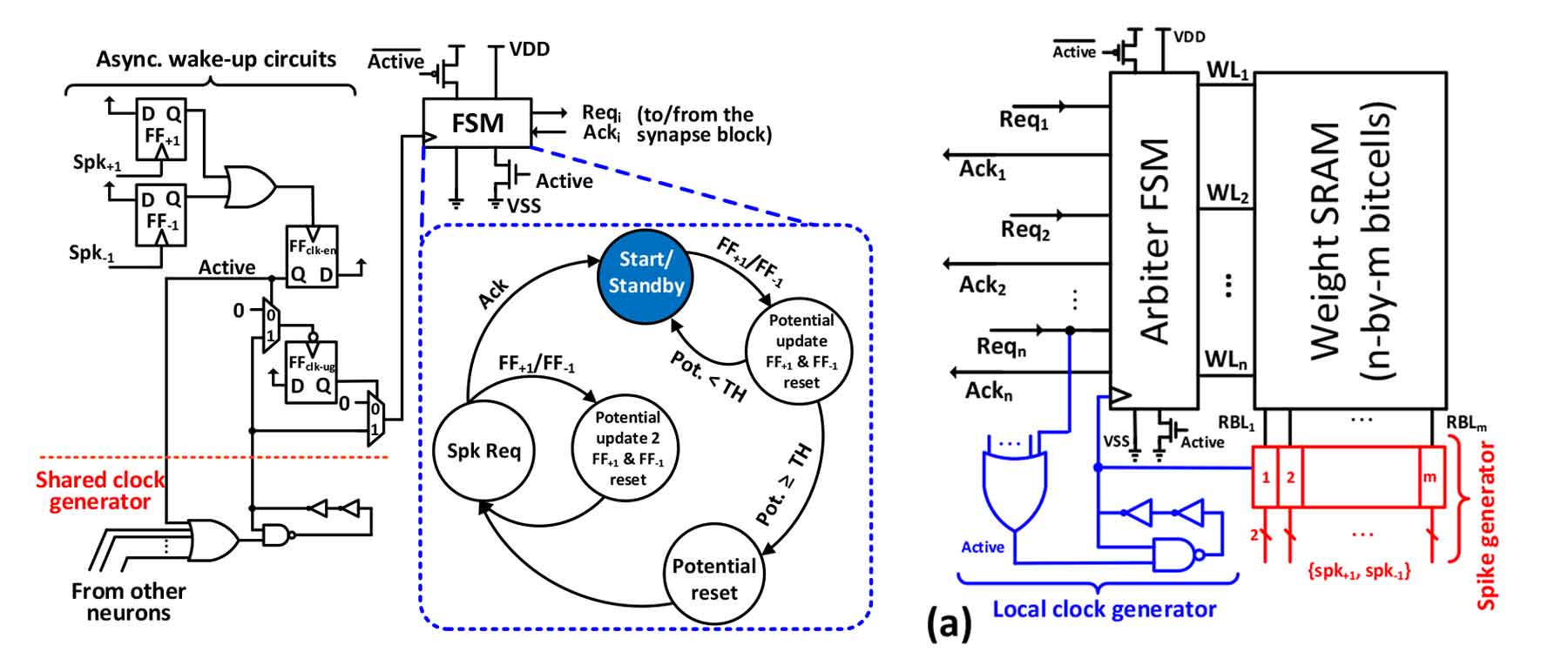 |
| [그림 2] 제안하는 neuron block 구조 (좌), synapse block 구조 (우) |
|
#18-1은 NUS에서 발표된 논문이고 기존 in-memory computing에서는 다른 signal processing task를 고려하지 않았는데 sign/magnitude input을 가능케 하면서 broad-purpose 특징을 가지게 했고 reconfigurable row decoder를 통해 WL을 share하면서 read/write와 in-memory computing 둘 다 진행할 수 있게 됐다. ±CIM SRAM 의 동작을 살펴보면 DTC된 input data를 자리 수별로 받아 sign에 따라 ±WL으로 해당 SRAM access MOS를 해당 시간동안 켜서 ±BL 을 discharge 시키고, 각 연산된 ±BL을 weighted charge sharing으로 통합한 뒤, 그 결과를 SAR ADC로 변환한다.
|
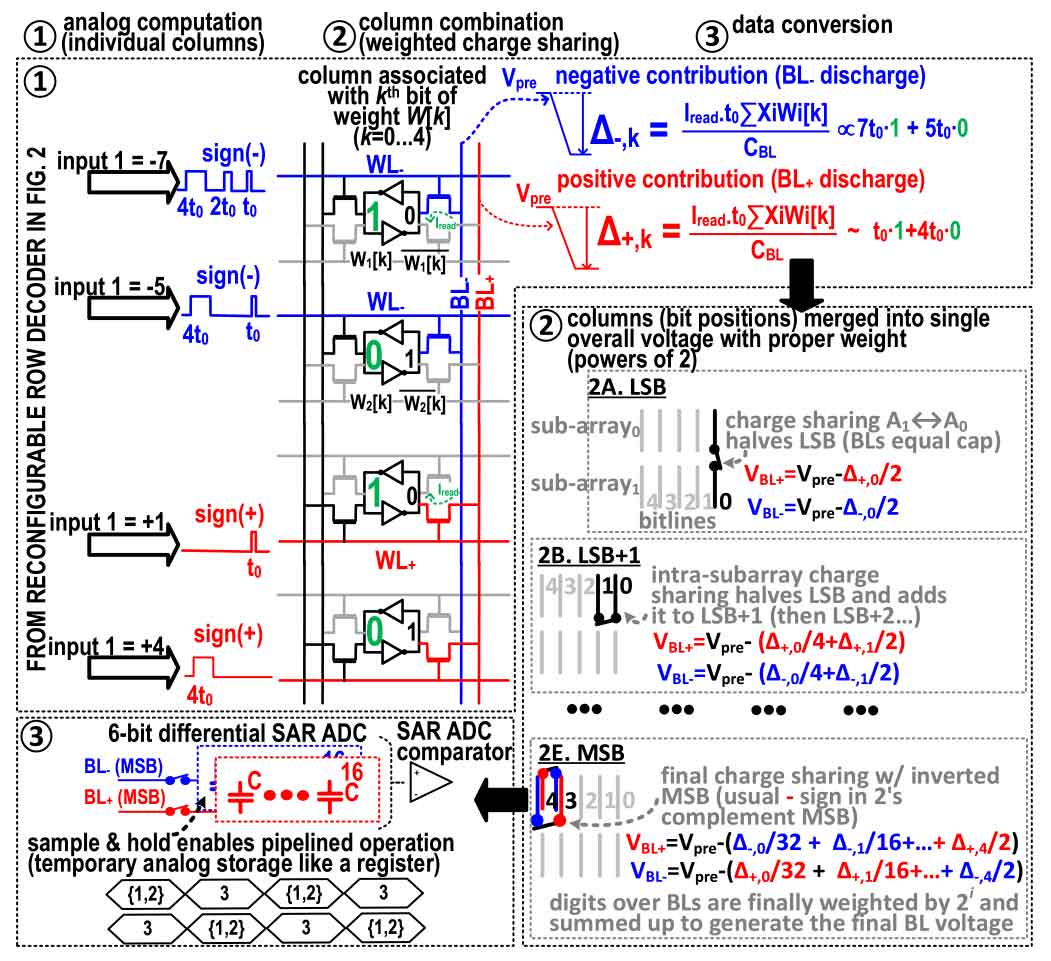 |
| [그림 3] ±CIM array의 회로 동작 (in-memory computing 모드) |
|
#18-3은 NCKU에서 발표한 논문이고 epilepsy suppression을 위해 electrical/optogenetic stimulation 방식으로 수행한다. SoC 구성은 2개의 EEG recording channel, electrical & optogenetic stimulator로 이루어지고 무선으로 programming 가능하다. 여기서 seizure 감지를 CNN 기반으로 감지하게 된다. 또한 power management block을 배치해 무선 충전 량에 대해서 조절하게 된다.
뒷부분은 AI를 적용하지 않은 biomedical SoC 논문들에 대해 살펴보겠다.
#17-1은 BETRC, NCTU, NTU에서 발표한 논문이고 기존에는 sensorineural hearing loss 문제를 해결하기 위해 conventional한 cochlear implant (CI)를 사용했는데 bone-guided cochlear implant (BGCI) 방법이 더 효율적이어서 이를 발전시키는 연구이다. 수정된 SoC 구조는 evoked compound action potential (ECAP) acquisition 회로, charge pumps (CPs), monopolar biphasic constant current stimulation (CCS) stimulator로 이루어졌다. Diagnostic mode에서는 ECAP acquisition 회로와 내부의 electrode-impedance measurement 회로가 켜져서 정보를 수집하고 normal mode에서는 CCS stimulator가 켜지면서 그에 따른 stimulus가 가해지게 된다.
|
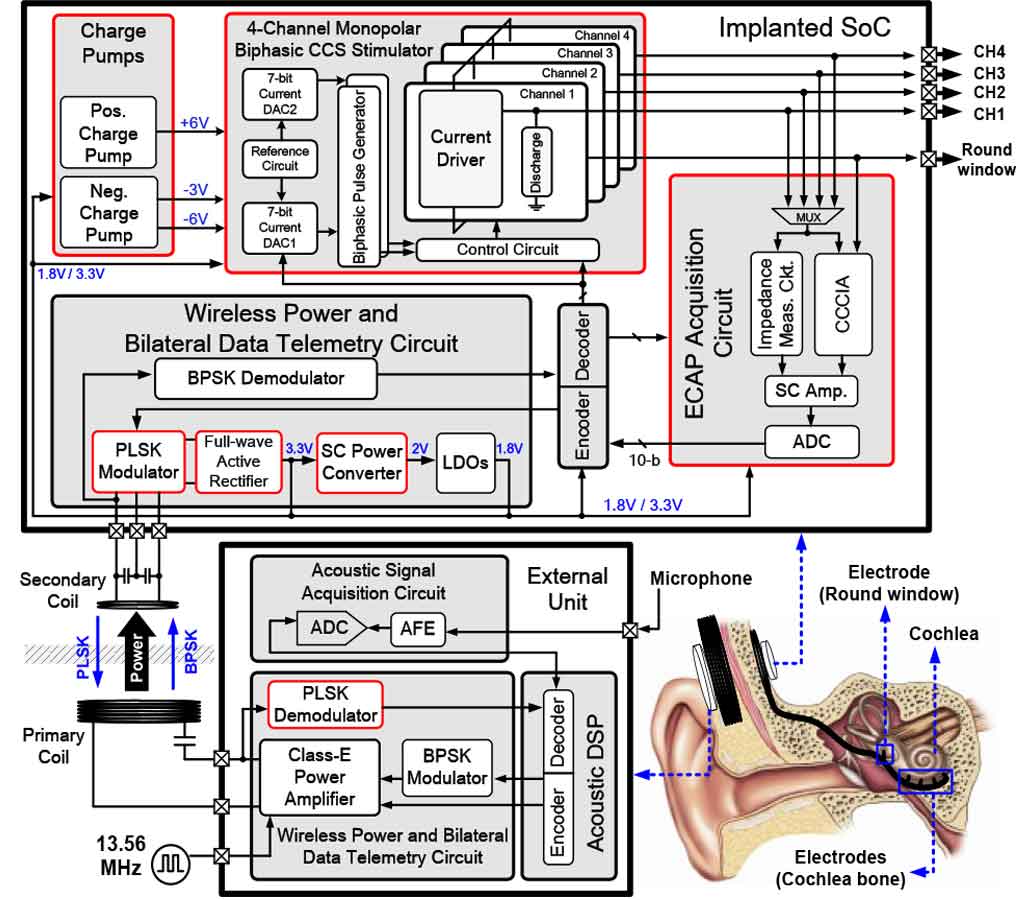 |
| [그림 4] 발전된 BGCI microsystem |
|
#18-4은 LUMS에서 발표한 논문이고 glucose monitoring을 기존 finger-prick이나 glycosylated hemoglobin test가 아닌 near-infrared photoplethysmography (NIR-PPG) 방식으로 noninvasive하게 수행하는 방법에 대한 연구이다. 전체적 구조는 LED driver, differential DC current subtraction (DCS)를 위한 current DAC가 결합된 fully differential readout, glucose prediction processor (GPP), automatic LED/DACs control unit (ALDCU)로 이루어졌다. 여기서 전력소모를 줄이기 위해 single wavelength 방식과 PPG readout을 chopper가 결부된 TIA로 이루어진 fully differential readout을 도입했다. Glucose prediction 연산은 nonlinear medium gaussian support vector machine-learning regression (NGM-SVR)을 통해 수행했다.
|
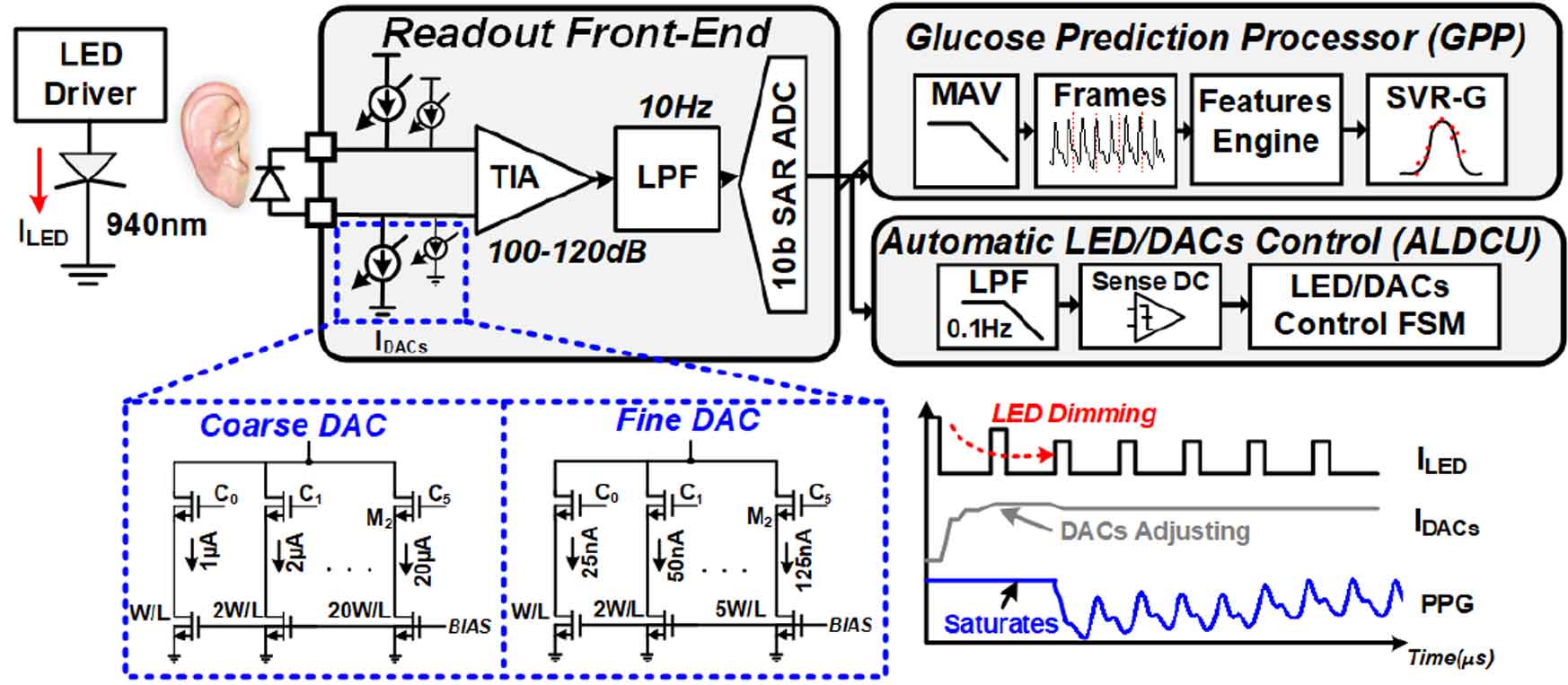 |
| [그림 5] 지속적 glucose monitoring SoC block diagram |
|
전체적인 트렌드를 보면 저전력을 신경 써서 알고리즘 및 회로를 추가하려고 노력했고 모든 논문이 tape-out된 chip이 있는 게 인상적이었다.
|
 |
명예기자 민정우
- 소속 : 서울대학교 전기정보공학부 석박사통합과정
- 연구분야 : 딥러닝 가속기 설계
- 이메일 : jwmin@mics.snu.ac.kr
- 홈페이지 : https://mics.snu.ac.kr
|
| #Power#Transceiver |
|
ᆞSession 5 / Power Management
ᆞSession 15 / Wireline Transceiver Techniques
|
|
본 글은 Session 5에 대한 리뷰이다.
논문을 발표한 국가를 보면 중국이 5개 중 2개를 발표했고, 대만이 5개중 2개, 한국이 5개중 1개를 발표하였다.
Power Management 세션에서 발표된 논문들의 주요 키워드는 Fast load-transient response, Energy harvesting efficiency, 무선 전력 수신이었다. Fast load-transient response 가 [S5-1] [S5-2] [S5-5]의 3개의 논문으로 가장 많았고, Energy harvesting efficiency는 [S5-3], 무선 전력 수신은 [S5-4]의 논문이다.
5개의 논문은 모두 실리콘 칩을 제작했고, 이 칩 들의 측정 결과를 제시했다.
1. [S5-1] 논문의 제목은 “Fast load-transient response을 위해 Buck converter에 Background 보정이 적용된 Transient output-current regulator” 이다. 이 논문은 Buck, converter, DC-DC, fast transient, regulator에 대한 내용이다.
현대의 전자 시스템은 고성능과 절전을 위해 가동 상태와 전원 차단 상태를 번갈아 수행하도록 한다. 이러한 시스템의 Buck 컨버터에는 크고 빠른 부하 전류가 필요하기 때문에 과도현상이 발생한다. 하지만 기존의 Buck 컨버터는 Output Current가 Load Current를 신속하게 추격할 수 없고, 그래서 과도 응답 속도가 느리다. 이에 대한 해결책으로, 이 논문에서는 Transient output-current regulator(TOCR)를 제안했다는 점이 의미가 있다.
2. [S5-2] 논문의 제목은 “X-Connected flying capacitors가 연결된 2-phase 3-level Buck DC-DC 컨버터”이다. 이 논문은 Buck converter, cross-connected, current balancing, DC-DC converter, two-phase three-level converter에 대한 내용이다.
기본적으로 Envelop tracking and point-of-load 어플리케이션에는 작고 빠른 DC-DC buck 변환기가 필요하다. 속도를 향상시키기 위해 고주파 성분을 가진 전류를 사용해야 하지만 안타깝게도 이는 설계를 매우 복잡하게 만든다. 이 논문에서는 X-connected flying capacitors (X-CFLY)가 장착된 2P3L Buck 변환기를 제안한다. 이 구조는 추가적인 구성 요소를 사용하지 않는다는 점에서 장점을 가진다.
3. [S5-3] 논문의 제목은 “실내 경량전지의 용량성 전력변환기에 관한 연구”이다. 이 논문은 Energy harvesting, Internet of Things (IoT), reconfigurable charge pump, redistributable capacitive power converter에 대한 내용이다. harvesting 기술 중, 광전(PV) 셀은 효율성과 보편적 가용성 때문에 널리 사용되고 있다. 하지만 PV셀의 출력 전압은 0.45 ~ 0.7V 근방이며, 이는 IoT 장치에서mW 단위의 전류를 공급하기에는 모자라다. 따라서 짧은 시간 동안 출력 전력을 제공하면서 PV 전압을 변환할 수 있는 인터페이스가 필요하다. 그래서 이 논문에서는 two-stage charge pump와 storge capacitor를 사용하여 mW 단위의 전류를 공급하는 방법을 제안했다. 측정 결과로는 On-chip capacitor가 46.7% 감소했으며 전력 변환 효율이 타 논문과 비교하여 1.5배임을 나타낸다.
4. [S5-4] 논문의 제목은 “멀티유닛 삽입형 장치의 무선전력 수신 및 분배를 위한 Input-Adaptive and Regulated 장치”이다. 이 논문은 switched-capacitor DC-DC converter, wide input voltage range, small output ripple, multi outputs, load selection, reconfigurable conversion ratio 에 대한 내용이다.
IMD(Implantable Medical Devices)가 작아질수록 안정적인 전원을 공급하는 것은 어렵다. 배터리는 제한된 용량과 교체의 어려움 때문에 적합하지 않다. 무선 전력 전송은 이를 해결하지만 LDO(Low Drop Output)와 Switching Regulator의 한계를 극복해야 사용 가능하다. 이 논문에서는 IMD에 무선으로 Input-Adaptive 하여 power management가 가능하게 만들었다.
5. [S5-5] 논문의 제목은 “Hysteretic Control 및 전류파 변조를 갖는 6.78 MHz Single-Stage 정류기”이다. 이 논문은 Hysteretic control, current-wave modulation, regulating rectifier, load-transient response, wireless power transfer (WPT)에 관한 논문이다.
기존에 사용되던 wireless power receiver의 경우 두 개의 power stage로 구성이 되어있다. 하지만 두 번째 stage는 효율을 떨어뜨리고 추가적인 off-chip component들이 필요하다는 단점이 있다. 따라서, single-stage로 rectifier을 구성하면 wireless power receiver의 효율을 개선하고 chip area와 추가적인 off-chip component들을 줄일 수 있다. 하지만 이러한 구조는 PWM(Pulse-Width Modulation)을 사용하기 때문에 load-transient response가 좋지 않다. 이 논문에서는 이러한 단점을 극복하기 위하여 CWM(Current-Wave Modulation)을 사용한 one-cycle-based hysteretic regulation rectifier을 제시하였고 이를 통하여 load-transient response의 개선, output voltage ripple의 감소와 smooth power distribution을 이뤄냈다.
본 글은 Session 15에 대한 리뷰이다.
총 4개의 논문이 이번 session에서 소개가 되었다. 대한민국이 3개의 논문을 발표하며 가장 큰 비율을 차지 하였고[S15-1, S15-2, S15-3], 나머지 1개는 대만에서 발표하였다[S15-4]
4개의 논문 모두 CMOS 공정에서 칩으로 제작되었고 그 중 3개는 28-nm 공정에서[S15-1, S15-2, S15-4], 1개는 110-nm 공정에서 제작되었다[S15-3].
이번 Wireline Transceiver Techniques session의 큰 trend는 5G mobile communication의 발전과 수요 증가에 따른, 5G 속도에 최적화된 Link/Interface 설계였다.
소개된 4편의 논문을 주제별로 살펴본다면, [S15-1]에서는 Referenceless Single-Loop CDR, [S15-2]에서는 Referenceless Digital-CDR, [S15-3]에서는 Fractional-N PLL, [S15-4]에서는 PAM-4 Transmitter을 각각 주제로 하고 있다. 이 4편의 논문 중에서도 성균관대학교에서 발표된 2편의 논문[S15-1, S15-2]이 CDR(Clock and Data Recovery)을 주제로 하였고, 이번 session에서 주목할만한 점이라고 할 수 있다.
제목 : A 6.4–11 Gb/s Wide-Range Referenceless Single-Loop CDR With Adaptive JTOL
CDR(Clock and Data Recovery)는 input data rate을 찾는 frequency-tracking과 recovered clock과 input data 간의 timing margin을 극대화시키는 phase-tracking 2가지 동작을 수행해야 한다. 보편적으로 이용되는 dual-loop CDR의 경우 위의 2가지 동작을 각각의 loop이 수행한다. 논문에서는 이 중 frequency-tracking loop을 뺀 single-loop CDR을 제시하여 같은 동작을 수행하면서도 비교적 작은 면적과 간단한 loop control을 필요로 하는 구조를 제시하였다. 또한, referenceless single-loop CDR의 경우 frequency-tracking과 phase-tracking의 trade-off 관계가 있다. 논문에서는 2가지 동작 사이의 개입을 최소화하여 fast locking과 high jitter tolerance를 구현하고자 각각 Dynamic Band-Width Control(DBWC)과 Adaptive Loop Gain Control(ALGC) technique을 사용하였다. 결과적으로, DBWC technique을 통해 frequency-acquisition time이 약 30% 감소되었다.
제목 : A Jitter-Tolerant Referenceless Digital-CDR for Cellular Transceivers
논문에서는 cellular transceiver을 위한 half-rate jitter-tolerant referenceless digital CDR(Clock and Data Recovery)를 제시하고 있다. 5G Mobile communication이 발전함에 따라 기존 analog interface 대신 high-speed serial interface technique들이 cellular transceiver에 사용되어야 한다. 먼저, MODEM, RFIC, MMIC에서 각각 원하는 performance를 얻기 위해서는 서로 다른 공정에서 구현되어야하기 때문에, 어느 공정에서나 쉽게 적용될 수 있는 D-CDR이 선택되었다. 또한, mobile device에서 가장 중요하게 여겨지는 power, area efficiency를 개선하고 board-level design complexity를 줄이기 위하여 half-rate clocking과 referenceless scheme을 사용하였다. 하지만 DQFD(Digital Quadricorrelator Frequency Detector)의 경우 deadzone이 발생하고 oscillator circuit의 power, area가 증가하기 때문에 논문에서는 4-phase jitter-tolerant frequency detector을 제시하였다. 마지막으로, 기존 D-CDR에서 사용되던 decimator의 경우 decimation 동작을 하는 도중 정보를 잃어버리는 문제점을 가지고 있다. 따라서 이를 개선하기 위하여 multi-bit decimator with a DLF(digital loop filter)가 제시되었다. 구현된 CDR은 1.3pJ/bit의 power efficiency를 가진다.
제목 : A 0.4-1.7GHz Wide Range Fractional-N PLL Using a Transition-Detection DAC for Jitter Reduction
SoC chipset은 다양한 jitter performance를 가지는 여러 PLL(Phase-Locked Loop)을 가진다. 또한, high-speed data converter는 sampling을 위한 low jitter clock signal를 생성해주는 PLL을 필요로 한다. 이러한 상황에서, 최근에는 하나의 PLL이 시스템에 필요한 모든 clock signal을 생성할 수 있도록 회로를 합치려는 노력들이 이루어지고 있다. 하지만, 이런 PLL은 넓은 frequency range, fine frequency resolution, high jitter performance를 요구한다. 이렇게 필요한 성능을 갖추기 위하여 논문에서는 analog fractional-N PLL을 사용하였다. Fractional-N PLL의 경우 integer-N PLL에 비해 frequency resolution이 더 좋고, analog-based PLL은 digital PLL에 비해 jitter 성능이 좋기 때문이다. 이때, fractional-N PLL의 Sigma-delta Modulator(SDM)의 경우 fractional division ratio를 생성하는 dithering을 제공하는데, 이는 quantization error를 만들어 jitter 특성을 나쁘게 한다. 이 문제를 해결하기 위하여 논문에서는 Transition-Detection DAC(TD-DAC)를 제안하였다. 이를 통하여 jitter performance가 32% 향상되었다. 또한, jitter Figure-of-Merit(FoM)의 경우 -215.2dB로 나타났다. 제안된 PLL은 기존 PLL에 비해 압도적인 integrated RMS jitter 성능을 나타내었고, FoM figure 역시 좋았다.
제목 : A 50 Gb/s PAM-4 Transmitter with Feedforward Equalizer and Background Phase Error Calibration
5G, AI 네트워크, 클라우드 서비스 등에 의해 최근 몇 년간 글로벌 IP 트래픽이 급증하고 있다. 그리고 데이터의 대역폭이 계속 증가함에 따라 NRZ(Non Return to Zero) 신호보다는 PAM-4(Pulse Amplitude Modulation) 신호의 사용이 많아지고 있다. 그 중에서도 quarter-rate PAM-4 송신기는 CLK을 분배하는 전력 소비량을 줄여 에너지 효율을 향상시키는 용도로 사용된다. 하지만 이것은 몇 가지 설계 문제를 수반한다. MUX의 input으로 들어오는 CLK의 jitter가 Data Jitter(DJ)를 유발하는 주 원인이라는 것이다. 그래서 본 논문은 언급한 문제를 극복하기 위해 백그라운드에서 작동할 수 있는 DCC(Duty-cycle calibration)와 QEC(Quadrature phase error calibration) 루프가 있는 Quarter rate PAM-4 송신기의 설계에 초점을 맞추고 있다.
|
 |
|
| #AI#Digital |
|
ᆞSession 3 / AI/ML Accelerators on FPGA
ᆞSession 6 / Low-Power Digital Circuits & Systems
|
|
AI/ML Accelerators on FPGA
2012년 AlexNet을 시작으로 특정 분야(이미지 분류)에 대해서 AI가 인간보다 더 잘 할 수 있을지도 모른다는 인식이 점차 확산되었다. 이후 2014년 GoogleNet, 2015년 ResNet 을 거치면서 96.5% 의 인식률을 보이게 되었고, 사람이 이미지를 분류하더라도 95% 수준임을 가만하면 이미지 분류에 있어서는 AI 가 인간을 뛰어 넘었다고 볼 수 있다. 이때까지 AI 에 대한 트랜드는 Hidden Layer 를 얼마나 Deep 하게 하여 인식률을 높이는데에 주안점을 두고 연구가 진행되었다. 하드웨어의 경량화나 에너지 효율보다는 성능 개선을 위주로 연구가 되었으며 상당한 성과를 보였다.
|
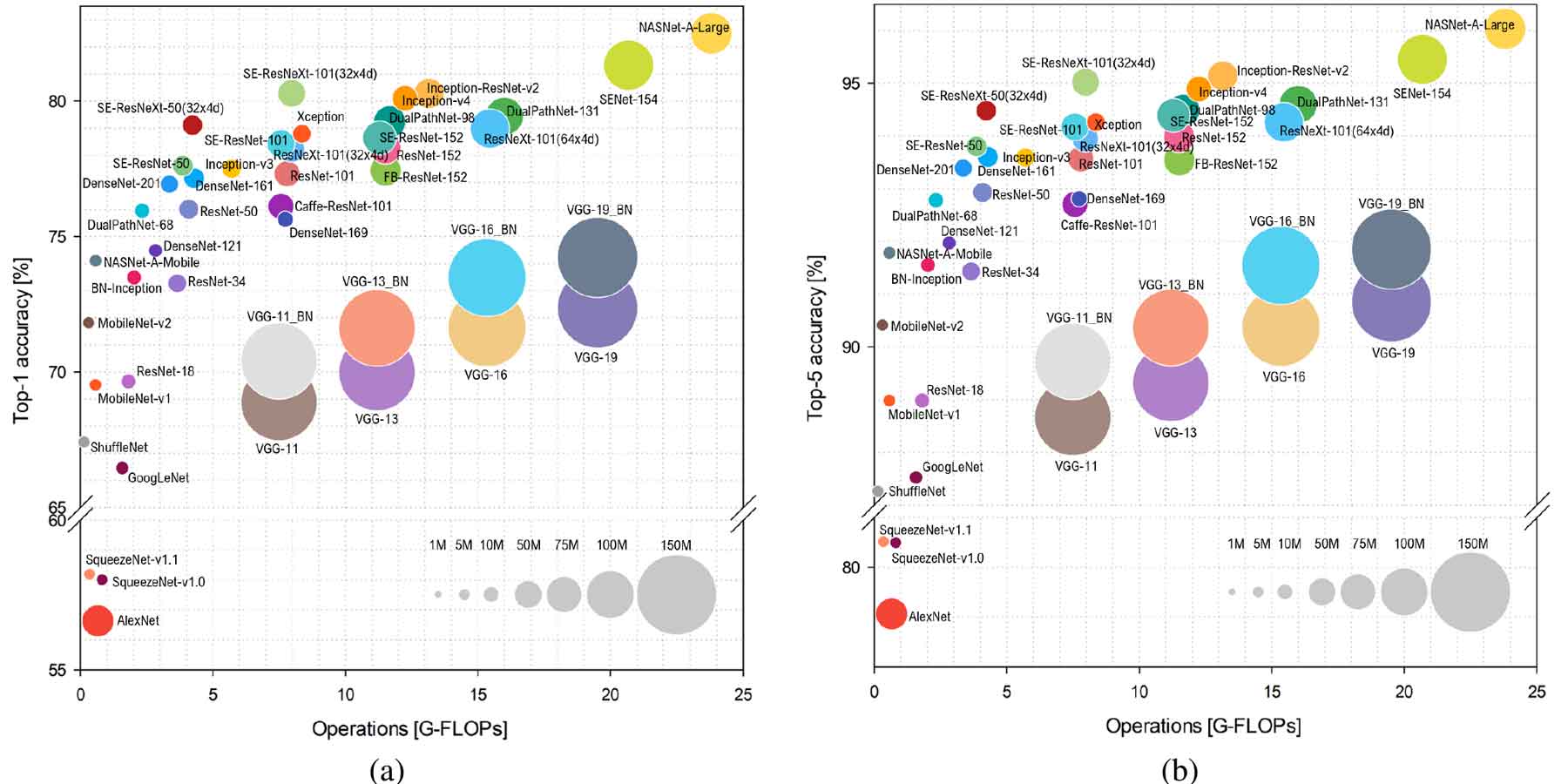 |
| [그림 1] Benchmark Analysis of RepresentativeDeep Neural Network Architectures,” IEEE Access |
|
2014년도 이후에 연구를 보면 인식률을 유지 하면서 모듈을 작게 만들고 에너지 효율을 높이는 방법으로 논문이 발표되고 있다. DianNao(ASPLOS 2014) 에서는 메모리 접근을 효율적으로 하기 위해서 Tiling 개념을 도입하여 전체 이미지중 일부만 가져와서 연산하는 방식으로 효율성을 높였으며 Eyeriss(ISCA 2016, JSSC 2017)는 Data reuse 방식을 적용하여 외부 메모리로 접근을 최소화하는 방식을 사용하였다. 최근에는 Edge device (mobile)에서의 연구가 활발해지고 있으며 하드웨어와 알고리즘을 분리하여 적용하는 것이 아니라 Co-design 하여 성능을 높이려고 하는 추세이다. 경량화를 위해서 대표적으로 사용되는 방식은 1)Pruning 2) Quantization 3)Knowledge Transfer이며 Pruning 은 Fully Connected 된 layer 를 가지치기하여 파라메터를 수를 줄이는 방식으로 신경망의 총 연산량(ex. Floating point operations)을 감소시키므로 연산 속도를 향상시키는 효과가 있다. Quantization 은 신경망 연산에 사용되는 데이터 타입을 간소화(ex. FP32->INT8)하여 메모리 사용량을 줄이는 방식이며 Knowledg Transfer는 이미 학습된 고연산/고메모리 신경망을 저연산/저메모리용 신경망을 학습하기위한 도구로 사용하여 새로운 Light-weight 신경망으로 대체하여 사용하는 기법이다. 여기에 더 해 Retraining에 대한 연구가 같이 진행되고 있으며 올해 ASSCC 2020 AI/ML Accelerators session에서는 각각의 접근 방식은 조금씩 다르지만 여전히 이미지 처리에 대한 부분을 중심으로 연구가 이루어 지고 있다는 점과 메모리 접근에 대한 리소스를 줄이기 위한 연구가 이어지고 있다는 것이 공통점이다. Session 3-1. An Energy-Efficient GAN Accelerator with On-chip Trainning for Domain Specific Optimization 논문을 보면 이러한 최신 경향을 잘 반영하고 있는 것으로 보인다.
|
 |
| [그림 2] . (a) Conventional external data transaction at the FP, EP stage (b) Proposed method (ROLIN) for reducing external memory access at the FP, EP stage |
|
GAN을 사용하는 과정에서 사전 훈련된 모델이 사용자 조건에서 왜곡된 이미지를 출력하기 때문에 사용자에 따른 데이터로 GAN을 재 교육 하는 것이 모바일 장치에서 중요한 요소가 되므로, 본 논문에서는 사용자의 로컬 데이터를 사용하여 Retraining 을 진행하고 해당 출력의 품질을 효과적으로 향상시키는 방안에 대해서 소개하고 있다. 로컬 데이터에 대한 처리는 SELRET(Selective-Layer Retraining)방식을 사용하고 외부 메모리에 대한 접근을 줄이기 위해 ROLIN(Reodering Layers for Instance Normalization) 기법을 사용하고 있다. 해당 기법을 통해 workload 는 69% 감소하였고 Error Map EMA 를 45% 감소시키는 결과를 얻었다.
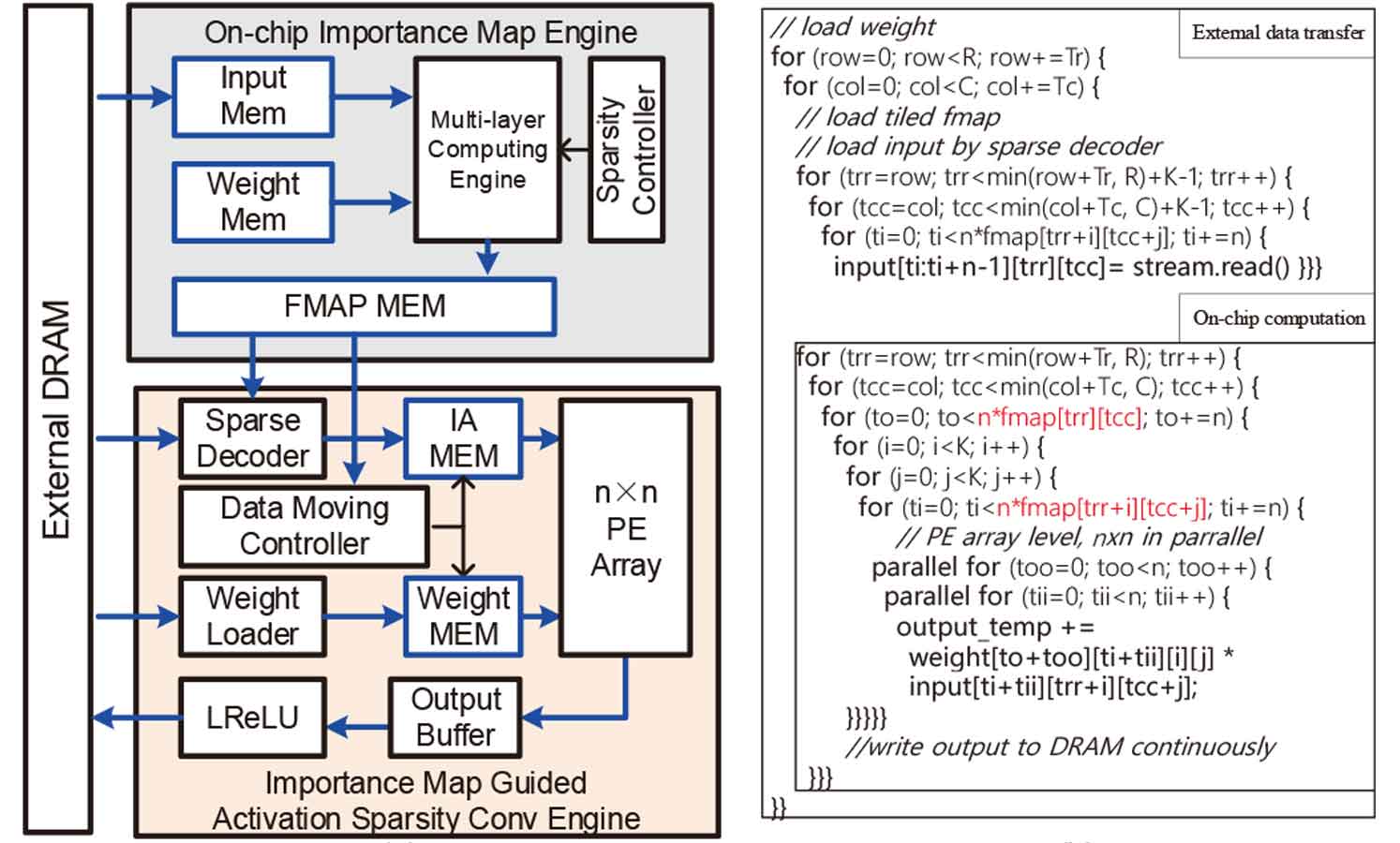
Session 3-2. A 112-765 GOPS/W FPGA-based CNN Accelertor using Importance Map Guided Adaptive Activation Sparsificatoin for Pix2Pix Application 논문 역시 메모리 접근과 MAC 연산에 대한 효율성 증가를 목표로 연구가 되었다. pix2pix는 Image-toImage Translation with Conditional Adversarial Networks 를 의미하는 것으로 입력 이미지를 다른 도메인의 출력 이미지로 대응시켜 주는 것을 주요 동작으로 한다. 또한 보통 여러가지 동작을 위해서는 다른 신경망을 사용해야 하는데 pix2pix는 하나의 모듈로 여러 동작에 대한 학습이 가능하도록 하는 것이 특징이다. 본 논문은 pix2pix 작업을 위한 CNN(Convolutional Neural Networks)을 가속화하기 위한 알고리즘 및 하드웨어 설계방법론을 제안하고 있다. SR-ResNet Model을 통해 메모리접근과 MAC 연산에서 효율성이 향상되었으며 이전 FPGA 기반 작업과 비교하여 5.28배 나은 최고 765 GOPS/W 효율을 보이고 있다. 기존 방식과 마친가지로 메모리 엑세스 작업의 수를 줄이고 효율적인 Mapping 과정을 통해 연산을 최소화하는 것을 중점적으로 접근하였다.
|
 |
| [그림 3] Important map guided activation-sparse CNN accelerator architecture |
|
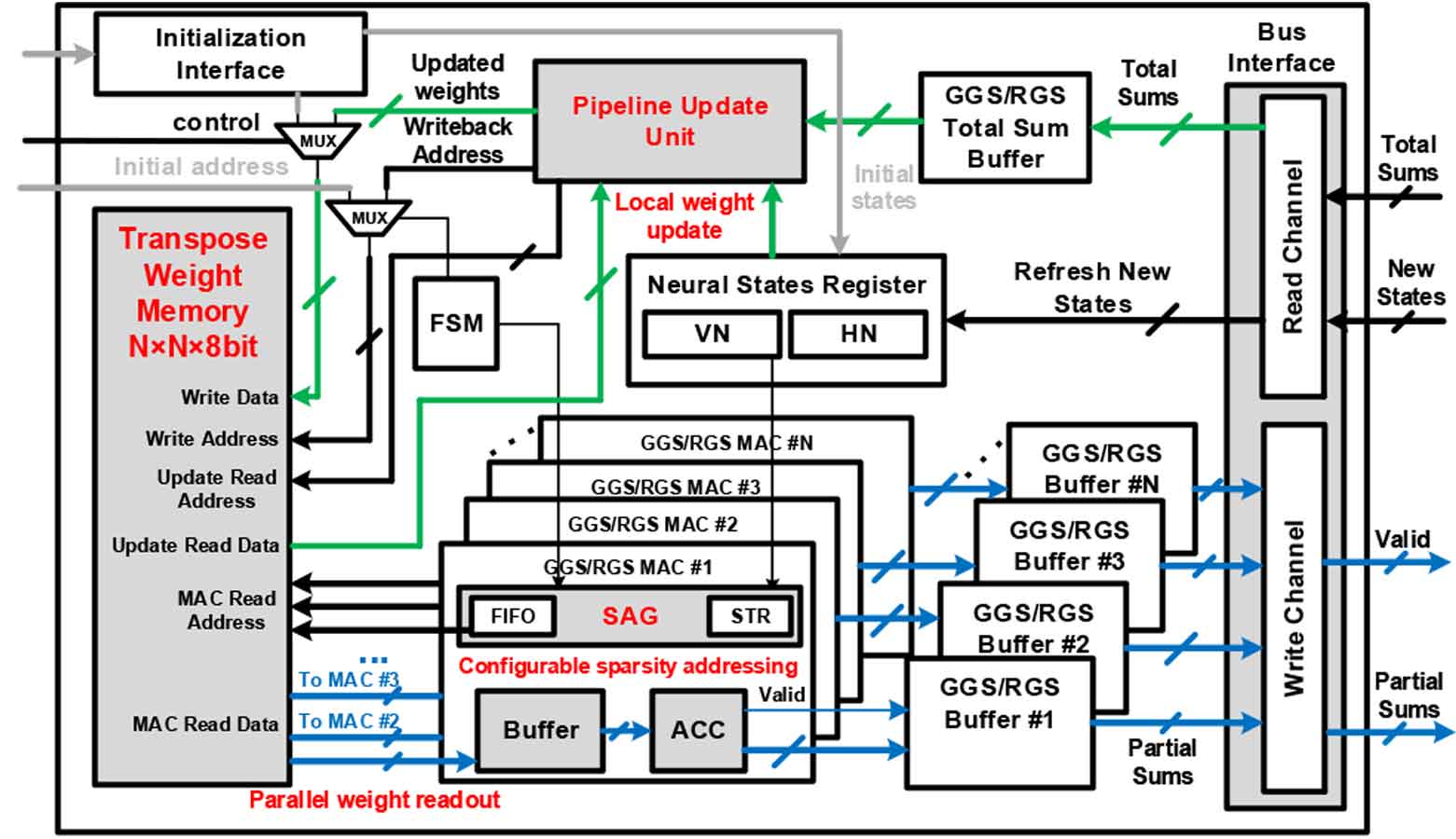
Session 3-3. An Energy-efficient Multi-core Restricted Boltzmann Machine Processor with On-chip Bio-plausible Learning and Recongigurable Sparsity 논문은 첫번째 논문과 마찬가지로 엣지 디바이스에서 동작과 재학습을 하는 것을 타겟으로 연구되었다. 차이점은 GAN 이 아닌 RBM(Boltzmann Machine Processor)를 사용한다는 것과 멀티코어로 구성한다는 점이다. 이전 RBM 설계 방식은 모델의 매캐변수를 업데이트 하기 위해 여러 계산 및 메모리 집약적 샘플링 단계를 거쳐야 했으나 해당 논문에서는 매개 변수 업데이트를 위해서 1단계의 GS 단계만 사용한다.
|
 |
| [그림 4] Architecture and data path of proposed RBM core |
|
성능 테스트를 위해 MNIST 이미지를 사용하였으며 이미지에 무작위로 노이즈를 삽입한뒤 해당 모델이 얼마나 이를 개선시키는지 점검하였다. 이를 위해 128Mhz에서 동작하는 FPGA 보드를 활용하였으며 FPGA 와의 비교가 아닌 AISC으로 연구된 기존 연구와 비교하였는데 동일 조건상에서 비교군이 없다는 것이 조금 아쉬운 부분이다. 기본 대비 44%의 연산 효율성이 향상되었고 24.3% 처리 속도가 개선되었다.
|
|
AI/ML Accelerators 에 대한 트랜드 및 하드웨어 설계 부분은 IDEC 동영상 강좌(무료) “머신러닝을 위한 하드웨어 가속/김주영교수(KAIST)” 에 잘 소개 되어 있으며 해당 분야에 관심이 있는 분들에게 많은 도움이 될 것으로 생각됩니다.
|
|
Low-Power Digital Circuit & Systems
저전력 설계 이슈는 예전부터 많은 연구가 진행되었던 분야이지만 최근 모바일 AP의 성능이 급속도로 향상됨에 따라 더욱 많은 전원을 사용하게 되었으며 이에 따라 저전력에 대한 많은 연구가 진행되었다. 전력에 소비를 가장 획기적으로 줄이는 방법은 동작 전원을 낮추는 것인데 동작 전원을 낮추게 되면 동작 속도가 감소하기 때문에 시스템의 전체 성능에 영향을 줄 수밖에 없다. 또한 동작 전압의 경우 ASIC 공정의 영향을 많이 받게 되므로 공정이 결정이 되면 선택할 수 있는 방법이 많지 않다. 대표적인 방법으로는 Low power cell을 별도로 제작하여 도메인을 분리 한 뒤 동작 특성에 맞게 구분하는 것이 있으며 Clock gating을 통해 Frontend 과정에서 설계에 반영하거나 Power gating 기법을 통해서 동작을 하지 않는 모듈은 전원을 차단하여 Cell 자체의 누설 전류를 방지하는 기법을 사용하기도 한다. Near-Threshold Voltage(NTV)에 대한 연구도 여전히 매력적인 분야로 2012년에 인텔에서 발표한 IA Processor는 당시 많은 주목을 받으며 NTV 회로에 대한 기대감이 높아졌다. 최근 발표되는 논문들을 보면 특정 상황(Application)에서 효율적으로 동작하는 방향으로 연구되거나 전력 소비가 많은 메모리등을 커스텀화 하고 이를 제어하는 방법에 중점을 두고 연구되고 있다. Session 6-1. Time-Domain Computing-In-Memory based Processor using Predictable Decomposed Convolution for Arbitrary Quantized DNNs. 논문에서는 Computing-In-Memory(CIM)은 딥 뉴럴 네트워크를 가속화하기 위한 주요 아키텍처로 이를 활용하여 Multi-bit DNN을 Accelerate 하는 것을 목표도 한다. 다양한 DNN에 대한 Convolution 계산을 가속화하기 위해 UWKDC(Unique Weight Kernel Decomposition based Convoltion Computation method)를 제안하고 있다. 그런 다음 메모리 엑세스를 줄이가 위한 CFFKD, 중복계산을 제거하는 DMCPP, 양자화 에너지와 오류를 줄이기 위한 AWAPQ의 세가지 기술을 사용하여 설계하였으며 28nm 공정에서 제작된 칩은 62.1 TOPS/W 에너지 효율을 보였다.
|
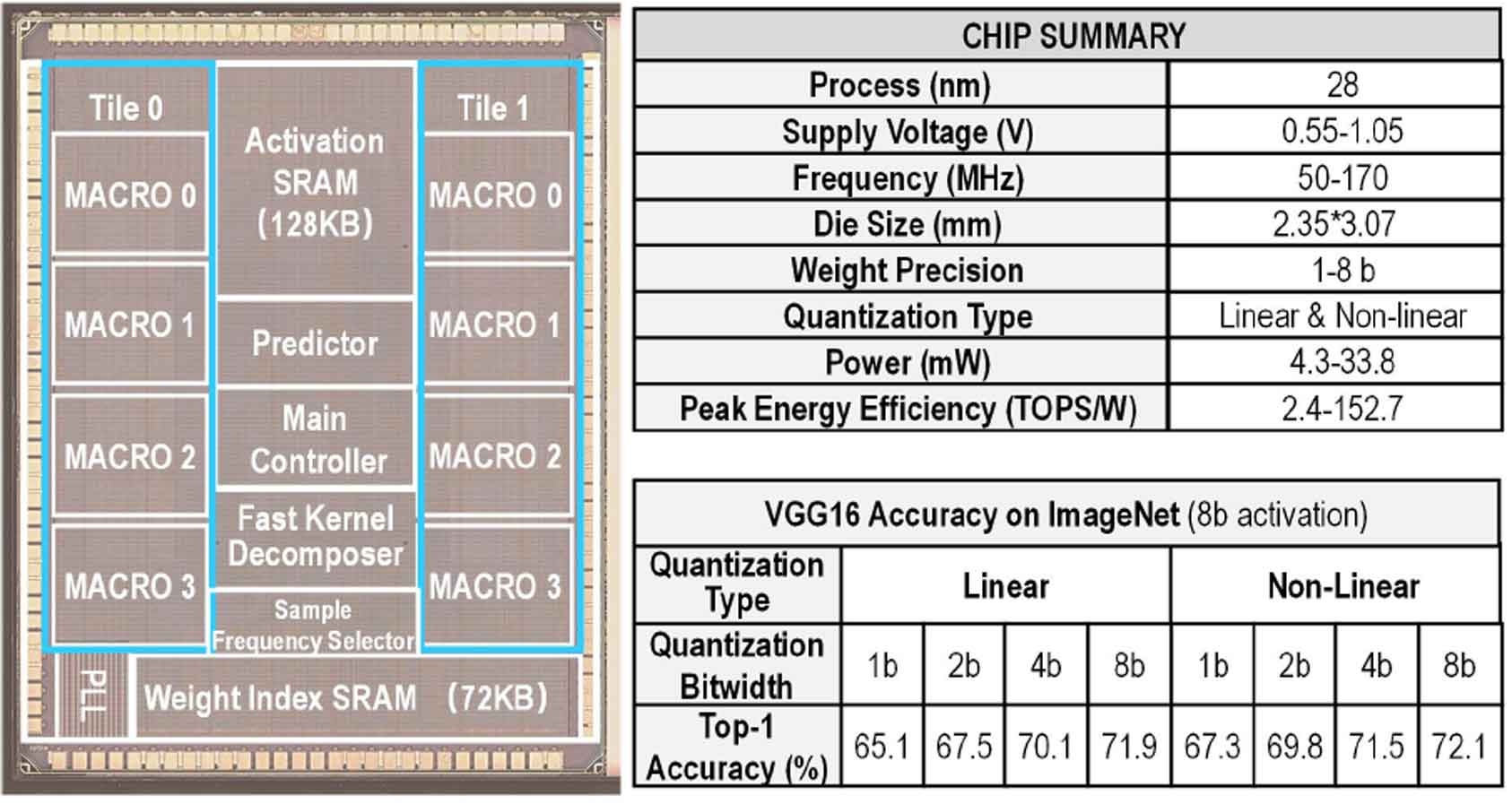 |
| [그림 5] Chip photography and specification” IEEE Access |
|
Low-Power Digital Circuit & Systems
Session 6-2. A Redundancy Eliminated Flip-Flop in 28nm for Low-Voltage Low-Power Applications
NTV(Near-Theshold Voltage) 컴퓨팅은 에너지 효율에 대한 매력적인 패러다임으로 부상했지만 variation이 증가함에 따라 기능적 결함을 야기시키게 된다. 본 논문에서는 Redundancy eliminated flip-flop(REFF)는 redundant clock trainsition을 제거하여 다이나믹 파워소비를 줄일 수 있음을 소개 하고 있다.
|
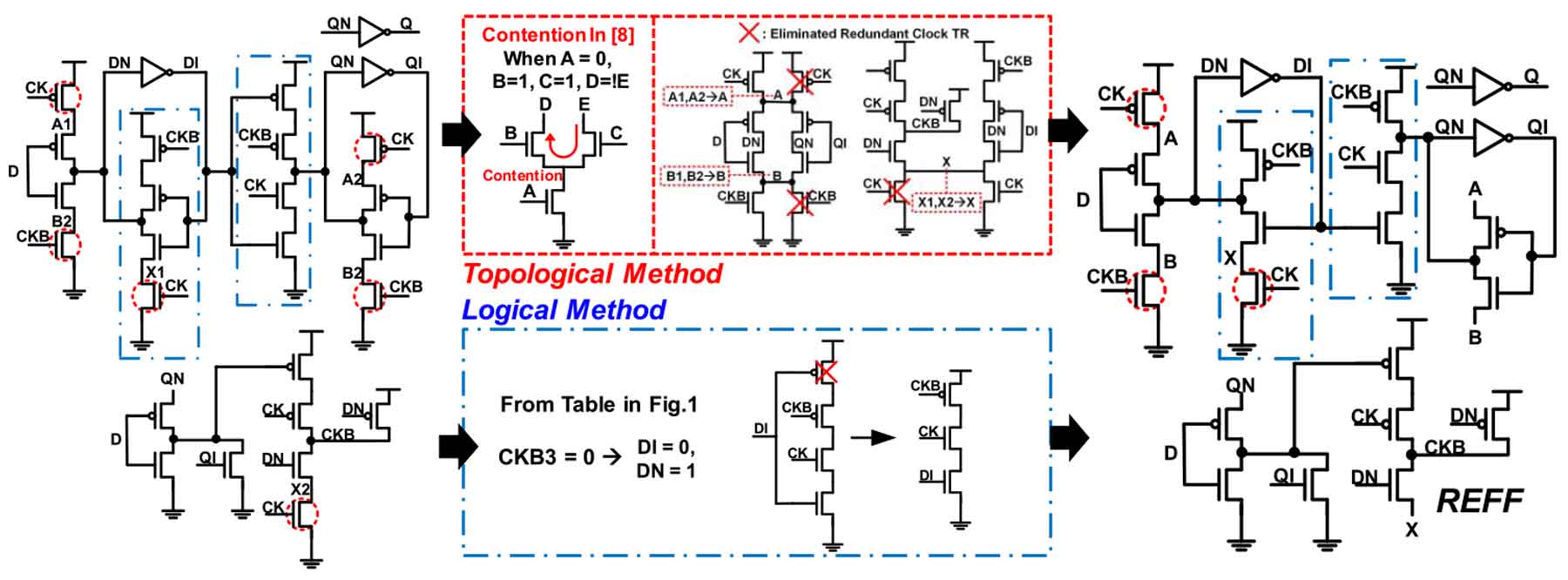 |
| [그림 6] Redundant trainsistor elimination in REFF |
|
REFF는 static and contention- free 동작을 보여주고 있으며 측정된 값을 보면 TGFF에 비해 69.7%의 클럭 전력 감소 효과가 있는 것으로 나타난다. 해당 구조를 통해 상당한 전력 감소 및 전압확장성을 기대할 수 있으며 저전력 소형 센서 시스템에서 좋은 솔루션을 제공할 것으로 기대된다.
Session 6-3. Voice Activity Detection with >83% Accuracy unser SNR down to -3dB a 1.19uW and 0.07mm2 in 40nm 음성을 인식하기 위해서는 저전력 상태로 상항 켜져 있어야하며 음성이 들어왔을 때 이를 인식하고 분석할 수 있어야 한다. 노이즈와 음성을 판별할 수 있어야 하며 음절 누락을 방지하기 위해 대기 시간을 100ms 미만으로 유지해야 한다. 본 논문에서는 광범위한 사용 상황에서 안정적인 작동을 위해 SNR이 최저 -3dB인 소음 환경에서 >83%의 정확도를 제공하기 위해 simple decision stump 분류기와 time average를 도입하였다. Session 6-4. A µProcessor Layer for mm-Scale Die-Stacked Sensing Platforms Featuring Ultra-Low Power Sleep Mode at 125°C 본 논문은 고온상태(125°C)에서 메모리 값을 유지할 수 있도록 하고 있다. 이를 위해서 의도적으로 느린 코너로 전환된 USJC 55nm DDC(Deeply Depleted Channel) 기술이 사용되었다. 고온에서의 동작은 센서의 수명을 크게 단축시키게 되므로 이를 위한 방안을 제시하고 있다. 제안된 시스템은 16kB Custom SRAM. 내부 DC-DC 컨버터 및 차지 펌프를 통합하여 고온 환경에서 메모리 값을 유지할 수 있도록 하고 있다.
|
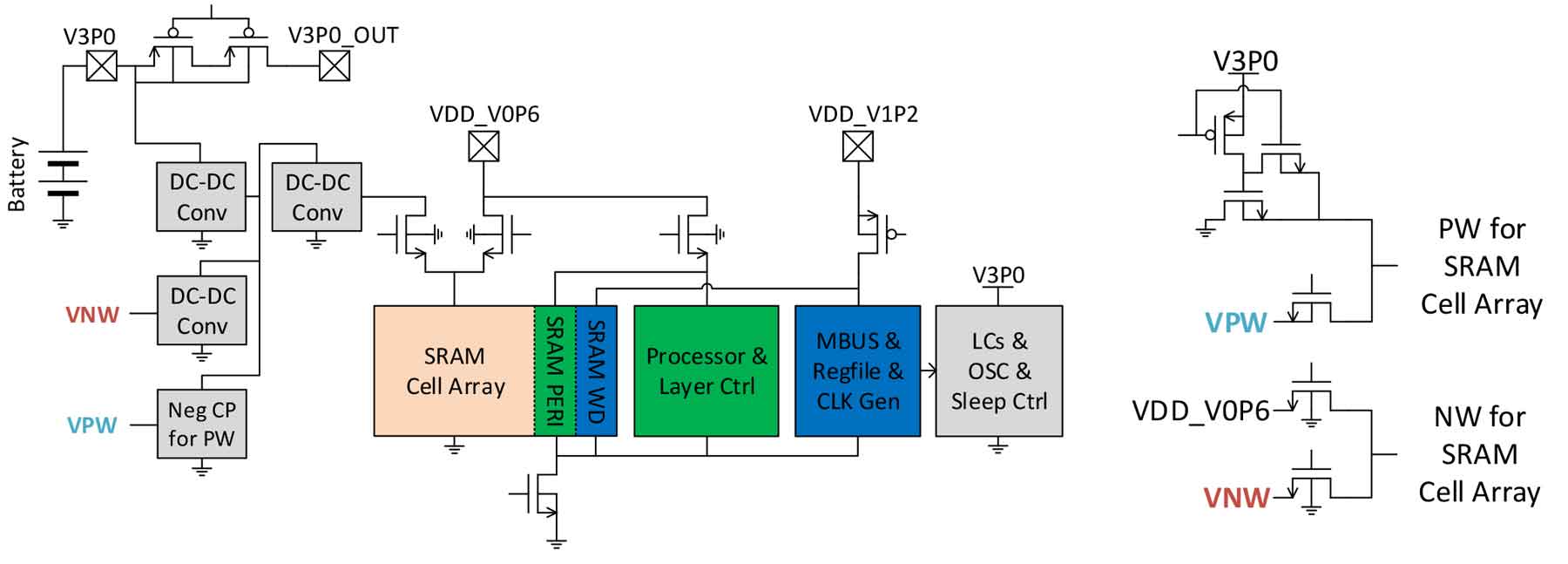 |
| [그림 7] Overall block diagram of the proposed system and Switches for SRAM cell array body biasing |
 |
김연태 선임 연구원
- 소속 : 반도체설계교육센터(IDEC)
- 이메일 : ytkim@idec.or.kr
|
| #RF |
|
ᆞSession 7 / RF & mm-Wave Chip Systems
ᆞSession 11 / RF Building Blocks
|
|
A-SSCC 2020과 RF 분과의 특징은 최소 논문과 중국의 약세로 요약해볼 수 있을 것 같다.
A-SSCC 2020에서는 총 59개의 논문이 발표되면서, 19년에 비해 양적으로 보면 25개가 줄었고 17년도이후 가장 적은 수를 기록했다. (19년 : 84개, 18년 : 86개, 17년 : 83개)
이에 RF 분과로 분류되는 Session도 19년에는 3개였으나 2개(RF & mm-Wave Chip Systems, RF Building Blocks)로 축소되었고, Session별 논문도 각각 5, 4개로 총 9개의 논문들이 발표되었다. (19년 RF 분과 Session 들: RF & mm-Wave Front-End Circuits and Clock Generator (5개), RF, mm-Wave & THz Transmitters and Receivers (6개), Session 20 RF Signal Synthesizers (5개))
RF 분과로 발표된 논문이 10개가 되지 않은 것은 17년이후로는 처음이다. (19년: 16개, 18년: 14개, 17년: 14개)
논문을 발표한 국가를 보면 18~19년에 RF 분과로 발표된 논문의 절반이상을 차지했던 중국은 2개로 대폭 감소했고, 미국이 9개 중 4개로 가장 많은 비율을 차지했고, 한국은 1개를 발표했다. 한국은 17년부터 20년까지 RF 분과에서 1개의 논문만 발표하고 있다.
9개의 논문은 모두 실리콘 칩을 제작했고, 이 칩들의 측정 결과를 제시했다.
세션 별 논문을 살펴보면,
RF & mm-Wave Chip Systems 세션에서 발표된 논문들의 Trend는 저전력 소모, 저 잡음으로 요약할 수 있고, RF 송신기와 수신기에 대한 논문들 5개로 구성이 되었다. W-band 89~93 GHz 용 28nm CMOS 송수신기[S7-1]와 위성 통신용 65nm CMOS 수신기[S7-2], Ka-Band 용 65nm CMOS 수신기[S7-3], 287 GHz 용 65nm CMOS 송수신기[S7-4], IoT 용 55nm CMOS 0.9GHz 송신기[S7-5]에 대해 논문이 발표되었다. 이 중 287 GHz 용 65nm CMOS 송수신기 논문에서는 300GHz 근처에서 작동하는 온칩 안테나가있는 최초의 어레이 기술을 발표하였다.
RF Building Blocks 세션에서 발표된 논문들의 Trend는 저전력 소모와 특성 향상을 위한 새로운 구조의 제안으로 요약할 수 있고, RF Block 4개의 논문으로 구성되었다. LC oscillator-based reference oversampling(OSPLL) 28nm CMOS PLL[S11-1]과 Full-Duplex 무선 시스템용 65nm CMOS Power Amplifier(PA)[S11-2], 96~134 GHz 용 28nm CMOS Frequency Doubler[S11-3], 66 GHz용 65nm CMOS Active Circulator[S11-4]가 발표되었다. 이 중 Full-Duplex 무선 시스템용 65nm CMOS Power Amplifier 논문에서는 PA를 디지털로 구현하였고, 66 GHz용 65nm CMOS Active Circulator 논문에서는 60 GHz Circulator 중 최저 전력 소비를 내세우고 있다.
|
 |
조인신 책임 연구원
- 소속 : 반도체설계교육센터(IDEC)
- 이메일 : ischo@idec.or.kr
|
| #AIoT#Emerging |
|
ᆞSession 12 / Circuits and Systems for Emerging Applications
ᆞSession 14 / SoC for AIoT
|
|
본 글은 2020 년 A-SSCC 의 Emerging 분야인 Session 12와 SoC & Signal Processing System 분야인 Session 14에 대한 리뷰이다.
Session 12에서는 CMOS Image Sensor에 대한 내용이 눈에 띈다. 카메라 2-D 레벨에서 퀄리티를 높이는 것이 아닌, 먼 거리를 센싱하는 3-D 기술이 처음으로 발표되었다. 그리고 최근 3년간 A-SSCC에서 AI에 대해서는 FPGA에서 구현된 논문들만 나왔었는데, 2020년 Session14에서 칩으로 구현된 논문이 나왔다는 것이 특징이다.
주제별로 살펴보면, Emerge 분야에서는 3-D CMOS ToF Sensor, current readout Circuit based ADC, Optical Bandpass Receiver 등의 주제가 나왔고, SoC for AIoT 세션에서는 Secure 분야에서 TRNG와 그것을 이용한 Cryptographic Core 에 대한 논문이 나왔다. AI 관련해서는 Compressed Neural Network과 Neuromorphic Processor을 소개하는 논문이 나왔다.
우선 Emerge 분야에서 CMOS 공정을 활용하여 만든 3D ToF sensor에 대한 논문부터 살펴보자.
A 40-m Range 90-frames/s CMOS Time-of-Flight Sensor Using SPAD and In-Pixel Time-Gated Pulse Counter
최근 3년간 A-SSCC 논문에서는 Biomedical 분야에서 활용되는 이미지의 퀄리티를 높이기 위한 기술들이 나왔었는데 2020년에는 멀리 떨어져 있는 물체를 인식하는 아이디어가 논문으로 나왔다. Time-of-Flight라는 이름의 TOF는 Indirect ToF(i-ToF)와 Direct ToF 방식이 있다고 한다. i-ToF 방식은 성능이 좋고 구현하기도 용이하지만 센싱 거리가 10m 정도로 짧다는 것이 문제인데, 반대로 Direct ToF는 이론적으로 100m을 센싱할 수 있지만 단점이 매우 많아서 도입하기 어렵다. 해당 논문은 위의 2가지 방식을 융합한 SPAD-based i-ToF sensor를 제안하고 있는데, 디지털 카운터를 이용한 time-gated photon counting 기법을 사용하고 pixel level의 time-gated photon counting 동작을 통해 scalability를 높였고, high resolution i-ToF 이미지에 적합하게 만들었다고 한다. 우선 이 분야는 최근 2년간에 3개의 논문이 나올 정도로 많은 연구가 진행되고 있는데 측정 결과를 가지고 기존 연구와 비교해보면 가장 눈에 띄는 것은 Frame rate가 90fps이라는 것과 40m를 측정할 수 있다는 것이다. CMOS 칩 구현으로 구현한 이 측정 가능 거리는 기존의 PD 방식의 센서들 보다 9.5배 개선한 것이고 APD/SPAD-based 방식의 기존 연구보다 2배 개선한 것이다. Power consumption 수치를 보면 기존 연구와 비교되지 않을 정도로 뛰어나고 Relative precision은 0.51%로 매우 좋은 결과를 보이고 있어서 이 분야에 있어 최신 기술이 확실하다. 이 논문과 아이디어는 보안, 감시 및 자율 주행의 물체 감지 관련 application에 많이 활용이 될 것으로 보인다. 다만 pixel resolution이 64x64 인 점은 아쉽게 느껴지는데, 추후 연구들로 개선이 될 것으로 기대한다.
A Power-Efficient Current Readout Circuit with VCO-Based 2nd-Order CT ΔΣ ADC for Electrochemistry Acquisition
Current sensing 테크닉은 저전력이 중요한 최근 트랜드에 꼭 필요한 주제이다. 센싱만 잘 된다면 그것을 이용하여 Power manage Unit도 만들 수 있고, 저전력으로 동작할 수 있는 어떠한 모듈도 만들 수 있기 때문이다. 본 논문에서는 current-sensing voltage-controlled oscillator(VCO) based ADC를 구현하여 소개하고 있다. Electrochemical Sensing System은 integration 하기 좋고 detection을 빨리 할 수 있어서 센서 애플리케이션에 적용하기 좋다는 것인데, 전통적인 방식의 Trans-impedance amplifier(TIA) 은 공정을 이용한 회로 구현에는 좋지만 power 와 noise 측면에서 좋지 않아서 제안한 논문이라고 한다. 이와 비교할 수 있는 논문들을 보면 2019년까지 2년마다 한번씩 나온 것으로 보이는데, Current to Frequency 방식의 논문도 나와 있지만 주로 Voltage to frequency 방식의 VCO-based conversion 방식들을 사용하고 있었다. 제안된 디자인은 VCO-based conversion 방식을 채용했고 여러 필터를 포함하는 디지털 회로를 연결하여 칩으로 구현했다. Input range를 accuracy로 나누어 계산한 결과인 Dynamic Range는 73dB가 나왔고, Power Efficiency는 0.73인데 Oversampling Ratio가 매우 작은 64에서의 결과라는 점에서 기존의 논문들과 비교했을 때 매우 경쟁력이 있다.
2020년 A-SSCC의 SoC for AIoT 세션은 TRNG을 다루는 논문과 AI 분야에서 Neural Network 과 Neuromophic processor 를 각각 다루는 논문들이 발표되었다. 2020년에는 AI 분야의 논문들이 칩으로 구현한 결과를 담았다는 것이 특징이다.
Fully Synthesizable All-Digital Unified Dynamic Entropy Generation, Extraction, and Utilization Within the Same Cryptographic Core
True random number generators (TRNGs)는 secure system에서는 중요한 컴포넌트이다. low cost와 low power가 요구되는 device들은 area, energy/bit, design effort 측면에서 좋은 성능이 요구되는데 이런 요구들은 TRNG에 더 많은 관심을 갖게 했던 것 같다. 그 동안의 TRNG는 엔트로피를 이루는 raw entropy generation circuitry와 post-processing 유닛, 그리고 cryptographic core 를 모두 각각 따로 separate 하는 형태여서 physical attack을 막는데 좋지 않았고 자원의 sharing 측면에서도 좋지 않았다. 그래서 해당 논문은 fully synthesizable all-digital TRNG architecture 를 소개하는데, 위에 있는 모든 것을 integration 한 구조를 보여준다.
특징은 아래로 정리할 수 있겠다.
- generate endogenous randomness
- extract entropy simultaneously
- utilize the same core and are
이 논문에서 제안하는 것은 SIMON cryptographic core를 내장한 architecture로서, Pulse-latch clocking을 base로 한 entropy architecture이다. 논문 내내 타이밍 이슈가 없도록 Pulse width를 잘 조절해야 한다는 점을 많이 강조하고 있다. 이 분야는 비교할 수 있는 논문들이 2016, 2017, 2018, 2019년에 걸쳐 계속 나오고 있다. 이 논문에서 제안한 시스템은 Calibration을 하지 않는 all digital이기 때문에 synthesizable 하고 TRNG + crypto 를 합쳐 0.43(106 · F2)으로 매우 작게 구현할 수 있었다는 점이 특징이다. NIST 800-90B IID test 를 통과했으며 에너지 효율을 보면 전체 모드를 통틀어 0.25-2.5 pJ/bit 으로 나오고 있어서 매우 경쟁력이 있는 논문으로 판단된다. 또한, Max throughput(Mbps)가 128이라고 하는데 초미세공정에서 이 디자인을 구현한다면 더 높은throughput을 기대할 수 있겠다.
Session 14 – SoC for AIoT 에 AI 분야의 논문은 2개가 실렸다.
14-2. CompAcc: Efficient Hardware Realization for Processing Compressed Neural Networks Using Accumulator Arrays
말 그대로 Neural Network의 압축(CNN)에 관한 것이다. 모바일 및 에지 장치에서 고성능 컴퓨팅은 심층 신경의 채택으로 더욱 많이 적용되고 있다. 이제는 음성 인식 및 비디오 classification, 얼굴 감지 등 많은 애플리케이션에 deep neural network가 사용되고 있다. 구현 측면에서는 weight parameter를 저장하기 위해 메모리가 필수적인데 Deep compression 같은 compression 기술과 trained ternary quantization등의 압축 기술을 통해 더 적은 bit를 사용하여 인코딩할 수 있었다. 이 분야의 앞서 나온 논문들은 weight sharing을 사용하는 architecture 를 제안했는데, 이 논문은 compressed network을 효율적으로 연산하는 accumulator array들을 이용한 scalable architecture 를 제안하고 있다. MAC unit를 accumulator array로 대체하되 accumulator 마다 고유의 weight를 갖도록 하고, partial sum과 partial product를 가지고 계산하는 연산방법을 통해 결과적으로 전통적인 방식의 MAC 연산보다 적은 비트를 갖고 계산할 수 있다고 한다. 칩으로 구현한 시스템은 RISC-V core와 Accumulator Array와 메모리, Network On Chip (NoC)등으로 구성된 Processing Element(PE) 그리고 Global Buffer 를 포함하고 있다. 좀 더 자세히 보면, Processing Element는 12개가 들어 있고, global buffers는 1 GB단위로 총 2개가 있으며 NoC는 mesh 구조로 서로 연결되어 있다.
Measurement result 섹션은 가장 먼저 40MHz에서 64 input channels에 3x3 kernel로 sweep 한 결과를 보여준다. Uncompressed weight, uncompressed weight 결과를 비교하여 간결하게 보여주고 있다. 또한 Chip Power Breakdown과 PE Power Breakdown을 파이그래프 형태로 보여주어 한눈에 파워 소모가 가장 많은 곳이 어디인지, 어디가 Power에 대하여 효율적인지를 알 수 있게 한다. 추가로 보여주는 50MHz ALEXNET BenchMark 결과는 5 개의 convolutional layer 각각의 결과와 전체 결과를 보여준다. 다른 논문과의 비교 테이블에는 2017, 2019, 2020년의 최신 논문들이 리스팅되어 있다. 이 논문은 28nm 공정을 사용해서 굉장히 많은 메모리를 집약했고, 200MHz 주파수에서 파워 소모는 최대 220mW로 타 논문보다 낮은 수치를 보여준다. Bit Precision도 1-16 Bit을 지원하여 Fully variable weight라는 특성을 보이고 있다. 파워, Performance, Efficiency 모든 면에서 우수한 성능을 보여주고 있어서 최신 기술의 기준을 한 단계 높게 만들었다. 논문을 보면 원리 설명이 자세하고, 시스템 구조도 명확하게 보여주고 있으며 측정 결과를 자세하고 투명하게 제시하고 있어서 여러 면에서 좋은 논문이라는 생각이 든다. 관련 분야를 연구하는 사람들에게 추천하고 싶다.
41.3 0.5V 4.8 pJ/SOP 0.93μW Leakage/core Neuromorphic Processor with Asynchronous NoC and Reconfigurable LIF Neuron
인간의 뇌를 모사한 뉴로모픽 컴퓨팅 하드웨어는 low power consumption이라는 특징이 있어서 edge computing application에 적합하다. 뉴로모픽 컴퓨팅(NC) 하드웨어는 event-driven이고 병렬적인 spiking 활동을 통해 뉴론들 사이에서 정보를 주고받는다. 이 분야에서는 IBM의 True North를 먼저 떠올릴 수 있겠다. 큰 스케일의 General Purposed NC hardware로서, single package 에 4096개의 neurosynaptic core를 담으면서도 low power라는 특징이 있다. 그 이후로 뉴로모픽 컴퓨팅 분야는 scalability, power consumption, energy efficiency를 개선하기 위해 많은 연구들이 진행되었지만 2018년까지 나온 논문들 중 Loihi는 128개의 클러스터를 사용했고, SpiNNaker는 ARM CPU를 18개를 넣는 방식으로 설계하여 area를 크게 희생하는 경향이 있었다. 당연하겠지만 앞으로의 multi-core NC 디자인은 작게 만들면서도 scalability와 area efficiency, energy efficiency 를 보장해야만 한다. 또한, NC에서는 routing network이 전체 칩에서 차지하는 면적이 매우 크기 때문에 NC hardware router의 high throughput, low power consumption도 신경 써야만 한다.
이 논문에서는 Novena라는 프로세서를 소개하는데 2D 구조의 neurocore들이 fabric bridge spike router 를 통해 연결되어 있다. Neurocore는 CPU와 AXI4 암바 버스, SRAM, USB, Ethernet 컨트롤러를 포함하고 있고 외부와 통신하는 연결 브릿지 등으로 구성되어 있다. 프로세서의 하드웨어와 더불어 소프트웨어 기반 시뮬레이터 & mapper를 제작하여 cycle-accurate level simulation과 full hardware information capture에 활용할 수 있다. 또한, 회로 디자인 관점에서는 아래와 같은 특징이 있다.
- Fabric router microarchitecture
- Neurocore
- LIF spiking neuron
우선, Fabric router는 여러 링크 인터페이스를 갖고 있고, round-robin arbitration방식으로서 handshaking 프로토콜을 이용하고 있다. 특이하게도 Router와 Router 간의 통신은 asynch 방식으로 구현하여 디자인은 견고하게 만들고 power consumption을 줄였다고 하는데, Fabric router의 성능과 에너지 efficiency에 대한 측정 결과를 보면 1V, 1GHz에서 0.6pJ/spike 라는 좋은 결과가 나오고 있으니 관심이 있는 설계자들은 눈여겨봐도 좋을 아이디어로 보인다. 두 번째로 Neurocore는 SRAM-based synaptic crossbar와 Network Interface(NI), Input scheduling unit, Neuron Computing Module, Look up table 등으로 이루어진다. Area breakdown 결과가 나와 있는데, 전체 칩 0.3mm2 중에서 Neurocore의 핵심인 synaptic memory array가 68% 정도를 차지한다고 한다. 세 번째로 LIF spiking neuron인데, 기존의 LIF 뉴런은 1개의 leak profile을 지원했지만 이 논문에서 제안하는 LIF 뉴런은 3개의 다른 leak profile을 지원하며, leak profile과 leak rate를 configurable하게 만들었다고 한다. Training 측면에서 보면 각 application 마다 각기 다른 leak profile과 leak rate를 필요로 하기 때문인데, 각기 다른 leak profile마다 다른 spiking activity 를 보여주는 결과가 논문에 제시되고 있으니 개발자들은 training을 하기에 가장 적당한 leak profile을 고르면 된다고 한다.
본 논문에서 제안하는 Novena 칩은 8 bit synaptic weight 128x128 cross-bar array를 갖고 있는 코어를 16개 포함하고 있다. 2017, 2018, 2019년도의 논문들과 비교해보면, 매우 경쟁력 있는 크기인 0.3mm2에 가장 많은 synapse를 집약했으며 MNIST classification accuracy도 가장 높은 97.89%를 보이고 있다. 특이 Energy 효율면에서도 2019년에 발표된 논문 대비 20% 향상되었다는 점이 눈에 띈다. 파워, Performance, Efficiency 모든 면에서 우수한 성능을 보여주고 있어서 최신 기술의 기준을 한 단계 높게 만들었으므로 관련 분야를 연구하는 많은 사람들에게 이 논문을 추천하고 싶다.
|
 |
선혜승 책임 연구원
- 소속 : 반도체설계교육센터(IDEC)
- 이메일 : smkcow@idec.or.kr
|
|
